MySQL数据库参数优化
概述
最近在对各个系统的mysql做一些参数上的优化,也开了慢查询,准备后面针对特定sql再进一步优化。下面主要介绍一下一些优化的参数。
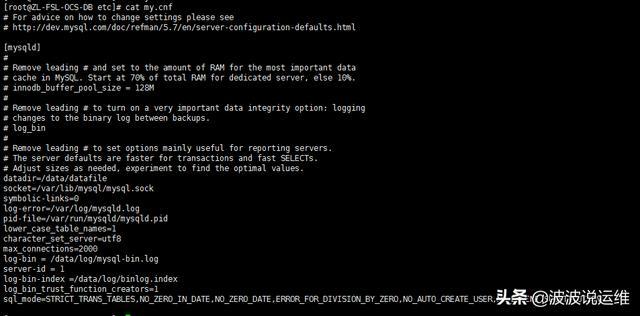
1、优化前mysql配置
可以看到基本上是没怎么做优化的。
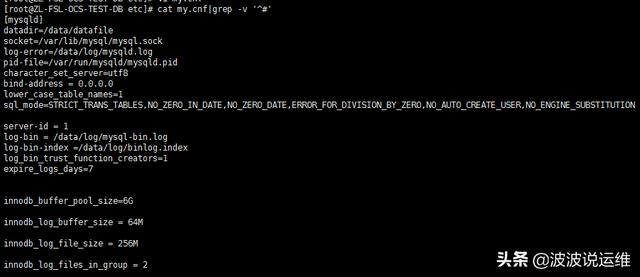
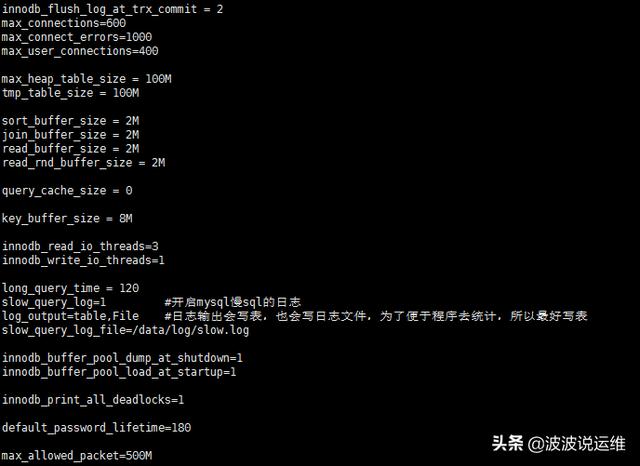
2、优化后的配置
以下是优化后的一些参数。
3、优化参数说明:
- #基础配置
- datadir=/data/datafile
- socket=/var/lib/mysql/mysql.sock
- log-error=/data/log/mysqld.log
- pid-file=/var/run/mysqld/mysqld.pid
- character_set_server=utf8
- #允许任意IP访问
- bind-address = 0.0.0.0
- #是否支持符号链接,即数据库或表可以存储在my.cnf中指定datadir之外的分区或目录,为0不开启
- #symbolic-links=0
- #支持大小写
- lower_case_table_names=1
- #二进制配置
- server-id = 1
- log-bin = /data/log/mysql-bin.log
- log-bin-index =/data/log/binlog.index
- log_bin_trust_function_creators=1
- expire_logs_days=7
- #sql_mode定义了mysql应该支持的sql语法,数据校验等
- #mysql5.0以上版本支持三种sql_mode模式:ANSI、TRADITIONAL和STRICT_TRANS_TABLES。
- #ANSI模式:宽松模式,对插入数据进行校验,如果不符合定义类型或长度,对数据类型调整或截断保存,报warning警告。
- #TRADITIONAL模式:严格模式,当向mysql数据库插入数据时,进行数据的严格校验,保证错误数据不能插入,报error错误。用于事物时,会进行事物的回滚。
- #STRICT_TRANS_TABLES模式:严格模式,进行数据的严格校验,错误数据不能插入,报error错误。
- sql_mode=STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION
- #InnoDB存储数据字典、内部数据结构的缓冲池,16MB已经足够大了。
- innodb_additional_mem_pool_size = 16M
- #InnoDB用于缓存数据、索引、锁、插入缓冲、数据字典等
- #如果是专用的DB服务器,且以InnoDB引擎为主的场景,通常可设置物理内存的60%
- #如果是非专用DB服务器,可以先尝试设置成内存的1/4
- innodb_buffer_pool_size = 4G
- #InnoDB的log buffer,通常设置为 64MB 就足够了
- innodb_log_buffer_size = 64M
- #InnoDB redo log大小,通常设置256MB 就足够了
- innodb_log_file_size = 256M
- #InnoDB redo log文件组,通常设置为 2 就足够了
- innodb_log_files_in_group = 2
- #共享表空间:某一个数据库的所有的表数据,索引文件全部放在一个文件中,默认这个共享表空间的文件路径在data目录下。 默认的文件名为:ibdata1 初始化为10M。
- #独占表空间:每一个表都将会生成以独立的文件方式来进行存储,每一个表都有一个.frm表描述文件,还有一个.ibd文件。 其中这个文件包括了单独一个表的数据内容以及索引内容,默认情况下它的存储位置也是在表的位置之中。
- #设置参数为1启用InnoDB的独立表空间模式,便于管理
- innodb_file_per_table = 1
- #InnoDB共享表空间初始化大小,默认是 10MB,改成 1GB,并且自动扩展
- innodb_data_file_path = ibdata1:1G:autoextend
- #设置临时表空间最大4G
- innodb_temp_data_file_path=ibtmp1:500M:autoextend:max:4096M
- #启用InnoDB的status file,便于管理员查看以及监控
- innodb_status_file = 1
- #当设置为0,该模式速度最快,但不太安全,mysqld进程的崩溃会导致上一秒钟所有事务数据的丢失。
- #当设置为1,该模式是最安全的,但也是最慢的一种方式。在mysqld 服务崩溃或者服务器主机crash的情况下,binary log 只有可能丢失最多一个语句或者一个事务。
- #当设置为2,该模式速度较快,也比0安全,只有在操作系统崩溃或者系统断电的情况下,上一秒钟所有事务数据才可能丢失。
- innodb_flush_log_at_trx_commit = 1
- #设置事务隔离级别为 READ-COMMITED,提高事务效率,通常都满足事务一致性要求
- #transaction_isolation = READ-COMMITTED
- #max_connections:针对所有的账号所有的客户端并行连接到MYSQL服务的最大并行连接数。简单说是指MYSQL服务能够同时接受的最大并行连接数。
- #max_user_connections : 针对某一个账号的所有客户端并行连接到MYSQL服务的最大并行连接数。简单说是指同一个账号能够同时连接到mysql服务的最大连接数。设置为0表示不限制。
- #max_connect_errors:针对某一个IP主机连接中断与mysql服务连接的次数,如果超过这个值,这个IP主机将会阻止从这个IP主机发送出去的连接请求。遇到这种情况,需执行flush hosts。
- #执行flush host或者 mysqladmin flush-hosts,其目的是为了清空host cache里的信息。可适当加大,防止频繁连接错误后,前端host被mysql拒绝掉
- #在 show global 里有个系统状态Max_used_connections,它是指从这次mysql服务启动到现在,同一时刻并行连接数的最大值。它不是指当前的连接情况,而是一个比较值。如果在过去某一个时刻,MYSQL服务同时有10
- 00个请求连接过来,而之后再也没有出现这么大的并发请求时,则Max_used_connections=1000.请注意与show variables 里的max_user_connections的区别。#Max_used_connections / max_connections * 100% ≈ 85%
- max_connections=600
- max_connect_errors=1000
- max_user_connections=400
- #设置临时表最大值,这是每次连接都会分配,不宜设置过大 max_heap_table_size 和 tmp_table_size 要设置一样大
- max_heap_table_size = 100M
- tmp_table_size = 100M
- #每个连接都会分配的一些排序、连接等缓冲,一般设置为 2MB 就足够了
- sort_buffer_size = 2M
- join_buffer_size = 2M
- read_buffer_size = 2M
- read_rnd_buffer_size = 2M
- #建议关闭query cache,有些时候对性能反而是一种损害
- query_cache_size = 0
- #如果是以InnoDB引擎为主的DB,专用于MyISAM引擎的 key_buffer_size 可以设置较小,8MB 已足够
- #如果是以MyISAM引擎为主,可设置较大,但不能超过4G
- key_buffer_size = 8M
- #设置连接超时阀值,如果前端程序采用短连接,建议缩短这2个值,如果前端程序采用长连接,可直接注释掉这两个选项,是用默认配置(8小时)
- #interactive_timeout = 120
- #wait_timeout = 120
- #InnoDB使用后台线程处理数据页上读写I/0请求的数量,允许值的范围是1-64
- #假设CPU是2颗4核的,且数据库读操作比写操作多,可设置
- #innodb_read_io_threads=5
- #innodb_write_io_threads=3
- #通过show engine innodb status的FILE I/O选项可查看到线程分配
- #设置慢查询阀值,单位为秒
- long_query_time = 120
- slow_query_log=1 #开启mysql慢sql的日志
- log_output=table,File #日志输出会写表,也会写日志文件,为了便于程序去统计,所以最好写表
- slow_query_log_file=/data/log/slow.log
- ##针对log_queries_not_using_indexes开启后,记录慢sql的频次、每分钟记录的条数
- #log_throttle_queries_not_using_indexes = 5
- ##作为从库时生效,从库复制中如何有慢sql也将被记录
- #log_slow_slave_statements = 1
- ##检查未使用到索引的sql
- #log_queries_not_using_indexes = 1
- #快速预热缓冲池
- innodb_buffer_pool_dump_at_shutdown=1
- innodb_buffer_pool_load_at_startup=1
- #打印deadlock日志
- innodb_print_all_deadlocks=1
MySQL数据库参数优化的更多相关文章
- MySQL 数据库性能优化之缓存参数优化
在平时被问及最多的问题就是关于 MySQL 数据库性能优化方面的问题,所以最近打算写一个MySQL数据库性能优化方面的系列文章,希望对初中级 MySQL DBA 以及其他对 MySQL 性能优化感兴趣 ...
- MYSQL数据库的优化
我们究竟应该如何对MySQL数据库进行优化?下面我就从MySQL对硬件的选择.MySQL的安装.my.cnf的优化.MySQL如何进行架构设计及数据切分等方面来说明这个问题. 服务器物理硬件的优化 在 ...
- MySQL数据库的优化(上)单机MySQL数据库的优化
MySQL数据库的优化(上)单机MySQL数据库的优化 2011-03-08 08:49 抚琴煮酒 51CTO 字号:T | T 公司网站访问量越来越大,导致MySQL的压力越来越大,让我们自然想到的 ...
- [转]MySQL数据库的优化-运维架构师必会高薪技能,笔者近六年来一线城市工作实战经验
本文转自:http://liangweilinux.blog.51cto.com/8340258/1728131 年,嘿,废话不多说,下面开启MySQL优化之旅! 我们究竟应该如何对MySQL数据库进 ...
- mysql数据库性能优化(包括SQL,表结构,索引,缓存)
优化目标减少 IO 次数IO永远是数据库最容易瓶颈的地方,这是由数据库的职责所决定的,大部分数据库操作中超过90%的时间都是 IO 操作所占用的,减少 IO 次数是 SQL 优化中需要第一优先考虑,当 ...
- MySQL数据库的优化-运维架构师必会高薪技能,笔者近六年来一线城市工作实战经验
原文地址:http://liangweilinux.blog.51cto.com/8340258/1728131 首先在此感谢下我的老师年一线实战经验,我当然不能和我的老师平起平坐,得到老师三分之一的 ...
- 浅谈MySQL 数据库性能优化
MySQL数据库是 IO 密集型的程序,和其他数据库一样,主要功能就是数据的持久化以及数据的管理工作.本文侧重通过优化MySQL 数据库缓存参数如查询缓存,表缓存,日志缓存,索引缓存,innodb缓存 ...
- 知识点:Mysql 数据库索引优化实战(4)
知识点:Mysql 索引原理完全手册(1) 知识点:Mysql 索引原理完全手册(2) 知识点:Mysql 索引优化实战(3) 知识点:Mysql 数据库索引优化实战(4) 一:插入订单 业务逻辑:插 ...
- Mysql数据库性能优化(一)
参考 http://www.jb51.net/article/82254.htm 今天,数据库的操作越来越成为整个应用的性能瓶颈了,这点对于Web应用尤其明显.关于数据库的性能,这并不只是DBA才需要 ...
随机推荐
- stl(set和pair)
D - 4 Gym - 100989D In this cafeteria, the N tables are all ordered in one line, where table number ...
- BZOJ 1912(树的直径+LCA)
题面 传送门 分析 显然,如果不加边,每条边都要走2次,总答案为2(n-1) 考虑k=1的朴素情况: 加一条边(a,b),这条边和树上a->b的路径形成一个环,这个环上的边只需要走一遍,所以答案 ...
- 分布式ID增强篇--优化时钟回拨问题
原生实现 本文承接sharding-jdbc源码之分布式ID,在这篇文章中详细介绍了sharding-jdbc的分布式ID是如何实现的:很遗憾的是sharding-jdbc只是基于snowflake算 ...
- Python_pickle
pickle是一个可以将任意一个对象存储在硬盘文件中的工具. 更新:Python3中用法变了: https://www.cnblogs.com/fmgao-technology/p/9078918. ...
- Activiti6.0 java项目框架 spring5 SSM 工作流引擎 审批流程
工作流模块----------------------------------------------------------------------------------------------- ...
- js的label标签语句与with语句的用法
/** * label标签语句 * - 语法: * 标签名: 语句 * 如:start: n = 1; * 上面标签start可以被之后的break或continue语句引用 * - label标签语 ...
- 五 shell 变量与字符串操作
特点:1 shell变量没有数据类型的区分 2 Shell 把任何存储在变量中的值,皆视为以字符组成的“字符串”. 3 设定的变量值只在当前shell环境中有作用 4 不能以数字开头 ...
- HDU4089/Uva1498 Activation 概率DP(好题)
题意:Tomato要在服务器上激活一个游戏,一开始服务器序列中有N个人,他排在第M位,每次服务器会对序列中第一位的玩家进行激活,有四种结果: 1.有p1的概率会激活失败,这时候序列的状态是不变的.2. ...
- centos(6-7)安装openldap
前言 参考资料: http://yhz61010.iteye.com/blog/2352672 https://www.cnblogs.com/lemon-le/p/6266921.html 实验环境 ...
- OpenCV图像数据字节对齐
目录 1. IplImage的data字段,是char*类型,是4字节对齐. 2. 手动创建的Mat通常是没有字节对齐的 3. 从IplImage转过来的Mat,是字节对齐的 4. 总结 图像数据是否 ...