ConcurrentHashMap 与 Hashtable
粘贴复制于:https://blog.csdn.net/lzwglory/article/details/79978788
集合是编程中最常用的数据结构。而谈到并发,几乎总是离不开集合这类高级数据结构的支持。比如两个线程需要同时访问一个中间临界区(Queue),比如常会用缓存作为外部文件的副本(HashMap)。这篇文章主要分析jdk1.5的3种并发集合类型(concurrent,copyonright,queue)中的ConcurrentHashMap,让我们从原理上细致的了解它们,能够让我们在深度项目开发中获益非浅。
| V get(Object key, int hash) { if (count != 0) { // read-volatile HashEntry e = getFirst(hash); while (e != null) { if (e.hash == hash && key.equals(e.key)) { V v = e.value; if (v != null) return v; return readValueUnderLock(e); // recheck } e = e.next; } } return null; } |
| V readValueUnderLock(HashEntry e) { lock(); try { return e.value; } finally { unlock(); } } |
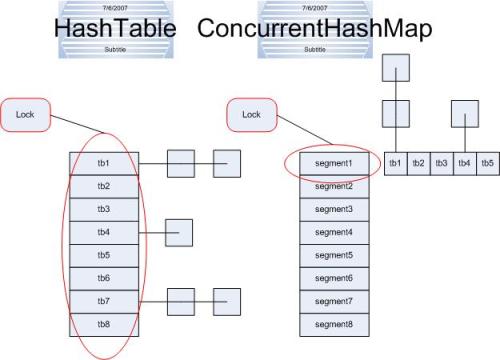
put操作一上来就锁定了整个segment,这当然是为了并发的安全,修改数据是不能并发进行的,必须得有个判断是否超限的语句以确保容量不足时能够rehash,而比较难懂的是这句int index = hash & (tab.length - 1),原来segment里面才是真正的hashtable,即每个segment是一个传统意义上的hashtable,如上图,从两者的结构就可以看出区别,这里就是找出需要的entry在table的哪一个位置,之后得到的entry就是这个链的第一个节点,如果e!=null,说明找到了,这是就要替换节点的值(onlyIfAbsent == false),否则,我们需要new一个entry,它的后继是first,而让tab[index]指向它,什么意思呢?实际上就是将这个新entry插入到链头,剩下的就非常容易理解了。
|
V put(K key, int hash, V value, boolean onlyIfAbsent) { lock(); try { int c = count; if (c++ > threshold) // ensure capacity rehash(); HashEntry[] tab = table; int index = hash & (tab.length - 1); HashEntry first = (HashEntry) tab[index]; HashEntry e = first; while (e != null && (e.hash != hash || !key.equals(e.key))) e = e.next; V oldValue; if (e != null) { oldValue = e.value; if (!onlyIfAbsent) e.value = value; } else { oldValue = null; ++modCount; tab[index] = new HashEntry(key, hash, first, value); count = c; // write-volatile } return oldValue; } finally { unlock(); } } |
remove操作非常类似put,但要注意一点区别,中间那个for循环是做什么用的呢?(*号标记)从代码来看,就是将定位之后的所有entry克隆并拼回前面去,但有必要吗?每次删除一个元素就要将那之前的元素克隆一遍?这点其实是由entry的不变性来决定的,仔细观察entry定义,发现除了value,其他所有属性都是用final来修饰的,这意味着在第一次设置了next域之后便不能再改变它,取而代之的是将它之前的节点全都克隆一次。至于entry为什么要设置为不变性,这跟不变性的访问不需要同步从而节省时间有关,关于不变性的更多内容,请参阅之前的文章《线程高级---线程的一些编程技巧》
|
V remove(Object key, int hash, Object value) { lock(); try { int c = count - 1; HashEntry[] tab = table; int index = hash & (tab.length - 1); HashEntry first = (HashEntry)tab[index]; HashEntry e = first; while (e != null && (e.hash != hash || !key.equals(e.key))) e = e.next; V oldValue = null; if (e != null) { V v = e.value; if (value == null || value.equals(v)) { oldValue = v; // All entries following removed node can stay // in list, but all preceding ones need to be // cloned. ++modCount; HashEntry newFirst = e.next; * for (HashEntry p = first; p != e; p = p.next) * newFirst = new HashEntry(p.key, p.hash, newFirst, p.value); tab[index] = newFirst; count = c; // write-volatile } } return oldValue; } finally { unlock(); } } |
|
static final class HashEntry { final K key; final int hash; volatile V value; final HashEntry next; HashEntry(K key, int hash, HashEntry next, V value) { this.key = key; this.hash = hash; this.next = next; this.value = value; } } |
以上,分析了几个最简单的操作,限于篇幅,这里不再对rehash或iterator等实现进行讨论,有兴趣可以参考src。
ConcurrentHashMap 与 Hashtable的更多相关文章
- ConcurrentHashMap和Hashtable区别
Hashtable:synchronized是针对整张Hash表的,即每次锁住整张表让线程独占安全的背后是巨大的浪费 ConcurrentHashMap和Hashtable主要区别就是围绕着锁的粒度以 ...
- HashMap的扩容机制, ConcurrentHashMap和Hashtable主要区别
源代码查看,有三个常量, static final int DEFAULT_INITIAL_CAPACITY = 16; static final int MAXIMUM_CAPACITY = 1 & ...
- 沉淀再出发:java中的HashMap、ConcurrentHashMap和Hashtable的认识
沉淀再出发:java中的HashMap.ConcurrentHashMap和Hashtable的认识 一.前言 很多知识在学习或者使用了之后总是会忘记的,但是如果把这些只是背后的原理理解了,并且记忆下 ...
- Java基础知识强化之集合框架笔记78:ConcurrentHashMap之 ConcurrentHashMap、Hashtable、HashMap、TreeMap区别
1. Hashtable: (1)是一个包含单向链的二维数组,table数组中是Entry<K,V>存储,entry对象: (2)放入的value不能为空: (3)线程安全的,所有方法均用 ...
- hashmap,ConcurrentHashMap与hashtable的区别
1.hashmap与hashtable的区别 1.我们从他们的定义就可以看出他们的不同,HashTable基于Dictionary类,而HashMap是基于AbstractMap.Dictionary ...
- 源码分析--ConcurrentHashMap与HashTable(JDK1.8)
ConcurrentHashMap和Hashtable都是线程安全的K-V型容器.本篇从源码入手,简要说明它们两者的实现原理和区别. 与HashMap类似,ConcurrentHashMap底层也是以 ...
- ConcurrentHashMap 和 Hashtable 的区别
ConcurrentHashMap 和 Hashtable 的区别主要体现在实现线程安全的方式上不同. 1.底层的数据结构: ConcurrentHashMap 在jdk1.7之前采用的是 分段的数组 ...
- 为什么ConcurrentHashMap,HashTable不支持key,value为null?
ConcurrentHashmap.HashMap和Hashtable都是key-value存储结构,但他们有一个不同点是 ConcurrentHashmap.Hashtable不支持key或者val ...
- ConcurrentHashMap、HashTable、HashMap的区别
HashTable与ConcurrentHashMap: 相同点:都是线程安全的,可以在多线程的环境下运行.key和value都不能为null 区别:性能上的差异.HashTable每次操作对象都会锁 ...
随机推荐
- [Go] golang的竞争状态
1.goroutine在逻辑处理器的线程上进行交换 2.竞争状态:两个或者多个goroutine在没有互相同步的情况下,访问某个共享的资源,并试图同时读和写这个资源,就处于互相竞争的状态对共享资源的读 ...
- Spring boot集成spring session实现session共享
最近使用spring boot开发一个系统,nginx做负载均衡分发请求到多个tomcat,此时访问页面会把请求分发到不同的服务器,session是存在服务器端,如果首次访问被分发到A服务器,那么se ...
- 学JAVA第四天,JAVA获取年月日
先添加引用import java.util.Calendar; 然后编写代码: Calendar calendar = null;//声明 calendar= Calendar.getInstance ...
- Ext.extend
Ext.extend:老版本的定义类,单继承 有两种使用方法,具体见附件中的Extend1.html和Extend2.html 附件如下: Ext.extend.zip
- 把vux中的@font-face为base64格式的字体信息解码成可用的字体文件
在最近移动端项目中用到了vux,感觉用着还习惯,当把vux使用到PC端的时候出现了IE浏览器出现,这样的错误信息: CSS3114: @font-face 未能完成 OpenType 嵌入权限检查.权 ...
- java对接申通下单接口示例代码
上面是控制台示例代码 public class Sample{ private final static String URL = "http://order.sto-express.cn: ...
- Jmeter设置代理,抓包之app请求
步骤: 1. Jmeter选择测试计划,添加线程组,添加http请求,添加监听器-察看结果树 2. 添加http代理服务器,右键添加非测试元件-添加http代理服务器 3. 端口改为8889,目标控制 ...
- spring学习总结——高级装配学习四(运行时:值注入、spring表达式)
前言: 当讨论依赖注入的时候,我们通常所讨论的是将一个bean引用注入到另一个bean的属性或构造器参数中.bean装配的另外一个方面指的是将一个值注入到bean的属性或者构造器参数中.在没有学习使用 ...
- 关于MongoDB时间格式转换和时间段聚合统计的用法总结
一 . 背景需求 在日常的业务需求中,我们往往会根据时间段来统计数据.例如,统计每小时的下单量:每天的库存变化,这类信息数据对运营管理很重要. 这类数据统计依赖于各个时间维度,年月日.时分秒都有可能. ...
- Expression
表达式目录树 1.什么是表达式目录树Expression? 表达式目录树是一个数据结构,语法树. 首先我们去看看 Expressions类 ,定义了一个泛型委托类型 TDelegate: // 摘要: ...