lucene源码分析(5)lucence-group
1. 普通查询的用法
org.apache.lucene.search.IndexSearcher
public void search(Query query, Collector results)
其中
Collector定义
/**
* <p>Expert: Collectors are primarily meant to be used to
* gather raw results from a search, and implement sorting
* or custom result filtering, collation, etc. </p>
*
* <p>Lucene's core collectors are derived from {@link Collector}
* and {@link SimpleCollector}. Likely your application can
* use one of these classes, or subclass {@link TopDocsCollector},
* instead of implementing Collector directly:
*
* <ul>
*
* <li>{@link TopDocsCollector} is an abstract base class
* that assumes you will retrieve the top N docs,
* according to some criteria, after collection is
* done. </li>
*
* <li>{@link TopScoreDocCollector} is a concrete subclass
* {@link TopDocsCollector} and sorts according to score +
* docID. This is used internally by the {@link
* IndexSearcher} search methods that do not take an
* explicit {@link Sort}. It is likely the most frequently
* used collector.</li>
*
* <li>{@link TopFieldCollector} subclasses {@link
* TopDocsCollector} and sorts according to a specified
* {@link Sort} object (sort by field). This is used
* internally by the {@link IndexSearcher} search methods
* that take an explicit {@link Sort}.
*
* <li>{@link TimeLimitingCollector}, which wraps any other
* Collector and aborts the search if it's taken too much
* time.</li>
*
* <li>{@link PositiveScoresOnlyCollector} wraps any other
* Collector and prevents collection of hits whose score
* is <= 0.0</li>
*
* </ul>
*
* @lucene.experimental
*/
Collector的层次结构
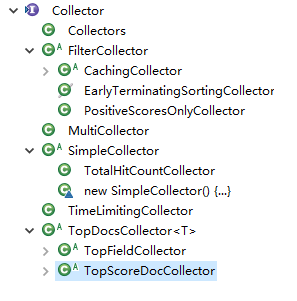
2 lucene-group
提供了分组查询GroupingSearch,对应相应的collector
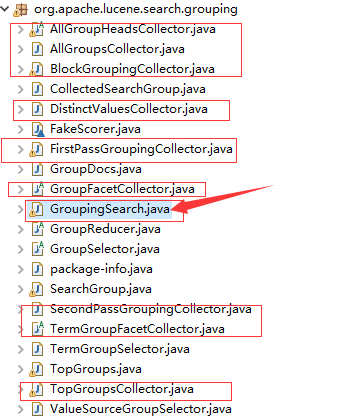
3.实例:
public Map<String, Integer> groupBy(Query query, String field, int topCount) {
Map<String, Integer> map = new HashMap<String, Integer>();
long begin = System.currentTimeMillis();
int topNGroups = topCount;
int groupOffset = 0;
int maxDocsPerGroup = 100;
int withinGroupOffset = 0;
try {
FirstPassGroupingCollector c1 = new FirstPassGroupingCollector(field, Sort.RELEVANCE, topNGroups);
boolean cacheScores = true;
double maxCacheRAMMB = 4.0;
CachingCollector cachedCollector = CachingCollector.create(c1, cacheScores, maxCacheRAMMB);
indexSearcher.search(query, cachedCollector);
Collection<SearchGroup<String>> topGroups = c1.getTopGroups(groupOffset, true);
if (topGroups == null) {
return null;
}
SecondPassGroupingCollector c2 = new SecondPassGroupingCollector(field, topGroups, Sort.RELEVANCE, Sort.RELEVANCE, maxDocsPerGroup, true, true, true);
if (cachedCollector.isCached()) {
// Cache fit within maxCacheRAMMB, so we can replay it:
cachedCollector.replay(c2);
} else {
// Cache was too large; must re-execute query:
indexSearcher.search(query, c2);
}
TopGroups<String> tg = c2.getTopGroups(withinGroupOffset);
GroupDocs<String>[] gds = tg.groups;
for(GroupDocs<String> gd : gds) {
map.put(gd.groupValue, gd.totalHits);
}
} catch (IOException e) {
e.printStackTrace();
}
long end = System.currentTimeMillis();
System.out.println("group by time :" + (end - begin) + "ms");
return map;
}
几个参数说明:
groupField: 分组域groupSort: 分组排序topNGroups: 最大分组数groupOffset: 分组分页用withinGroupSort: 组内结果排序maxDocsPerGroup: 每个分组的最多结果数withinGroupOffset: 组内分页用
参考资料
https://blog.csdn.net/wyyl1/article/details/7388241
lucene源码分析(5)lucence-group的更多相关文章
- Lucene 源码分析之倒排索引(三)
上文找到了 collect(-) 方法,其形参就是匹配的文档 Id,根据代码上下文,其中 doc 是由 iterator.nextDoc() 获得的,那 DefaultBulkScorer.itera ...
- 一个lucene源码分析的博客
ITpub上的一个lucene源码分析的博客,写的比较全面:http://blog.itpub.net/28624388/cid-93356-list-1/
- lucene源码分析的一些资料
针对lucene6.1较新的分析:http://46aae4d1e2371e4aa769798941cef698.devproxy.yunshipei.com/conansonic/article/d ...
- Lucene 源码分析之倒排索引(一)
倒排索引是 Lucene 的核心数据结构,该系列文章将从源码层面(源码版本:Lucene-7.3.0)分析.该系列文章将以如下的思路展开. 什么是倒排索引? 如何定位 Lucene 中的倒排索引? 倒 ...
- lucene源码分析(1)基本要素
1.源码包 core: Lucene core library analyzers-common: Analyzers for indexing content in different langua ...
- Lucene 源码分析之倒排索引(二)
本文以及后面几篇文章将讲解如何定位 Lucene 中的倒排索引.内容很多,唯有静下心才能跟着思路遨游. 我们可以思考一下,哪个步骤与倒排索引有关,很容易想到检索文档一定是要查询倒排列表的,那么就从此处 ...
- lucene源码分析(8)MergeScheduler
1.使用IndexWriter.java mergeScheduler.merge(this, MergeTrigger.EXPLICIT, newMergesFound); 2.定义MergeSch ...
- lucene源码分析(7)Analyzer分析
1.Analyzer的使用 Analyzer使用在IndexWriter的构造方法 /** * Constructs a new IndexWriter per the settings given ...
- lucene源码分析(6)Query分析
查询的入口 /** Lower-level search API. * * <p>{@link LeafCollector#collect(int)} is called for ever ...
随机推荐
- Maven发布和管理项目
1 什么是Maven? 如果没有Maven,你可能不得不经历下面的过程: 1 如果使用了spring,去spring的官网下载jar包:如果使用hibernate,去hibernate的官网下载Jar ...
- CSharp程序员学Android开发---2.个人总结的快捷键
最近公司组织项目组成员开发一个Android项目的Demo,之前没有人有Andoid方面的开发经验,都是开发C#的. 虽说项目要求并不是很高,但是对于没有这方面经验的人来说,第一步是最困难的. 项目历 ...
- 二叉树(Binary Tree)相关算法的实现
写在前面: 二叉树是比较简单的一种数据结构,理解并熟练掌握其相关算法对于复杂数据结构的学习大有裨益 一.二叉树的创建 [不喜欢理论的点我跳过>>] 所谓的创建二叉树,其实就是让计算机去存储 ...
- 解决EF没有生成字段和表说明
找了很多资料,终于找到一篇真正能解决ef生成字段说明,注释的文章,收藏不了,于是转载 本文章为转载,原文地址 项目中使用了EF框架,使用的是Database-First方式,因为数据库已经存在,所以采 ...
- dotNet core 应用部署centos
---恢复内容开始--- 阅读目录 需要安装的插件以及支撑架构 安装dotnetSDK 安装jexus 安装supervisord 遇到问题汇总 注意事项.扩展延伸 需要安装的插件以及支撑架构 1.d ...
- 创建/读取/删除Session对象
//创建Session对象 Session["userName"] = "顾德博";//保存,这里可以存储任意类型的数据,包括对象.集合等 Session.Ti ...
- 使用.NET Core 2.1的Azure WebJobs
WebJobs不是Azure和.NET中的新事物. Visual Studio 2017中甚至还有一个默认的Azure WebJob模板,用于完整的.NET Framework. 但是,Visual ...
- day 60 Django第一天
jinjia2 : Jinja2是基于python的模板引擎,功能比较类似于于PHP的smarty,J2ee的Freemarker和velocity. 它能完全支持unicode,并具有集成的沙箱执行 ...
- flask源码解析之上下文为什么用栈
楔子 我在之前的文章<flask源码解析之上下文>中对flask上下文流程进行了详细的说明,但是在学习的过程中我一直在思考flask上下文中为什么要使用栈完成对请求上下文和应用上下文的入栈 ...
- MongoDB 安装详细教程 + 常用命令 + 与 Python 的交互
MongoDB 简介 MongoDB (名称来自 humongous/巨大无比的, 是一个可扩展的高性能,开源,模式自由,面向文档的NoSQL,基于 分布式 文件存储,由 C++ 语言编写,设计之初旨 ...