Policy Improvement and Policy Iteration
From the last post, we know how to evaluate a policy. But that's not enough, because the purpose of policy evaluation is to improve policies so that finally get the optimal policy. So in this post, we will discuss about how to improve a given policy, and how to from a given policy get to the optimal policy.
Firstly, when you have an evaluated policy, the Action-Value function is known for every state. That is, at a certain state s, we known which action can give the system the largest reward.
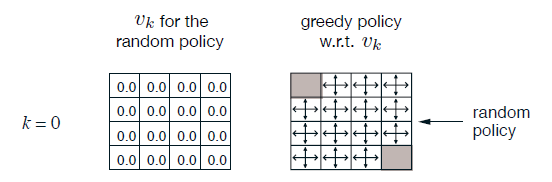
In the puzzle wandering example, we evaluate the random policy. However,the State-Value functions can be used for policy improvement. After 1 step calculating,we can conclude at the circled location, moving left is better than randomly picking a direction because left side has more reward.
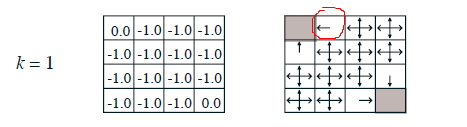
After three steps, we've got a much better intuition about the map. We can change the random policy to a new better one.

The way to improve the current policy is to greedyly pick actions for every state. It is worth noting that greedily picking actions does not means it only consider one step (too greedy to consider multiple steps). Instead, when k=3, the algorithm can foresee three steps, and the greedy picking algorithm will select the best action for k steps.
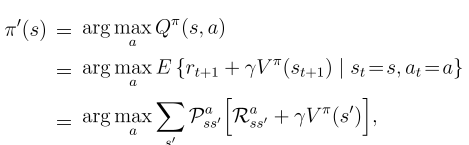
The Policy Iteration Algorithm is keep doing evaluation and improvement tasks untill the policy becomes stable,
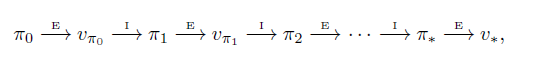

This process means Action-Value function of the improved policy picking the best return from a single action:
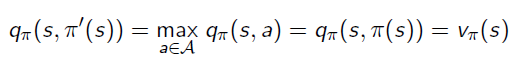
The algorithm is:

Policy Improvement and Policy Iteration的更多相关文章
- Provider Policy与Consumer Policy在bnd中的区别
首先需要了解的是bnd的相关知识: 1. API(也就是接口), 2. API Provider(接口的实现) 3. API Consumer( 接口的使用者) OSGi中的一个版本有4个部分: ...
- Reinforcement Learning Index Page
Reinforcement Learning Posts Step-by-step from Markov Property to Markov Decision Process Markov Dec ...
- Policy Gradient Algorithms
Policy Gradient Algorithms 2019-10-02 17:37:47 This blog is from: https://lilianweng.github.io/lil-l ...
- Deep Learning专栏--强化学习之从 Policy Gradient 到 A3C(3)
在之前的强化学习文章里,我们讲到了经典的MDP模型来描述强化学习,其解法包括value iteration和policy iteration,这类经典解法基于已知的转移概率矩阵P,而在实际应用中,我们 ...
- 使用 SecurityManager 和 Policy File 管理 Java 程序的权限
参考资料 该文中的内容来源于 Oracle 的官方文档.Oracle 在 Java 方面的文档是非常完善的.对 Java 8 感兴趣的朋友,可以从这个总入口 Java SE 8 Documentati ...
- Utility2:Appropriate Evaluation Policy
UCP收集所有Managed Instance的数据的机制,是通过启用各个Managed Instances上的Collection Set:Utility information(位于Managem ...
- trait与policy模板应用简单示例
trait与policy模板应用简单示例 accumtraits.hpp // 累加算法模板的trait // 累加算法模板的trait #ifndef ACCUMTRAITS_HPP #define ...
- trait与policy模板技术
trait与policy模板技术 我们知道,类有属性(即数据)和操作两个方面.同样模板也有自己的属性(特别是模板参数类型的一些具体特征,即trait)和算法策略(policy,即模板内部的操作逻辑). ...
- Network Policy - 每天5分钟玩转 Docker 容器技术(171)
Network Policy 是 Kubernetes 的一种资源.Network Policy 通过 Label 选择 Pod,并指定其他 Pod 或外界如何与这些 Pod 通信. 默认情况下,所有 ...
随机推荐
- deletefile 与KILL
1.Kill 语句 从磁盘中删除文件.语法Kill pathname必要的 pathname 参数是用来指定一个文件名的字符串表达式.pathname 可以包含目录或文件夹.以及驱动器.说明在 Mic ...
- 2Ubuntu学习
1.设置Ubuntu系统的英文设置成中文 2.root用户密码设置 3.
- css使既有浮动又有左右margin的多个元素两端对其
两端对齐效果 如上图中红色的9个div它们中间有间距,而最左边和最右边是没有间距的,这种布局如果使用css3的flex来实现是非常简单的,而如果要使用float布局就需要一些特殊的技巧了. 实现原理 ...
- axios 各种请求方式传递参数
get delete 方法较为不同 注意:每个方法的传参格式不同,具体用法看下方 get请求方式将需要入参的数据作为 params 属性的值,最后整体作为参数传递 delete请求方式将将需要入参的数 ...
- 【python】对于程序员来说,2018刑侦科推理试卷是问题么?
最近网上很火的2018刑侦科推理试卷,题目确实很考验人逻辑思维能力. 可是对于程序员来说,这根本不是问题.写个程序用穷举法计算一遍即可,太简单. import itertools class Solu ...
- 【leetcode】299. Bulls and Cows
题目如下: 解题思路:本题难度不太大,对时间复杂度也没有很高的要求.我的做法是用一个字典来保存每个字符出现的次数,用正数1记录标记secret中出现的字符,用负数1记录guess中出现的字符,这样每出 ...
- webpack配置反向代理
devServer: { contentBase: path.resolve(__dirname, "../dev"), compress: true, port: ,//本身的端 ...
- PHP培训教程 php生成WAP页面
WAP(无线通讯协议)是在数字移动电话.个人手持设备(PDA等)及计算机之间进行通讯的开放性全球标准.由于静态的WAP页面在很多方面不能满足用户个性化的服务请求,因此通过WAP服务器端语言产生动态的W ...
- Bugku 杂项 又一张图片,还单纯吗
又一张图片,还单纯吗 下载后,用binwalk打开图片 使用foremost 2.png进行分离 得到图片 关于foremost foremost [-v|-V|-h|-T|-Q|-q|-a|-w-d ...
- 如何在ASP.NET Core中上传超大文件
HTML部分 <%@PageLanguage="C#"AutoEventWireup="true"CodeBehind="index.aspx. ...