mysql执行拉链表操作
拉链表需求:
1.数据量比较大
2.变化的比例和频率比较小,例如客户的住址信息,联系方式等,比如有1千万的用户数据,每天全量存储会存储很多不变的信息,对存储也是浪费,因此可以使用拉链表的算法来节省存储空间
3.拉链历史表,既能反映每个客户不同时间的不同状态,也可查看某个时间点的全量快照信息
拉链表设计
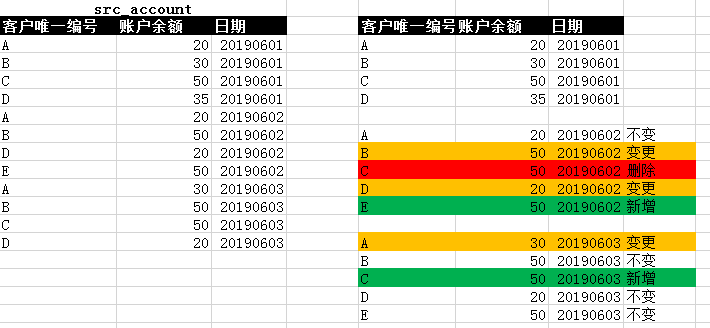
设计的拉链历史表:
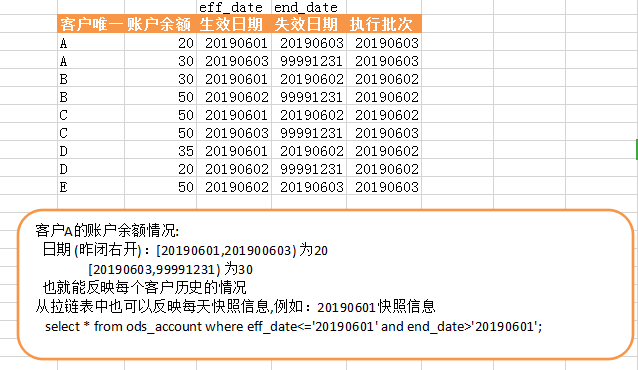
反映A客户的状态信息
select * from ods_account where cst_id='A';

反映20190601历史数据:
select * from ods_account where eff_date<='' and end_date>'';
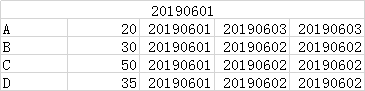
反映20190602历史全量数据:
select * from ods_account where eff_date<='' and end_date>'';

建表:
use edw; drop table if exists src_account;
create table if not exists src_account(
cst_id varchar(64) comment '客户唯一编号',
bal float comment '余额',
date_id varchar(16) comment '日期'
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
alter table src_account add primary key(cst_id,date_id); drop table if exists delta_account;
create table if not exists delta_account(
cst_id varchar(64) comment '客户唯一编号',
bal float comment '余额',
etl_flag varchar(16) comment 'ETL标记'
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
alter table delta_account add primary key(cst_id,etl_flag); drop table if exists odshis_account;
create table if not exists odshis_account(
cst_id varchar(64) comment '客户唯一编号',
bal float comment '余额',
eff_date varchar(16) comment '生效日期',
end_date varchar(16) comment '失效日期',
job_seq_id varchar(16) comment '批次号',
new_job_seq_id varchar(16) comment '最新批次号'
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
alter table odshis_account add primary key(cst_id,new_job_seq_id); drop table if exists ods_account;
create table if not exists ods_account(
cst_id varchar(64) comment '客户唯一编号',
bal float comment '余额',
eff_date varchar(16) comment '生效日期',
end_date varchar(16) comment '失效日期',
job_seq_id varchar(16) comment '批次号'
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
alter table ods_account add primary key(cst_id,eff_date,end_date);
加载原始数据:
delete from src_account;
insert into src_account values('A','','');
insert into src_account values('B','','');
insert into src_account values('C','','');
insert into src_account values('D','',''); insert into src_account values('A','','');
insert into src_account values('B','','');
insert into src_account values('D','','');
insert into src_account values('E','',''); insert into src_account values('A','','');
insert into src_account values('B','','');
insert into src_account values('C','','');
insert into src_account values('D','',''); insert into src_account values('A','','');
insert into src_account values('B','','');
insert into src_account values('C','','');
insert into src_account values('D','','');
insert into src_account values('E','','');
insert into src_account values('F','','');
insert into src_account values('G','','');
开始拉链过程:
#清空增量数据
truncate delta_account;
#加载增量数据(新增)
insert into delta_account
select t1.cst_id,t1.bal,'I' as etl_flag from
(select * from src_account where date_id = '${job_date_id}') t1
left join
(select * from src_account where date_id = '${before_job_date_id}') t2
on t1.cst_id = t2.cst_id where t2.cst_id is null; #加载增量数据(删除)
insert into delta_account
select t1.cst_id,t1.bal,'D' as etl_flag from
(select * from src_account where date_id = '${before_job_date_id}') t1
left join
(select * from src_account where date_id = '${job_date_id}') t2
on t1.cst_id = t2.cst_id where t2.cst_id is null; #加载增量数据(变更前)
insert into delta_account
select t1.cst_id,t1.bal,'A' as etl_flag from
(select * from src_account where date_id = '${job_date_id}') t1
left join
(select * from src_account where date_id = '${before_job_date_id}') t2
on t1.cst_id = t2.cst_id where t2.cst_id is not null
and t1.bal <> t2.bal; #加载增量数据(变更后)
insert into delta_account
select t1.cst_id,t2.bal,'B' as etl_flag from
(select * from src_account where date_id = '${job_date_id}') t1
left join
(select * from src_account where date_id = '${before_job_date_id}') t2
on t1.cst_id = t2.cst_id where t2.cst_id is not null
and t1.bal <> t2.bal; #1.重跑:删除已跑入数据
delete from ods_account where job_seq_id = '${job_date_id}'; #2.重跑:从历史表恢复数据
insert into ods_account(cst_id,bal,eff_date,end_date,job_seq_id)
select cst_id,bal,eff_date,end_date,job_seq_id from odshis_account
where new_job_seq_id = '${job_date_id}'; #3.重跑:删除已跑入历史数据
delete from odshis_account where new_job_seq_id = '${job_date_id}'; #4.备份数据到历史表
insert into odshis_account(cst_id,bal,eff_date,end_date,job_seq_id,new_job_seq_id)
select cst_id,bal,eff_date,end_date,job_seq_id,'${job_date_id}'
from ods_account t
where t.end_date='' and exists ( select 1 from delta_account s
where t.cst_id=s.cst_id ); #5.断链
update ods_account t set end_date='${job_date_id}',job_seq_id = '${job_date_id}' where t.end_date='' and exists ( select 1 from delta_account s where etl_flag in ('I','D','A') and t.cst_id=s.cst_id ); #6.加链
insert into ods_account(cst_id,bal,eff_date,end_date,job_seq_id)
select cst_id,bal,'${job_date_id}' as eff_date,'' as end_date,'${job_date_id}' as job_seq_id from delta_account where etl_flag in ('A','I'); #7.保持数据完整性
insert into ods_account (cst_id,bal,eff_date,end_date,job_seq_id)
select t.cst_id,t.bal,'${job_date_id}','${job_date_id}' as end_date,'${job_date_id}' as job_seq_id from delta_account t where etl_flag = 'D' and not exists (select 1 from ods_account s
where t.cst_id=s.cst_id)
mysql执行拉链表操作的更多相关文章
- 利用sqoop对mysql执行DML操作
业务背景 利用Sqoop对MySQL进行查询.添加.删除等操作. 业务实现 select操作: sqoop eval \ --connect jdbc:mysql://127.0.0.1:3306/m ...
- Shell脚本中执行sql语句操作mysql的5种方法【转】
对于自动化运维,诸如备份恢复之类的,DBA经常需要将SQL语句封装到shell脚本.本文描述了在Linux环境下mysql数据库中,shell脚本下调用sql语句的几种方法,供大家参考.对于脚本输出的 ...
- 在myeclipse中配置DB Driver(数据库用MySql),并在myeclipse执行sql语句操作
在myeclipse中配置DB Driver(数据库用MySql),并在myeclipse执行sql语句操作 MyEclipse6.5 , mysq驱动jar包为mysql-connector ...
- 闯祸了,生成环境执行了DDL操作《死磕MySQL系列 十四》
由于业务随着时间不停的改变,起初的表结构设计已经满足不了如今的需求,这时你是不是想那就加字段呗!加字段也是个艺术活,接下来由本文的主人咔咔给你吹. 试想一下这个场景 事务A在执行一个非常大的查询 事务 ...
- 数仓1.4 |业务数仓搭建| 拉链表| Presto
电商业务及数据结构 SKU库存量,剩余多少SPU商品聚集的最小单位,,,这类商品的抽象,提取公共的内容 订单表:周期性状态变化(order_info) id 订单编号 total_amount 订单金 ...
- linux下MySQL安装登录及操作
linux下MySQL安装登录及操作 二.安装Mysql 1.下载MySQL的安装文件 安装MySQL需要下面两个文件: MySQL-server-4.0.16-0.i386.rpm MySQL-cl ...
- hive拉链表
前言 本文将会谈一谈在数据仓库中拉链表相关的内容,包括它的原理.设计.以及在我们大数据场景下的实现方式. 全文由下面几个部分组成:先分享一下拉链表的用途.什么是拉链表.通过一些小的使用场景来对拉链表做 ...
- 漫谈数据仓库之拉链表(原理、设计以及在Hive中的实现)
本文将会谈一谈在数据仓库中拉链表相关的内容,包括它的原理.设计.以及在我们大数据场景下的实现方式. 全文由下面几个部分组成: 先分享一下拉链表的用途.什么是拉链表. 通过一些小的使用场景来对拉链表做近 ...
- hive拉链表以及退链例子笔记
拉链表设计: 在企业中,由于有些流水表每日有几千万条记录,数据仓库保存5年数据的话很容易不堪重负,因此可以使用拉链表的算法来节省存储空间. 例子: -- 用户信息表; 采集当日全量数据存储到 (当日 ...
随机推荐
- ftp安装和虚拟用户创建(终于搞清楚了)
安装 一.安装 sudo apt-get install vsftpd 二.查看安装结果 安装完毕,检查vsftpd进程是否已启动,可以查看进程或者查看监听端口 ps -eaf|grep vsftpd ...
- c# 模拟post登录
使用模拟登录大致可以分为两步 一.post登录获取cookis public CookieContainer GetCookie(string url,string account,string pa ...
- Go基础学习
Go基础学习 go的基础语法 fmt.Println("hello world!") //go采用行分隔符 关键字 下面列举了 Go 代码中会使用到的 25 个关键字或保留字: b ...
- Xshell6,亲测可用~破解版简单解压免安装~已更新官方版本安装方法
下面的内容别看了,使用这个最新的安装官方版本 https://www.cnblogs.com/taopanfeng/p/11671727.html 下面的内容别看了,使用这个最新的安装官方版本 htt ...
- iptables-restore - 恢复 IP Tables
总览 SYNOPSIS iptables-restore [-c] [-n] 描述 DESCRIPTION iptables-restore 用来从 STDIN 给出的数据中恢复 IP Tables. ...
- python脚本实现向钉钉群组发送消息
一.json格式 import json import requests def sendmessage(message): url = 'https://oapi.dingtalk.com/robo ...
- Win10+Linux(CentOS) 双系统安装教程--踩坑实录
最近心血来潮想给自己的笔记本装一套linux系统作为开发环境, 说干就干,首先先收集一下现在linux主流版本, 貌似现在市场上应用服务器比较多的是redhat相关产品,而ubuntu的优势在于它庞大 ...
- id 显示用户与用户组的信息
id 显示用户与用户组的信息 1.命令功能 id显示指定用户的用户ID和组ID等信息. 2.语法格式 id option username 参数说明 选项 选项说明 -gx 显示用户组ID -G ...
- [SCOI2016]幸运数字(线性基,倍增)
[SCOI2016]幸运数字 题目描述 A 国共有 n 座城市,这些城市由 n-1 条道路相连,使得任意两座城市可以互达,且路径唯一.每座城市都有一个幸运数字,以纪念碑的形式矗立在这座城市的正中心,作 ...
- django middleware介绍
Middleware Middleware是一个镶嵌到django的request/response处理机制中的一个hooks框架.它是一个修改django全局输入输出的一个底层插件系统. 每个中间件 ...