mysql执行拉链表操作
拉链表需求:
1.数据量比较大
2.变化的比例和频率比较小,例如客户的住址信息,联系方式等,比如有1千万的用户数据,每天全量存储会存储很多不变的信息,对存储也是浪费,因此可以使用拉链表的算法来节省存储空间
3.拉链历史表,既能反映每个客户不同时间的不同状态,也可查看某个时间点的全量快照信息
拉链表设计
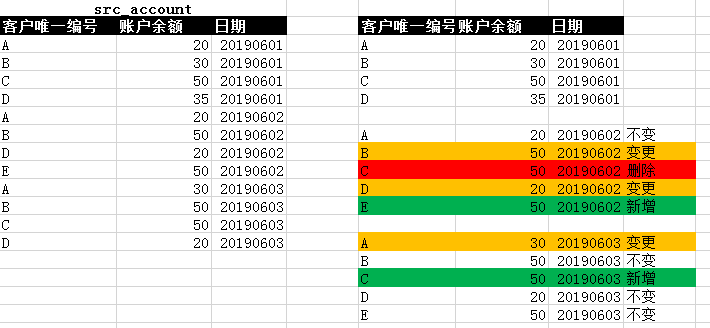
设计的拉链历史表:
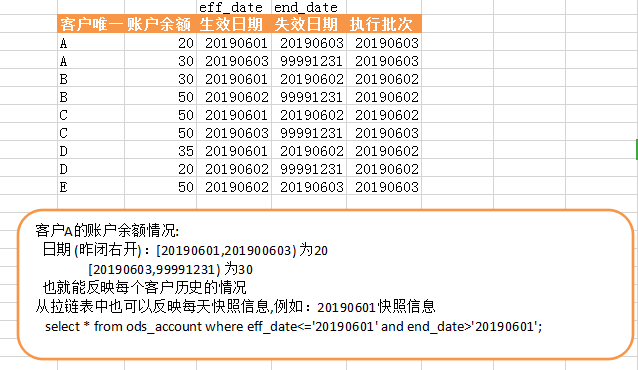
反映A客户的状态信息
select * from ods_account where cst_id='A';

反映20190601历史数据:
select * from ods_account where eff_date<='' and end_date>'';
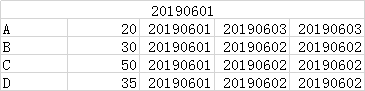
反映20190602历史全量数据:
select * from ods_account where eff_date<='' and end_date>'';

建表:
use edw; drop table if exists src_account;
create table if not exists src_account(
cst_id varchar(64) comment '客户唯一编号',
bal float comment '余额',
date_id varchar(16) comment '日期'
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
alter table src_account add primary key(cst_id,date_id); drop table if exists delta_account;
create table if not exists delta_account(
cst_id varchar(64) comment '客户唯一编号',
bal float comment '余额',
etl_flag varchar(16) comment 'ETL标记'
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
alter table delta_account add primary key(cst_id,etl_flag); drop table if exists odshis_account;
create table if not exists odshis_account(
cst_id varchar(64) comment '客户唯一编号',
bal float comment '余额',
eff_date varchar(16) comment '生效日期',
end_date varchar(16) comment '失效日期',
job_seq_id varchar(16) comment '批次号',
new_job_seq_id varchar(16) comment '最新批次号'
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
alter table odshis_account add primary key(cst_id,new_job_seq_id); drop table if exists ods_account;
create table if not exists ods_account(
cst_id varchar(64) comment '客户唯一编号',
bal float comment '余额',
eff_date varchar(16) comment '生效日期',
end_date varchar(16) comment '失效日期',
job_seq_id varchar(16) comment '批次号'
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
alter table ods_account add primary key(cst_id,eff_date,end_date);
加载原始数据:
delete from src_account;
insert into src_account values('A','','');
insert into src_account values('B','','');
insert into src_account values('C','','');
insert into src_account values('D','',''); insert into src_account values('A','','');
insert into src_account values('B','','');
insert into src_account values('D','','');
insert into src_account values('E','',''); insert into src_account values('A','','');
insert into src_account values('B','','');
insert into src_account values('C','','');
insert into src_account values('D','',''); insert into src_account values('A','','');
insert into src_account values('B','','');
insert into src_account values('C','','');
insert into src_account values('D','','');
insert into src_account values('E','','');
insert into src_account values('F','','');
insert into src_account values('G','','');
开始拉链过程:
#清空增量数据
truncate delta_account;
#加载增量数据(新增)
insert into delta_account
select t1.cst_id,t1.bal,'I' as etl_flag from
(select * from src_account where date_id = '${job_date_id}') t1
left join
(select * from src_account where date_id = '${before_job_date_id}') t2
on t1.cst_id = t2.cst_id where t2.cst_id is null; #加载增量数据(删除)
insert into delta_account
select t1.cst_id,t1.bal,'D' as etl_flag from
(select * from src_account where date_id = '${before_job_date_id}') t1
left join
(select * from src_account where date_id = '${job_date_id}') t2
on t1.cst_id = t2.cst_id where t2.cst_id is null; #加载增量数据(变更前)
insert into delta_account
select t1.cst_id,t1.bal,'A' as etl_flag from
(select * from src_account where date_id = '${job_date_id}') t1
left join
(select * from src_account where date_id = '${before_job_date_id}') t2
on t1.cst_id = t2.cst_id where t2.cst_id is not null
and t1.bal <> t2.bal; #加载增量数据(变更后)
insert into delta_account
select t1.cst_id,t2.bal,'B' as etl_flag from
(select * from src_account where date_id = '${job_date_id}') t1
left join
(select * from src_account where date_id = '${before_job_date_id}') t2
on t1.cst_id = t2.cst_id where t2.cst_id is not null
and t1.bal <> t2.bal; #1.重跑:删除已跑入数据
delete from ods_account where job_seq_id = '${job_date_id}'; #2.重跑:从历史表恢复数据
insert into ods_account(cst_id,bal,eff_date,end_date,job_seq_id)
select cst_id,bal,eff_date,end_date,job_seq_id from odshis_account
where new_job_seq_id = '${job_date_id}'; #3.重跑:删除已跑入历史数据
delete from odshis_account where new_job_seq_id = '${job_date_id}'; #4.备份数据到历史表
insert into odshis_account(cst_id,bal,eff_date,end_date,job_seq_id,new_job_seq_id)
select cst_id,bal,eff_date,end_date,job_seq_id,'${job_date_id}'
from ods_account t
where t.end_date='' and exists ( select 1 from delta_account s
where t.cst_id=s.cst_id ); #5.断链
update ods_account t set end_date='${job_date_id}',job_seq_id = '${job_date_id}' where t.end_date='' and exists ( select 1 from delta_account s where etl_flag in ('I','D','A') and t.cst_id=s.cst_id ); #6.加链
insert into ods_account(cst_id,bal,eff_date,end_date,job_seq_id)
select cst_id,bal,'${job_date_id}' as eff_date,'' as end_date,'${job_date_id}' as job_seq_id from delta_account where etl_flag in ('A','I'); #7.保持数据完整性
insert into ods_account (cst_id,bal,eff_date,end_date,job_seq_id)
select t.cst_id,t.bal,'${job_date_id}','${job_date_id}' as end_date,'${job_date_id}' as job_seq_id from delta_account t where etl_flag = 'D' and not exists (select 1 from ods_account s
where t.cst_id=s.cst_id)
mysql执行拉链表操作的更多相关文章
- 利用sqoop对mysql执行DML操作
业务背景 利用Sqoop对MySQL进行查询.添加.删除等操作. 业务实现 select操作: sqoop eval \ --connect jdbc:mysql://127.0.0.1:3306/m ...
- Shell脚本中执行sql语句操作mysql的5种方法【转】
对于自动化运维,诸如备份恢复之类的,DBA经常需要将SQL语句封装到shell脚本.本文描述了在Linux环境下mysql数据库中,shell脚本下调用sql语句的几种方法,供大家参考.对于脚本输出的 ...
- 在myeclipse中配置DB Driver(数据库用MySql),并在myeclipse执行sql语句操作
在myeclipse中配置DB Driver(数据库用MySql),并在myeclipse执行sql语句操作 MyEclipse6.5 , mysq驱动jar包为mysql-connector ...
- 闯祸了,生成环境执行了DDL操作《死磕MySQL系列 十四》
由于业务随着时间不停的改变,起初的表结构设计已经满足不了如今的需求,这时你是不是想那就加字段呗!加字段也是个艺术活,接下来由本文的主人咔咔给你吹. 试想一下这个场景 事务A在执行一个非常大的查询 事务 ...
- 数仓1.4 |业务数仓搭建| 拉链表| Presto
电商业务及数据结构 SKU库存量,剩余多少SPU商品聚集的最小单位,,,这类商品的抽象,提取公共的内容 订单表:周期性状态变化(order_info) id 订单编号 total_amount 订单金 ...
- linux下MySQL安装登录及操作
linux下MySQL安装登录及操作 二.安装Mysql 1.下载MySQL的安装文件 安装MySQL需要下面两个文件: MySQL-server-4.0.16-0.i386.rpm MySQL-cl ...
- hive拉链表
前言 本文将会谈一谈在数据仓库中拉链表相关的内容,包括它的原理.设计.以及在我们大数据场景下的实现方式. 全文由下面几个部分组成:先分享一下拉链表的用途.什么是拉链表.通过一些小的使用场景来对拉链表做 ...
- 漫谈数据仓库之拉链表(原理、设计以及在Hive中的实现)
本文将会谈一谈在数据仓库中拉链表相关的内容,包括它的原理.设计.以及在我们大数据场景下的实现方式. 全文由下面几个部分组成: 先分享一下拉链表的用途.什么是拉链表. 通过一些小的使用场景来对拉链表做近 ...
- hive拉链表以及退链例子笔记
拉链表设计: 在企业中,由于有些流水表每日有几千万条记录,数据仓库保存5年数据的话很容易不堪重负,因此可以使用拉链表的算法来节省存储空间. 例子: -- 用户信息表; 采集当日全量数据存储到 (当日 ...
随机推荐
- Delphi 字符串运算符
- 在centOS7.2上编译gcc4.1.2
1.下载安装gcc4.1.2安装包 wget ftp://ftp.gnu.org/gnu/gcc/gcc-4.1.2/gcc-4.1.2.tar.bz2 注:其他版本的安装包可以在上级目录寻找到. ...
- VS2013 删除"附加依赖项"中“继承的值”
经过好几次尝试,都无法在VS2013中直接删除“继承的值”,于是另辟蹊径,找到了一种解决方法. 相对而言,在 VS2010 中干这件事会容易一点,或者说,成功率更高一点,于是,我的思路就是再装一个 V ...
- SQL代码
SELECT SCHEMA_NAME(SCHEMA_ID)AS ID,name as Table_name FROM sys.tables;--查询表视图 查询表视图
- RabbitMQ 启用页面管理功能并设置权限
RabbitMQ 启用页面管理功能并设置权限 RabbitMQ guest administrator 在安装完 rabbitmq 后,默认有一个 guest/guest 账号密码,但是为了安全,此 ...
- 安装python3之后,yum用不了
使用centos 安装python3,并默认python3为python版本之后,用不了yum 原因是yum依赖于python2组件 解决方法: vi /usr/bin/yum 和 vi /usr/l ...
- 超级大佬已提前布局AI域名,人工智能时代真的来临了?
近日,郭盛华公司巨资收购的ai域名引起了业界深度关注,ai人工智能行业想必大家都熟悉不会陌生,但是ai域名你知道吗?了解域名行业的米友,对于ai域名肯定都熟悉,为什么今天小编要突然提到ai域名?因为a ...
- C# 判断 List 是否存在某一个字段
foreach (var item in list_QuestionnaireSelect) { EntityQuestionnaireParticipantsReport _entityReport ...
- HTTP协议的请求方法
HTTP概念: HTTP是一个基于TCP/IP通信协议来传递数据,包括html文件.图像.结果等,即是一个客户端和服务器端请求和应答的标准 1.http无连接:限制每次连接只处理一个请求,服务端完成客 ...
- python深度学习:矩阵转置(transpose)
转置:即行列转换. import numpy as np import matplotlib.pyplot as plt C=np.array([[1,2,3],[4,5,6]]) # Display ...