K-SVD字典学习及其实现(Python)
算法思想
算法求解思路为交替迭代的进行稀疏编码和字典更新两个步骤. K-SVD在构建字典步骤中,K-SVD不仅仅将原子依次更新,对于原子对应的稀疏矩阵中行向量也依次进行了修正. 不像MOP,K-SVD不需要对矩阵求逆,而是利用SVD数学分析方法得到了一个新的原子和修正的系数向量.
固定系数矩阵X和字典矩阵D,字典的第\(k\)个原子为\(d_k\),同时\(d_k\)对应的稀疏矩阵为\(X\)中的第\(k\)个行向量\(x^k_T\). 假设当前更新进行到原子\(d_k\),样本矩阵和字典逼近的误差为:
\]
在得到当前误差矩阵\(E_k\)后,需要调整\(d_k\)和\(X^k_T\),使其乘积与\(E_k\)的误差尽可能的小.
如果直接对\(d_k\)和\(X^k_T\)进行更新,可能导致\(x^k_T\)不稀疏. 所以可以先把原有向量\(x^k_T\)中零元素去除,保留非零项,构成向量\(x^k_R\),然后从误差矩阵\(E_k\)中取出相应的列向量,构成矩阵\(E^R_k\). 对\(E^R_k\)进行SVD(Singular Value Decomposition)分解,有\(E^R_k = U\Delta V^T\),由\(U\)的第一列更新\(d_k\),由\(V\)的第一列乘以\(\Delta (1,1)\)所得结果更新\(x^k_R\).
Python实现
import numpy as np
from sklearn import linear_model
import scipy.misc
from matplotlib import pyplot as plt
class KSVD(object):
def __init__(self, n_components, max_iter=30, tol=1e-6,
n_nonzero_coefs=None):
"""
稀疏模型Y = DX,Y为样本矩阵,使用KSVD动态更新字典矩阵D和稀疏矩阵X
:param n_components: 字典所含原子个数(字典的列数)
:param max_iter: 最大迭代次数
:param tol: 稀疏表示结果的容差
:param n_nonzero_coefs: 稀疏度
"""
self.dictionary = None
self.sparsecode = None
self.max_iter = max_iter
self.tol = tol
self.n_components = n_components
self.n_nonzero_coefs = n_nonzero_coefs
def _initialize(self, y):
"""
初始化字典矩阵
"""
u, s, v = np.linalg.svd(y)
self.dictionary = u[:, :self.n_components]
def _update_dict(self, y, d, x):
"""
使用KSVD更新字典的过程
"""
for i in range(self.n_components):
index = np.nonzero(x[i, :])[0]
if len(index) == 0:
continue
d[:, i] = 0
r = (y - np.dot(d, x))[:, index]
u, s, v = np.linalg.svd(r, full_matrices=False)
d[:, i] = u[:, 0].T
x[i, index] = s[0] * v[0, :]
return d, x
def fit(self, y):
"""
KSVD迭代过程
"""
self._initialize(y)
for i in range(self.max_iter):
x = linear_model.orthogonal_mp(self.dictionary, y, n_nonzero_coefs=self.n_nonzero_coefs)
e = np.linalg.norm(y - np.dot(self.dictionary, x))
if e < self.tol:
break
self._update_dict(y, self.dictionary, x)
self.sparsecode = linear_model.orthogonal_mp(self.dictionary, y, n_nonzero_coefs=self.n_nonzero_coefs)
return self.dictionary, self.sparsecode
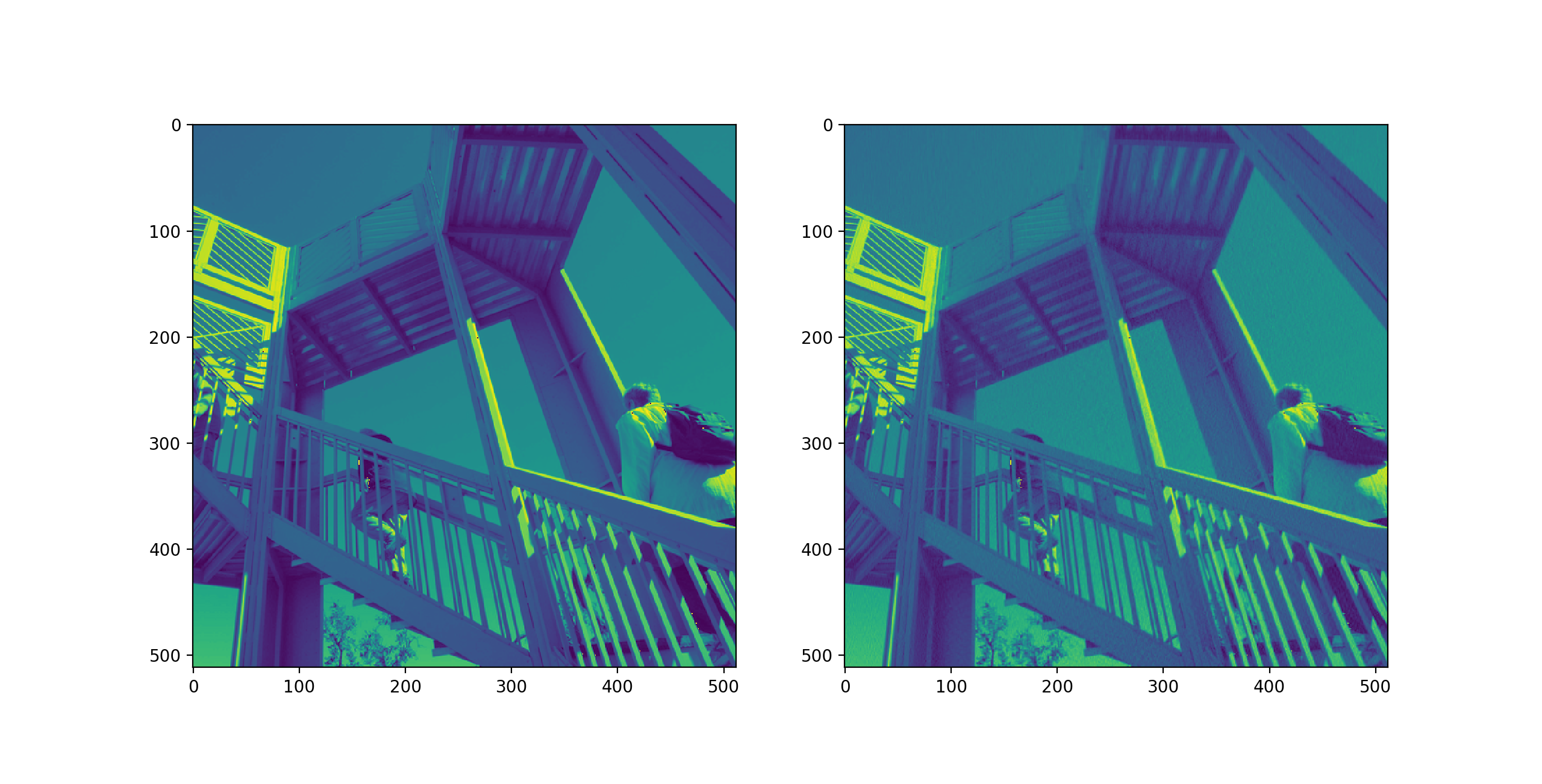
if __name__ == '__main__':
im_ascent = scipy.misc.ascent().astype(np.float)
ksvd = KSVD(300)
dictionary, sparsecode = ksvd.fit(im_ascent)
plt.figure()
plt.subplot(1, 2, 1)
plt.imshow(im_ascent)
plt.subplot(1, 2, 2)
plt.imshow(dictionary.dot(sparsecode))
plt.show()
运行结果:
K-SVD字典学习及其实现(Python)的更多相关文章
- 吴裕雄 python 机器学习——数据预处理字典学习模型
from sklearn.decomposition import DictionaryLearning #数据预处理字典学习DictionaryLearning模型 def test_Diction ...
- 字典学习(Dictionary Learning, KSVD)详解
注:字典学习也是一种数据降维的方法,这里我用到SVD的知识,对SVD不太理解的地方,可以看看这篇博客:<SVD(奇异值分解)小结 >. 1.字典学习思想 字典学习的思想应该源来实际生活中的 ...
- 字典学习(Dictionary Learning)
0 - 背景 0.0 - 为什么需要字典学习? 这里引用这个博客的一段话,我觉得可以很好的解释这个问题. 回答这个问题实际上就是要回答“稀疏字典学习 ”中的字典是怎么来的.做一个比喻,句子是人类社会最 ...
- 学习笔记之Python全栈开发/人工智能公开课_腾讯课堂
Python全栈开发/人工智能公开课_腾讯课堂 https://ke.qq.com/course/190378 https://github.com/haoran119/ke.qq.com.pytho ...
- 稀疏编码(sparse code)与字典学习(dictionary learning)
Dictionary Learning Tools for Matlab. 1. 简介 字典 D∈RN×K(其中 K>N),共有 k 个原子,x∈RN×1 在字典 D 下的表示为 w,则获取较为 ...
- 【学习笔记】PYTHON语言程序设计(北理工 嵩天)
1 Python基本语法元素 1.1 程序设计基本方法 计算机发展历史上最重要的预测法则 摩尔定律:单位面积集成电路上可容纳晶体管数量约2年翻倍 cpu/gpu.内存.硬盘.电子产品价格等都遵 ...
- Dictionary Learning(字典学习、稀疏表示以及其他)
第一部分 字典学习以及稀疏表示的概要 字典学习(Dictionary Learning)和稀疏表示(Sparse Representation)在学术界的正式称谓应该是稀疏字典学习(Sparse Di ...
- Noah的学习笔记之Python篇:函数“可变长参数”
Noah的学习笔记之Python篇: 1.装饰器 2.函数“可变长参数” 3.命令行解析 注:本文全原创,作者:Noah Zhang (http://www.cnblogs.com/noahzn/) ...
- 一个可扩展的深度学习框架的Python实现(仿keras接口)
一个可扩展的深度学习框架的Python实现(仿keras接口) 动机 keras是一种非常优秀的深度学习框架,其具有较好的易用性,可扩展性.keras的接口设计非常优雅,使用起来非常方便.在这里,我将 ...
- python学习第九讲,python中的数据类型,字符串的使用与介绍
目录 python学习第九讲,python中的数据类型,字符串的使用与介绍 一丶字符串 1.字符串的定义 2.字符串的常见操作 3.字符串操作 len count index操作 4.判断空白字符,判 ...
随机推荐
- 【模板】.bat对拍
对拍是个很有用的东西,比如在验证贪心策略是否正确时,可以写上个暴力然后和贪心程序对拍上几个小时. 在c++里用system写对拍总是会出现一些莫名其妙的问题.. 比如my.out明明是1 fc的时候却 ...
- Spring Boot Mock单元测试学习总结
单元测试的方法有很多种,比如使用Postman.SoapUI等工具测试,当然,这里的测试,主要使用的是基于RESTful风格的SpringMVC的测试,我们可以测试完整的Spring MVC流程,即从 ...
- Day10 上传和下载
上传 将本地文件传输到服务器 jsp: 文件上传的请求方式必须是post input的type必须是file enctype="multipart/form-data" ...
- Day3 MySql高级查询
DQL高级查询 多表查询(关联查询.连接查询) 1.笛卡尔积 emp表15条记录,dept表4条记录. 连接查询的笛卡尔积为60条记录. 2.内连接 不区分主从表,与连接顺序无关.两张表均满足条件则出 ...
- virtualbox+vagrant学习-2(command cli)-15-vagrant resume命令
Resume 格式: vagrant resume [vm-name] 这将恢复先前挂起的vagrant托管计算机,可能与suspend命令一起使用. 默认情况下,配置的预配置程序在运行该命令时将不再 ...
- mongodb启动与运用
在操作前需要启动mongodb数据库服务 1.首先打开dos窗口,然后选择路径到你的安装路径下的bin目录(我的路径是的D:mongo\mongodb\bin) 2.然后输入启动命令(D:mongo\ ...
- 列表中不限制宽度,hover时,字体font-weight:bold,防止抖动
项目一个小问题困扰了很久,在一个没有限制宽度的列表容器中,如果给hover时,给字体➕'font-wieght:bold'容器就会变宽,然后移动的下一个容器,就会出现抖动,这样很是影响用户体验,于是在 ...
- Jenkins+github的一次定时构建示例
首先说明,我的电脑环境是windows,所以以下的示例是基于windows10 X64. 一.新建任务,填写名称,选择类型,点击左下角的[确定] 二.配置 1.General 2.源码管理 之前在gi ...
- VMware Tools安装方法及解决无法全屏显示问题
环境:VMware8.0虚拟机 ubuntu:12.04 在刚安装完ubuntu后,屏幕不能全屏显示,此时: 1.安装VMware Tools 步骤: 1.1 进入ubuntu系 ...
- HBase数据存取流程
一.HBase的特点是什么 1.HBase一个分布式的基于列式存储或者行式存储的数据库,基于hadoop的hdfs存储,zookeeper进行管理. 2.HBase适合存储半结构化或非结构化数据,对于 ...