笨办法39字典dict
一开始没看明白,直接把句子缩短了,输出结果看字典的用法
stuff = {'name': 'Zed', 'age': 39, 'height': 6 * 12 + 2}
stuff['city'] = "San Francisco"
stuff[1] = "Wow"
stuff[2] = "Neato"
print(stuff)
运行了3次,输出不同结果,就贴两个吧。。

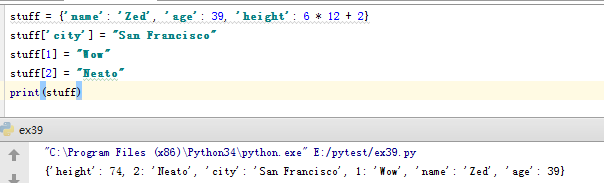
运行结果,键及对应值的顺序都不同。
字典中的值并没有特殊的顺序,但都存储在一个特定的键(Key)里。键可以是数字、字符串甚至是元组。(python基础教程p55)
以下原文代码:
# create a mapping of state to abbreviation
states = {
'Oregon': 'OR',
'Florida': 'FL',
'California': 'CA',
'New York': 'NY',
'Michigan': 'MI'
} # create a basic set of states and some cities in them
cities = {
'CA': 'San Francisco',
'MI': 'Detroit',
'FL': 'Jacksonville'
} # add some more cities
cities['NY'] = 'New York'
cities['OR'] = 'Portland' # print out some cities
print('-' * 10)
print("NY State has: ", cities['NY'])
print("OR State has: ", cities['OR']) # print some states
print('-' * 10)
print("Michigan's abbreviation is: ", states['Michigan'])
print("Florida's abbreviation is: ", states['Florida']) # do it by using the state then cities dict
print('-' * 10)
print("Michigan has: ", cities[states['Michigan']])
print("Florida has: ", cities[states['Florida']]) # print every state abbreviation
print('-' * 10)
for state, abbrev in states.items():
print("%s is abbreviated %s" % (state, abbrev)) # print every city in state
print('-' * 10)
for abbrev, city in cities.items():
print("%s has the city %s" % (abbrev, city)) # now do both at the same time
print('-' * 10)
for state, abbrev in states.items():
print("%s state is abbreviated %s and has city %s" % (
state, abbrev, cities[abbrev])) print('-' * 10)
# safely get a abbreviation by state that might not be there
state = states.get('Texas') if not state:
print("Sorry, no Texas.") # get a city with a default value
city = cities.get('TX', 'Does Not Exist')
print("The city for the state 'TX' is: %s" % city)
基本字典操作:
k in d(d为字典)检查d中是否有含有键为k的项,查找的是键,而不是值(判断是否存在)
a.items:将字典项以列表方式返回,返回时没有特殊顺序(键+值)
a.get(key,default):访问字典中不存在的项时,输出default,存在时,输出对应值
笨办法39字典dict的更多相关文章
- python中的字典(dict),列表(list),元组(tuple)
一,List:列表 python内置的一种数据类型是列表:list.list是一种有序的数据集合,可以随意的添加和删除其中的数据.比如列出班里所有的同学的名字,列出所有工厂员工的工号等都是可以用到列表 ...
- Python 字典dict 集合set
字典dict Python内置字典,通过key-value进行存储,字典是无序的,拓展hash names = ['Michael', 'Bob', 'Tracy'] scores = [95, 75 ...
- sql笨办法同步数据
Helpers.SqlHelper sqlHelper = new Helpers.SqlHelper("server=***;database=Cms;user id=sa;passwor ...
- python中几个常见的黑盒子之“字典dict” 与 “集合set”
这里说到"字典dict" 和 "集合set"类型,首先,先了解一下,对于python来说,标准散列机制是有hash函数提供的,对于调用一个__hash__方法: ...
- Python中的元组(tuple)、列表(list)、字典(dict)
-------------------------------更新中-------------------------------------- 元组(tuple): 元组常用小括号表示,即:(),元 ...
- python中字典dict的操作
字典可存储任意类型的对象,由键和值(key - value)组成.字典也叫关联数组或哈希表. dict = {' , 'C' : [1 , 2 , 3] } dict['A'] = 007 # 修改字 ...
- Python - 字典(dict) 详解 及 代码
字典(dict) 详解 及 代码 本文地址: http://blog.csdn.net/caroline_wendy/article/details/17291329 字典(dict)是表示映射的数据 ...
- Redis的字典(dict)rehash过程源代码解析
Redis的内存存储结构是个大的字典存储,也就是我们通常说的哈希表.Redis小到能够存储几万记录的CACHE,大到能够存储几千万甚至上亿的记录(看内存而定),这充分说明Redis作为缓冲的强大.Re ...
- python基础之字典dict和集合set
作者:tongqingliu 转载请注明出处:http://www.cnblogs.com/liutongqing/p/7043642.html python基础之字典dict和集合set 字典dic ...
随机推荐
- 谷歌浏览器导出excel失败问题解决(网上都没解决)
java poi导出excel报了网络错误,信息已经写回到chrome浏览器(IE/FF均无此问题).如下所示: 从chrome的network大小部分也可以看出是正确的. 网上很多答案说将file. ...
- ubuntu Fcitx 输入法 选择 黑框问题 解决方案
在虚拟机装了个xubuntu,弄好fcitx 输入法后,打字时看不到选择框,被黑框折腾的不行,后来了一个方法,暂时解决了问题. 用 killall fcitx-qimpanel 结束 fcitx-qi ...
- 制作用户登录界面(JAVA实现)
设计实现如图所示的个人信息注册.包含单选按钮.多选按钮.下拉框事件. Zuoye类: package example02; import java.awt.event.ActionEvent; imp ...
- [c/c++] programming之路(27)、union共用体
共用体时刻只有一个变量,结构体变量同时并存 一.创建共用体的三种形式 #include<stdio.h> #include<stdlib.h> #include<stri ...
- python文件读书笔记
一.打开文件 1 f=open('text.txt',r) 二.读取文件 print(f.read) 三.关闭文件 f.close() 比较好用的是运用with with open('text.tx ...
- 单元测试系列之八:Sonar 数据库表关系整理一(续)
更多原创测试技术文章同步更新到微信公众号 :三国测,敬请扫码关注个人的微信号,感谢! 简介:Sonar平台是目前较为流行的静态代码扫描平台,为了便于使用以及自己二次开发,有必要对它的数据库结构进行学习 ...
- Bootstrap各种进度条的实例讲解
本章将讲解 Bootstrap 进度条.在本教程中,您将看到如何使用bootstrap教程.重定向或动作状态的进度条. Bootstrap 进度条使用 CSS3 过渡和动画来获得该效果.Interne ...
- js备战春招の四のDOM
通过js查找html元素的三种方法: 1.通过id找到html元素. 2.通过标签名找到html元素. 3.通过类名找到html元素. DOM HTML document.write(); 直接写入h ...
- JS高程13.3事件对象的学习笔记
1.事件流 事件流描述的是页面中元素接收事件的顺序.比如你单击了某个按钮,他们都认为单击事件不仅仅发生在按钮上,换句话说,在单击按钮的同时,你也单击了按钮的容器元素,甚至还单击了整个页面.那么你到底是 ...
- Visual Studio 2019 double clicking project(custom behavior)
Issue