IKanalyzer分词器分词并且统计词频
<dependency>
<groupId>com.janeluo</groupId>
<artifactId>ikanalyzer</artifactId>
<version>2012_u6</version>
</dependency>
首先引入 ikanalyzer相关jar包
/**
* @Description:
* @Author: lizhang
* @CreateDate: 2018/7/31 22:35
* @UpdateDate: 2018/7/31 22:35
* @Version: 1.0
*/
import org.wltea.analyzer.core.IKSegmenter;
import org.wltea.analyzer.core.Lexeme; import java.io.IOException;
import java.io.StringReader;
import java.util.*; public class Test {
/**
* 对语句进行分词
* @param text 语句
* @return 分词后的集合
* @throws IOException
*/
private static Map segment(String text) throws IOException {
Map<String,Integer> map = new HashMap<String,Integer>();
StringReader re = new StringReader(text);
IKSegmenter ik = new IKSegmenter(re, false);//true 使用smart分词,false使用最小颗粒分词
Lexeme lex; while ((lex = ik.next()) != null) { if(lex.getLexemeText().length()>1){ if(map.containsKey(lex.getLexemeText())){ map.put(lex.getLexemeText(),map.get(lex.getLexemeText())+1); }else{ map.put(lex.getLexemeText(),1); } } } return map; } public static void main(String[] args) throws IOException { Map<String,Integer> map = segment("中国,中国,我爱你"); System.out.println(map.toString()); } }
输出结果:
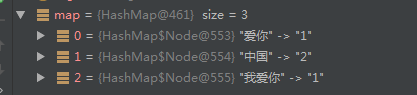
分词Utl:

IKanalyzer分词器分词并且统计词频的更多相关文章
- Atitit..状态机与词法分析 通用分词器 分词引擎的设计与实现 attilax总结
Atitit..状态机与词法分析 通用分词器 分词引擎的设计与实现 attilax总结 1. 状态机 理论参考1 2. 词法分析理论1 3. 词法分析实例2 4. ---code fsm 状态机通用 ...
- Atitit. camel分词器 分词引擎 camel拆分 的实现设计
Atitit. camel分词器 分词引擎 camel拆分 的实现设计 1. camel分词器1 1.1. 实现的界定符号大写字母小写字母数字1 1.2. 特殊处理 对于JSONObject 多个大写 ...
- 如何使用Pig集成分词器来统计新闻词频?
散仙在上篇文章中,介绍过如何使用Pig来进行词频统计,整个流程呢,也是非常简单,只有短短5行代码搞定,这是由于Pig的内置函数TOKENIZE这个UDF封装了单词分割的核心流程,当然,我们的需求是各种 ...
- 2.IKAnalyzer 中文分词器配置和使用
一.配置 IKAnalyzer 中文分词器配置,简单,超简单. IKAnalyzer 中文分词器下载,注意版本问题,貌似出现向下不兼容的问题,solr的客户端界面Logging会提示错误. 给出我配置 ...
- ElasticSearch最全分词器比较及使用方法
介绍:ElasticSearch 是一个基于 Lucene 的搜索服务器.它提供了一个分布式多用户能力的全文搜索引擎,基于 RESTful web 接口.Elasticsearch 是用 Java 开 ...
- Elastic Search中normalization和分词器
为key_words提供更加完整的倒排索引. 如:时态转化(like | liked),单复数转化(man | men),全写简写(china | cn),同义词(small | little)等. ...
- Apache Lucene(全文检索引擎)—分词器
目录 返回目录:http://www.cnblogs.com/hanyinglong/p/5464604.html 本项目Demo已上传GitHub,欢迎大家fork下载学习:https://gith ...
- Lucene第二篇【抽取工具类、索引库优化、分词器、高亮、摘要、排序、多条件搜索】
对Lucene代码优化 我们再次看回我们上一篇快速入门写过的代码,我来截取一些有代表性的: 以下代码在把数据填充到索引库,和从索引库查询数据的时候,都出现了.是重复代码! Directory dire ...
- Lucene.net(4.8.0) 学习问题记录五: JIEba分词和Lucene的结合,以及对分词器的思考
前言:目前自己在做使用Lucene.net和PanGu分词实现全文检索的工作,不过自己是把别人做好的项目进行迁移.因为项目整体要迁移到ASP.NET Core 2.0版本,而Lucene使用的版本是3 ...
随机推荐
- Spring Security(二十九):9.4.1 ExceptionTranslationFilter
ExceptionTranslationFilter is a Spring Security filter that has responsibility for detecting any Spr ...
- Django学习笔记之表单验证
表单概述 HTML中的表单 单纯从前端的html来说,表单是用来提交数据给服务器的,不管后台的服务器用的是Django还是PHP语言还是其他语言.只要把input标签放在form标签中,然后再添加一个 ...
- Nginx(四)------nginx 负载均衡
在上一篇博客我们介绍了 Nginx 一个很重要的功能——代理,包括正向代理和反向代理.这两个代理的核心区别是:正向代理代理的是客户端,而反向代理代理的是服务器.其中我们又重点介绍了反向代理,以及如何通 ...
- 错误:set Assigning an instance of 'esri.***' which is not a subclass of 'esri.***‘
1. 出现 set Assigning an instance of 'esri.***' which is not a subclass of 'esri.***‘的错误原因 是 因为没有找见 ...
- [Oracle维护工程师手记]一次升级后运行变慢的分析
客户报告,当他从 Oracle 11.1.0.7 ,迁移到云环境,并且升级到12.1.0.2.运行客户的应用程序测试,发现比以前更慢了. 从AWR report 的"Top 10 Foreg ...
- C#模板设计模式使用和学习心得
模板设计模式: 模版方法模式由一个抽象类和一个(或一组)实现类通过继承结构组成,抽象类中的方法分为三种: 抽象方法:父类中只声明但不加以实现,而是定义好规范,然后由它的子类去实现. 模版方法:由抽象类 ...
- java基础-不用ide如何打包
java基础-不用ide如何打包 1. 建立目录 src存放源文件 classes存放编译文件 2. 建立类文件 主类 package test.ant; import test.ant.MyTool ...
- Linux C/C++ 链接选项之静态库--whole-archive,--no-whole-archive和--start-group, --end-group
参照这两篇博客: http://stackoverflow.com/questions/805555/ld-linker-question-the-whole-archive-option http: ...
- 父元素高度设置为min-height,子元素高度设置为100%,但实际上子元素高度你知道是多少吗?
前言 给父元素一个min-height,子元素设置height:100%. 代码 <!DOCTYPE html> <html> <head> <title&g ...
- java进阶学习的一些思路
搞 Java 的年薪 40W 是什么水平? - 乔戈里的回答 - 知乎 https://www.zhihu.com/question/31437847/answer/566852748 在知乎上看了他 ...