hadoop2.x学习笔记(一):YARN
一、YARN产生的背景
MapReduce1.x存在的问题:单点故障&节点压力大不易扩展。
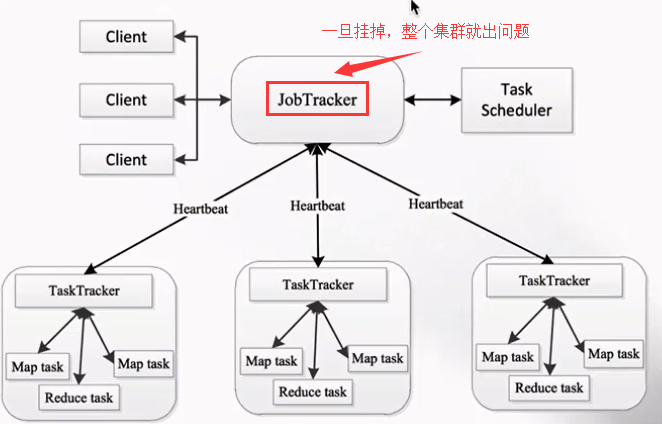
资源利用率&成本
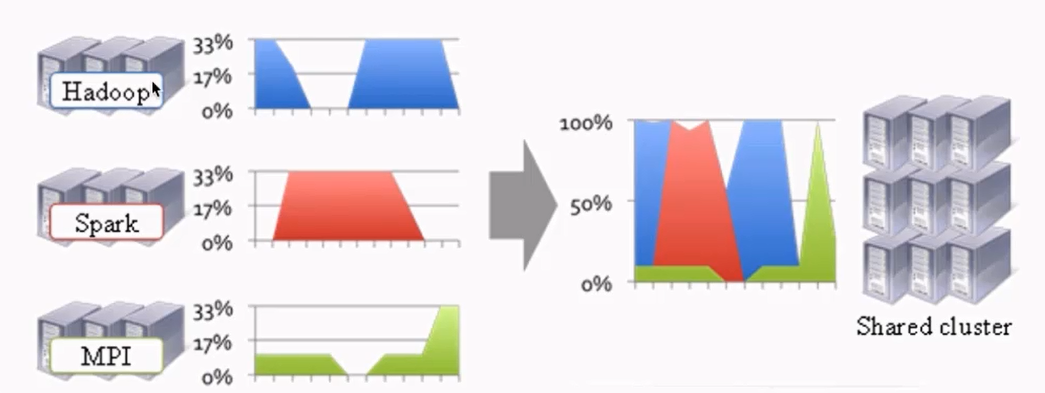
催生了YARN的诞生
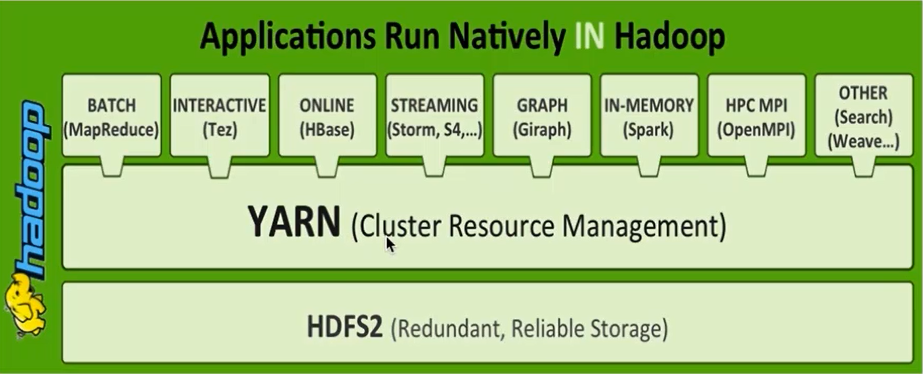
不同计算框架可以共享同一个HDFS集群上的数据,享受整体的资源调度。
XXX on YARN的好处:与其他计算框架共享集群资源,按资源需要分配,进而提高集群资源的利用率。
XXX:Spark/MapReduce/Storm/Flink
二、YARN概述
1 Yet Another Resource Negotiator
2 通用资源管理系统
3 为上层应用提供统一的资源管理和调度
三、YARN的架构
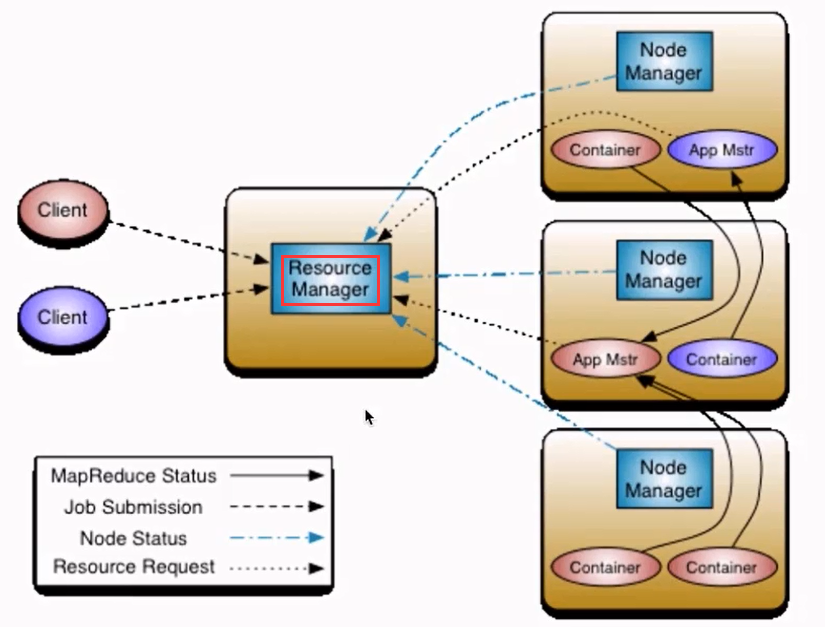
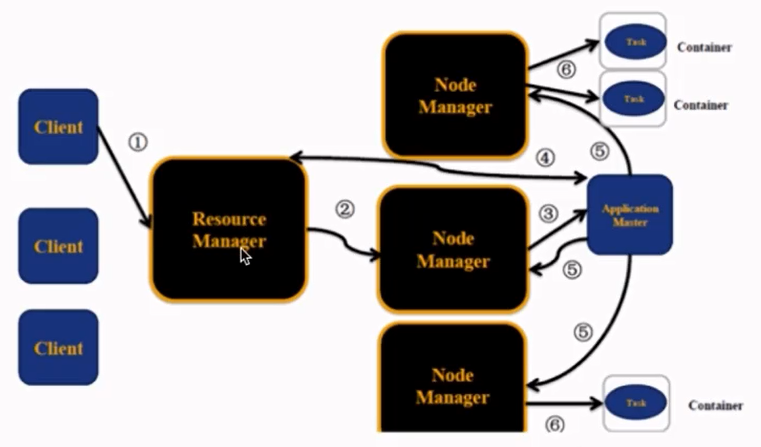
1 ResourceMananger:RM
整个集群提供服务的RM只有一个(生产中有两个,一个主,一个备),负责集群资源的统一管理和调度。
|-- 处理客户端的请求:提交一个作业、杀死一个作业。
|--监控NM,一旦某个NM挂了,那么该NM上运行的任务需要告诉AM如何进行处理。
2 NodeManager:NM
整个集群中有多个,负责自己本身节点资源管理和使用。
|--定时向RM汇报本节点的资源使用情况。
|--接收并处理来自RM的各种命令:启动Container等。
|--处理来自AM的命令。
|--单个节点的资源管理。
3 ApplicationMaster:AM
每一个应用程序对应一个:MR、Spark,负责应用程序的管理。
|--为每个应用程序向RM申请资源(core、memory),分配给内部task。
|--需要与NM通信:启动/停止task,task是运行在Container里面,AM也是运行在Container里面。
4 Container
|--封装了CPU、Memory等资源的一个容器
|--是一个任务运行环境的抽象。
5 Client
|--提交作业。
|--查询作业的运行进度。
|--杀死作业。
四、YARN执行流程
五、YARN的环境搭建
1 yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
2 mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
3 启动YARN相关的进程
sbin/start-yarn.sh
4 验证
|-- jps
|--ResourceManager
|--NodeManager
|-- http://master01:8088/
5 停止YARN相关的进程
sbin/stop-yarn.sh
六、MapReduce作业提交到YARN上运行
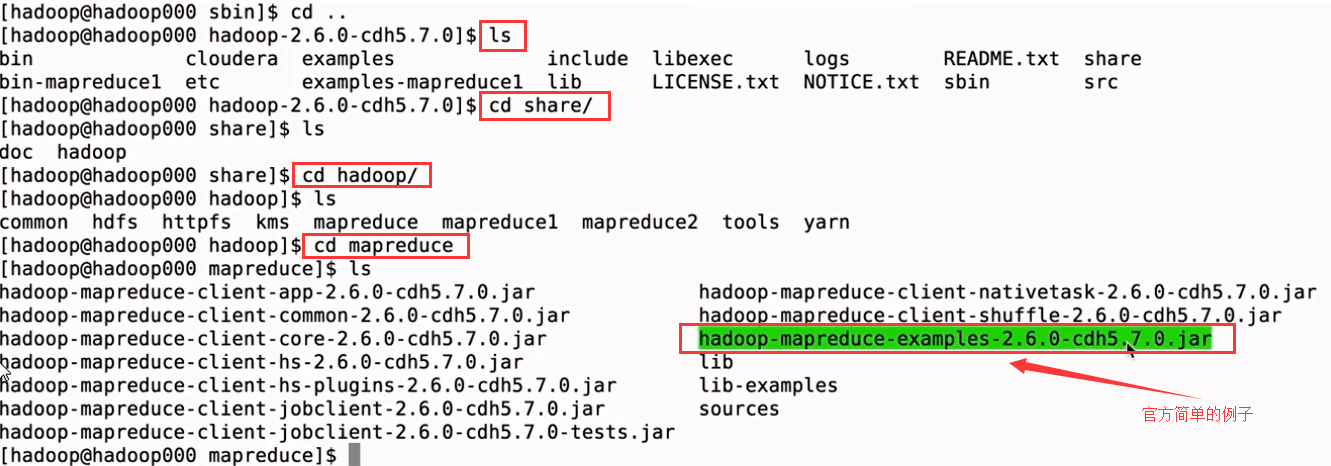
命令:
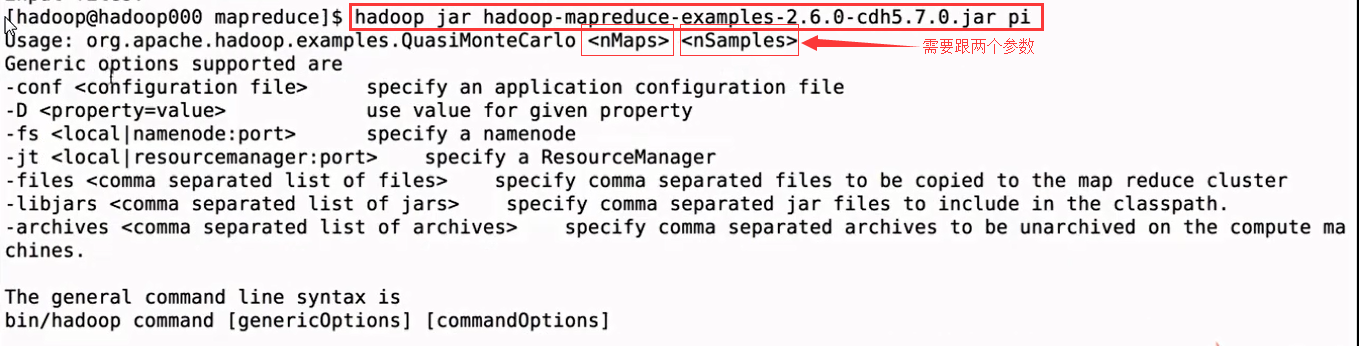
hadoop jar hadoop-mapreduce-examples-2.6.-cdh5.7.0.jar pi 2 3 //前者是Map的数量,后者是取样的数量
hadoop2.x学习笔记(一):YARN的更多相关文章
- 二十六、Hadoop学习笔记————Hadoop Yarn的简介复习
1. 介绍 YARN(Yet Another Resource Negotiator)是一个通用的资源管理平台,可为各类计算框架提供资源的管理和调度. 之前有提到过,Yarn主要是为了减轻Hadoop ...
- Hadoop学习笔记—22.Hadoop2.x环境搭建与配置
自从2015年花了2个多月时间把Hadoop1.x的学习教程学习了一遍,对Hadoop这个神奇的小象有了一个初步的了解,还对每次学习的内容进行了总结,也形成了我的一个博文系列<Hadoop学习笔 ...
- Node.js学习笔记(4):Yarn简明教程
Node.js学习笔记(4):Yarn简明教程. 引入Yarn NPM是常用的包管理工具,现在我们引入是新一代的包管理工具Yarn.其具有快速.安全.可靠的特点. 安装方式 使用npm工具安装yarn ...
- Hadoop学习笔记—21.Hadoop2的改进内容简介
Hadoop2相比较于Hadoop1.x来说,HDFS的架构与MapReduce的都有较大的变化,且速度上和可用性上都有了很大的提高,Hadoop2中有两个重要的变更: (1)HDFS的NameNod ...
- 分布式计算框架学习笔记--hadoop工作原理
(hadoop安装方法:http://blog.csdn.net/wangjia55/article/details/53160679这里不再累述) hadoop是针对大数据设计的一个计算架构.如果你 ...
- Hadoop学习笔记01_Hadoop搭建
想往大数据方向转, 难度肯定是有的. 基础知识肯定是要有的,如果是熟悉JAVA开发的人,转向应该优势大. 像我这样的,只有Linux基础以及简单的PHP基础的人,转向难度很大.但是事在人为,努力学习多 ...
- hadoop之HDFS学习笔记(二)
主要内容:hdfs的核心工作原理:namenode元数据管理机制,checkpoint机制:数据上传下载流程 1.hdfs的核心工作原理 1.1.namenode元数据管理要点 1.什么是元数据? h ...
- HBase学习笔记之HBase的安装和配置
HBase学习笔记之HBase的安装和配置 我是为了调研和验证hbase的bulkload功能,才安装hbase,学习hbase的.为了快速的验证bulkload功能,我安装了一个节点的hadoop集 ...
- 【原】Learning Spark (Python版) 学习笔记(三)----工作原理、调优与Spark SQL
周末的任务是更新Learning Spark系列第三篇,以为自己写不完了,但为了改正拖延症,还是得完成给自己定的任务啊 = =.这三章主要讲Spark的运行过程(本地+集群),性能调优以及Spark ...
随机推荐
- TFS:需要包管理许可证才能进一步操作You need a Package Management license to go further
问题: 为什么团队成员没有查看包管理服务的权限?如下图: 答案: TFS系统的访问级别设置,决定在默认配置中用户是否有包管理的访问权限.默认配置中,只有"VS Enterprise" ...
- Python 数据结构与算法——桶排序
#简单的桶排序 def bucksort(A): bucks = dict() # 定义一个桶变量,类型为字典 for i in A: bucks.setdefault(i,[]) # 每个桶默认为空 ...
- ABP框架入门踩坑-使用MySQL
使用MySQL ABP踩坑记录-目录 起因 因为我自用的服务器只是腾讯云1核1G的学生机,不方便装SQL Server,所以转而MySQL. 这里使用的MySQL版本号为 8.0. 解决方案 删除Qi ...
- Redirect与Transfer 的区别
共同点: 都是重定向: 不同点: redirect: 1发生在客户端: 2.发送两次请求,第一次请求原始页面,当调用此方法时,创建一个应答头,返回状态码302,第二次请求重定向的页面: 3.得不到任何 ...
- clang 编译 OC
clang -fobjc-arc -framework Foundation helloworld.m -o helloworld.out OVERVIEW: clang LLVM compiler ...
- tomcat安装配置常见问题详解
历经波折,终于把tomcat装好了.记录下过程供自己和后来的初学者参考吧! 本文先后介绍了tomcat的下载安装方法.安装和启动不成功的常见原因 以及启动tomcat后如何配置上下文. 一.下载安装 ...
- Maven+SSM框架项目实例——IDEA
一.项目环境 开发系统:Window10 开发工具:IDEA JDK:1.8 框架:Maven+Spring+SpringMVC+Mybatis 数据库:Mysql 二.项目结构 项目文件架构: 三 ...
- 话谈C#第一天
今天是第一次接触C#,由于长时间的做Java开发,突然转到C#非常的不自然,但是也有了一些收获,给大家分享一下 using System; using System.Collections.Gener ...
- java 0 开始
利用了61天的时间学习了 se 不过忘得也很多 .在这里开一个帖子 打算利用几天的时间进行复习,把凡是能用到的都放在这边. 不带图形界面的第一个项目已经弄完 (看视频加看书..而且自己往上面加东 ...
- springMvc的执行流程(源码分析)
1.在springMvc中负责处理请求的类为DispatcherServlet,这个类与我们传统的Servlet是一样的.我们来看看它的继承图 2. 我们发现DispatcherServlet也继承了 ...