Policy Improvement and Policy Iteration
From the last post, we know how to evaluate a policy. But that's not enough, because the purpose of policy evaluation is to improve policies so that finally get the optimal policy. So in this post, we will discuss about how to improve a given policy, and how to from a given policy get to the optimal policy.
Firstly, when you have an evaluated policy, the Action-Value function is known for every state. That is, at a certain state s, we known which action can give the system the largest reward.
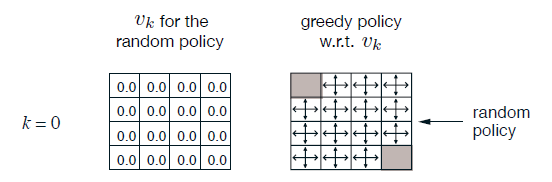
In the puzzle wandering example, we evaluate the random policy. However,the State-Value functions can be used for policy improvement. After 1 step calculating,we can conclude at the circled location, moving left is better than randomly picking a direction because left side has more reward.
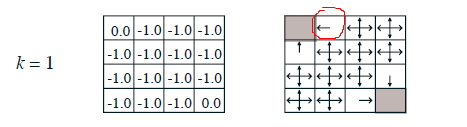
After three steps, we've got a much better intuition about the map. We can change the random policy to a new better one.

The way to improve the current policy is to greedyly pick actions for every state. It is worth noting that greedily picking actions does not means it only consider one step (too greedy to consider multiple steps). Instead, when k=3, the algorithm can foresee three steps, and the greedy picking algorithm will select the best action for k steps.
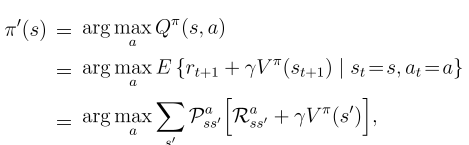
The Policy Iteration Algorithm is keep doing evaluation and improvement tasks untill the policy becomes stable,
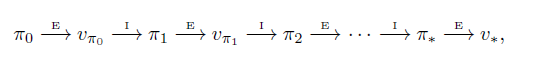

This process means Action-Value function of the improved policy picking the best return from a single action:
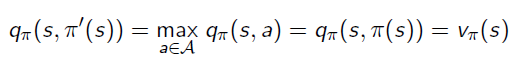
The algorithm is:

Policy Improvement and Policy Iteration的更多相关文章
- Provider Policy与Consumer Policy在bnd中的区别
首先需要了解的是bnd的相关知识: 1. API(也就是接口), 2. API Provider(接口的实现) 3. API Consumer( 接口的使用者) OSGi中的一个版本有4个部分: ...
- Reinforcement Learning Index Page
Reinforcement Learning Posts Step-by-step from Markov Property to Markov Decision Process Markov Dec ...
- Policy Gradient Algorithms
Policy Gradient Algorithms 2019-10-02 17:37:47 This blog is from: https://lilianweng.github.io/lil-l ...
- Deep Learning专栏--强化学习之从 Policy Gradient 到 A3C(3)
在之前的强化学习文章里,我们讲到了经典的MDP模型来描述强化学习,其解法包括value iteration和policy iteration,这类经典解法基于已知的转移概率矩阵P,而在实际应用中,我们 ...
- 使用 SecurityManager 和 Policy File 管理 Java 程序的权限
参考资料 该文中的内容来源于 Oracle 的官方文档.Oracle 在 Java 方面的文档是非常完善的.对 Java 8 感兴趣的朋友,可以从这个总入口 Java SE 8 Documentati ...
- Utility2:Appropriate Evaluation Policy
UCP收集所有Managed Instance的数据的机制,是通过启用各个Managed Instances上的Collection Set:Utility information(位于Managem ...
- trait与policy模板应用简单示例
trait与policy模板应用简单示例 accumtraits.hpp // 累加算法模板的trait // 累加算法模板的trait #ifndef ACCUMTRAITS_HPP #define ...
- trait与policy模板技术
trait与policy模板技术 我们知道,类有属性(即数据)和操作两个方面.同样模板也有自己的属性(特别是模板参数类型的一些具体特征,即trait)和算法策略(policy,即模板内部的操作逻辑). ...
- Network Policy - 每天5分钟玩转 Docker 容器技术(171)
Network Policy 是 Kubernetes 的一种资源.Network Policy 通过 Label 选择 Pod,并指定其他 Pod 或外界如何与这些 Pod 通信. 默认情况下,所有 ...
随机推荐
- 关于Mysql group by 的记录
对于有group by 字段的select语句,group by 后面的字段如果没有出现在组函数里(max,min,sum,avg, count等),则一定要出现在select后面的字段里, 否则会报 ...
- 动态路由协议RIP
RIP Routing Information Protocol,属IGP协议,是距离矢量型动态路由协议(直接发送路由信息的协议为距离矢量型协议),使用UDP协议,端口号520. 贝尔曼福特算法 RI ...
- ubuntu下安装3.6.5
1.下载python3.6.5安装包 地址:https://www.python.org/ftp/python/3.6.5/Python-3.6.5.tgz 解压:tar -xvzf Python-3 ...
- blazeFace
围绕四个点构造模型 1.扩大感受野 使用5*5卷积替换3*3来扩大感受野,在深度分离卷积中,pw与dw计算比为d/k^2,d为输出通道,k为 dw的卷积核,即增加dw的卷积核所带来的计算并不大. 在M ...
- GUI学习之三十二—QLCDNumber学习总结
下面我们来总结一下QLCDNumber的用法 一.描述 QLCDNumber主要用来展示LCD样式的数字,他可以显示几乎任何大小的数字,可以显示十进制,十六进制,八进制或二进制数,也可以展示一些简单的 ...
- express 设置跨域
app.use(function (req, res, next) { res.header('Access-Control-Allow-Origin', 'http://localhost: ...
- Django【第24篇】:JS实现的ajax和同源策略
JS实现的ajax和同源策略 一.回顾jQuery实现的ajax 首先说一下ajax的优缺点 优点: AJAX使用Javascript技术向服务器发送异步请求: AJAX无须刷新整个页面: 因为服务器 ...
- 【牛客Wannafly挑战赛23】F 计数
题目链接 题意 给定一张边带权的无向图,求生成树的权值和是 k 的倍数的生成树个数模 p 的值. \(n\leq 100,k\leq 100,p\mod k=1\) Sol 看见整除然后 \(p\mo ...
- LeetCode--114--二叉树展开为链表(python)
给定一个二叉树,原地将它展开为链表. 例如,给定二叉树 1 / \ 2 5 / \ \ 3 4 6将其展开为: 1 \ 2 \ 3 \ 4 \ ...
- 51nod1790 输出二进制数
题目描述 题解 过于真实 LJ卡常题 一个显然的dp: 设f[i][j]表示做完前i个,最后一段为j+1~i的方案(最小值同理) 那么f[i][j]=min(f[i-j-1][k]),其中k~j-1要 ...