大数据笔记(二十二)——大数据实时计算框架Storm
一.
1、对比:离线计算和实时计算
离线计算:MapReduce,批量处理(Sqoop-->HDFS--> MR ---> HDFS)
实时计算:Storm和Spark Sparking,数据实时性(Flume ---> Kafka ---> 流式计算 ---> Redis)
2、常见的实时计算(流式计算)代表
(1)Apache Storm
(2)Spark Streaming
(3)Apache Flink:既可以流式计算,也可以离线计算
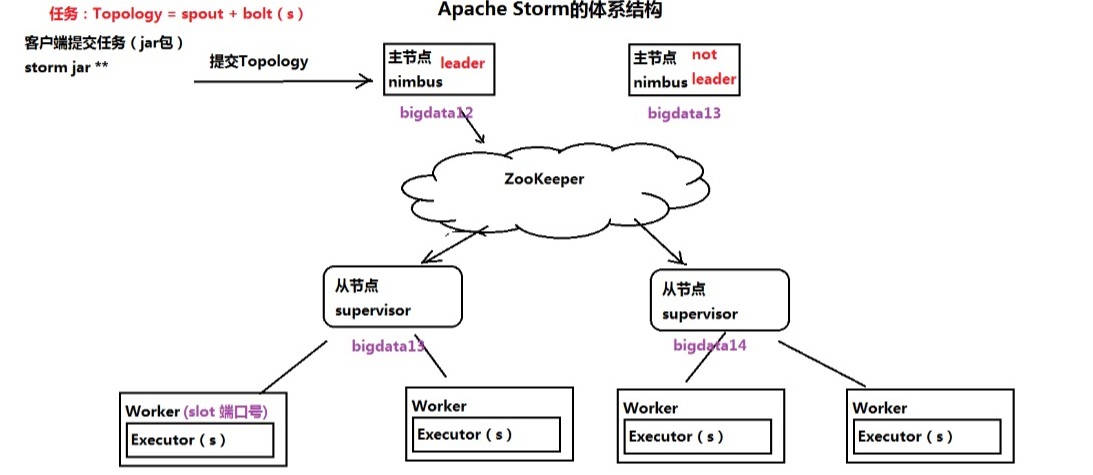
二、Storm的体系结构
三、安装和配置Apache Storm
1、前提条件:安装ZooKeeper(Hadoop的HA)
tar -zxvf apache-storm-1.0.3.tar.gz -C ~/training/
设置环境变量:
STORM_HOME=/root/training/apache-storm-1.0.3
export STORM_HOME PATH=$STORM_HOME/bin:$PATH
export PATH
配置文件: conf/storm.yaml
注意:- 后面有一个空格
: 后面有一个空格
2、Storm的伪分布模式(bigdata11)
18 storm.zookeeper.servers:
19 - "bigdata11"
主节点的信息
23 nimbus.seeds: ["bigdata11"]
每个从节点上的worker个数
25 supervisor.slots:ports:
26 - 6700
27 - 6701
28 - 6702
29 - 6703
任务上传后,保存的目录
storm.local.dir: "/root/training/apache-storm-1.0.3/tmp"
启动Storm:bigdata11
主节点: storm nimbus &
从节点: storm supervisor &
UI: storm ui & ---> http://ip:8080
logviewer:storm logviewer &
3、Storm的全分布模式(bigdata12 bigdata13 bigdata14)
(*)在bigata12上进行配置
storm.zookeeper.servers:
- "bigdata12"
- "bigdata13"
- "bigdata14"
nimbus.seeds: ["bigdata12"]
storm.local.dir: "/root/training/apache-storm-1.0.3/tmp"
supervisor.slots:ports:
- 6700
- 6701
- 6702
- 6703
(*)复制到其他节点
scp -r apache-storm-1.0.3/ root@bigdata13:/root/training
scp -r apache-storm-1.0.3/ root@bigdata14:/root/training
(*)启动
bigdata12: storm nimbus &
storm ui &
storm logviewer &
bigdata13: storm supervisor &
storm logviwer &
bigdata14: storm supervisor &
storm logviwer &
4、Storm的HA(bigdata12 bigdata13 bigdata14)
每台机器都要修改:
nimbus.seeds: ["bigdata12", "bigdata13"]
在bigdata13上,单独启动一个nimbus ----> not leader
还可以单独启动一个UI
四.WordCount数据流动的过程

用Java程序实现:
WordCountSpout.java
package demo; import java.util.Map;
import java.util.Random;
import java.util.stream.Collector; import org.apache.jute.Utils;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Values; /**
* @作用:采集数据,送到下一个Bolt组件
*
*/
public class WordCountSpout extends BaseRichSpout{ /**
*
*/
private static final long serialVersionUID = 1L; //定义数据
private String[] data = {"I love Beijing","I love China","Beijing is the capital of China"}; private SpoutOutputCollector collector; @Override
public void nextTuple() {
//每三秒采集一次
org.apache.storm.utils.Utils.sleep(3000); // 由storm框架进行调用,用于接收外部系统产生的数据
//随机产生一个字符串,代表采集的数据
int random = new Random().nextInt(3);//3以内随机数 //采集数据,然后发送给下一个组件
System.out.println("采集的数据是: "+data[random]);
this.collector.emit(new Values(data[random]));
} /*
* SpoutOutputCollector 输出流
*/
@Override
public void open(Map arg0, TopologyContext arg1, SpoutOutputCollector collector) {
// spout组件初始化方法
this.collector = collector;
} @Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
// 声明输出的schema
declarer.declare(new Fields("sentence"));
} }
WordCountSplitBolt.java
package demo; import java.util.Map; import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values; /**
* 第一个Bolt组件,用于分词操作
*
*/
public class WordCountSplitBolt extends BaseRichBolt{ private OutputCollector collector;
@Override
public void execute(Tuple tuple) {
//处理上一个组件发来的数据
//获取数据
String line = tuple.getStringByField("sentence");
//分词
String[] words = line.split(" "); //输出
for (String word : words) {
this.collector.emit(new Values(word,1));
}
} //OutputCollector:bolt组件输出流
@Override
public void prepare(Map arg0, TopologyContext arg1, OutputCollector collector) {
// 对bolt组件初始化
this.collector = collector;
} @Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
// 声明输出的Schema
declarer.declare(new Fields("word","count"));
} }
WordCountTotalBolt.java
package demo; import java.util.HashMap;
import java.util.Map; import org.apache.storm.generated.DistributedRPCInvocations.AsyncProcessor.result;
import org.apache.storm.shade.org.apache.commons.lang.Validate;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values; /**
* 第二个Bolt组件:单词的计数
*
*/
public class WordCountTotalBolt extends BaseRichBolt{ private OutputCollector collector; private Map<String, Integer> result = new HashMap<>(); @Override
public void execute(Tuple tuple) {
//获取数据:单词、频率:1
String word = tuple.getStringByField("word");
int count = tuple.getIntegerByField("count"); if (result.containsKey(word)) {
//单词已存在
int total = result.get(word);
result.put(word, total+count);
}else {
//单词不存在
result.put(word, count);
} //输出
System.out.println("输出的结果是: "+ result);
//发送给下一个组件
this.collector.emit(new Values(word,result.get(word)));
} @Override
public void prepare(Map arg0, TopologyContext arg1, OutputCollector collector) {
// TODO Auto-generated method stub
this.collector = collector;
} @Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
// TODO Auto-generated method stub
declarer.declare(new Fields("word","total"));
} }
WordCountTopology.java
package demo; import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.generated.AlreadyAliveException;
import org.apache.storm.generated.AuthorizationException;
import org.apache.storm.generated.InvalidTopologyException;
import org.apache.storm.generated.StormTopology;
import org.apache.storm.hdfs.bolt.HdfsBolt;
import org.apache.storm.hdfs.bolt.format.DefaultFileNameFormat;
import org.apache.storm.hdfs.bolt.format.DelimitedRecordFormat;
import org.apache.storm.hdfs.bolt.rotation.FileSizeRotationPolicy;
import org.apache.storm.hdfs.bolt.rotation.FileSizeRotationPolicy.Units;
import org.apache.storm.hdfs.bolt.sync.CountSyncPolicy;
import org.apache.storm.redis.bolt.RedisStoreBolt;
import org.apache.storm.redis.common.config.JedisPoolConfig;
import org.apache.storm.redis.common.mapper.RedisDataTypeDescription;
import org.apache.storm.redis.common.mapper.RedisStoreMapper;
import org.apache.storm.topology.IRichBolt;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.ITuple; public class WordCountTopology { public static void main(String[] args) throws Exception {
//设置用户为root权限
System.setProperty("HADOOP_USER_NAME", "root");
//创建一个任务:Topology = spout + bolt(s) TopologyBuilder builder = new TopologyBuilder(); //设置任务的第一个组件:spout组件
builder.setSpout("mywordcount_spout", new WordCountSpout());
//builder.setSpout("mywordcount_spout", createKafkaSpout()); //设置任务的第二个组件:bolt组件,拆分单词
builder.setBolt("mywordcount_split", new WordCountSplitBolt()).shuffleGrouping("mywordcount_spout"); //设置任务的第三个组件:bolt组件,计数
builder.setBolt("mywordcount_total", new WordCountTotalBolt()).fieldsGrouping("mywordcount_split", new Fields("word")); //设置任务的第四个bolt组件,将结果写入Redis
//builder.setBolt("mywordcount_redis", createRedisBolt()).shuffleGrouping("mywordcount_total"); //设置任务的第四个bolt组件,将结果写入HDFS
//builder.setBolt("mywordcount_hdfs", createHDFSBolt()).shuffleGrouping("mywordcount_total"); //设置任务的第四个bolt组件,将结果写入HBase
//builder.setBolt("mywordcount_hdfs", new WordCountHBaseBolt()).shuffleGrouping("mywordcount_total"); //创建任务
StormTopology topology = builder.createTopology(); //配置参数
Config conf = new Config(); //提交任务
//方式1:本地模式(直接在eclipse运行)
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("mywordcount", conf, topology); // 方式2 集群模式: storm jar temp/storm.jar demo.WordCountTopology MyStormWordCount
//StormSubmitter.submitTopology(args[0], conf, topology);
} private static IRichBolt createHDFSBolt() {
// 创建一个HDFS的Bolt组件,写入到HDFS
HdfsBolt bolt = new HdfsBolt(); //指定HDFS位置:namenode地址
bolt.withFsUrl("hdfs://192.168.153.11:9000"); //数据保存在HDFS哪个目录
bolt.withFileNameFormat(new DefaultFileNameFormat().withPath("/stormresult")); //ָ指定key和value的分隔符:Beijing|10
bolt.withRecordFormat(new DelimitedRecordFormat().withFieldDelimiter("|")); //生成文件的策略:每5M生成一个文件
bolt.withRotationPolicy(new FileSizeRotationPolicy(5.0f,Units.MB)); //与HDFS进行数据同步的策略:tuple数据达到1K同步一次
bolt.withSyncPolicy(new CountSyncPolicy(1024)); return bolt;
} private static IRichBolt createRedisBolt() {
// 创建一个Redis的bolt组件,将数据写入redis中
//创建一个Redis的连接池 JedisPoolConfig.Builder builder = new JedisPoolConfig.Builder();
builder.setHost("192.168.153.11");
builder.setPort(6379);
JedisPoolConfig poolConfig = builder.build(); //storeMapper: 存入Redis中数据的格式
return new RedisStoreBolt(poolConfig, new RedisStoreMapper() { @Override
public RedisDataTypeDescription getDataTypeDescription() {
// 声明存入Redis的数据类型
return new RedisDataTypeDescription(RedisDataTypeDescription.RedisDataType.HASH,"wordcount");
} @Override
public String getValueFromTuple(ITuple tuple) {
// 从上一个组件接收的value
return String.valueOf(tuple.getIntegerByField("total"));
} @Override
public String getKeyFromTuple(ITuple tuple) {
// 从上一个组件接收的key
return tuple.getStringByField("word");
}
});
} }
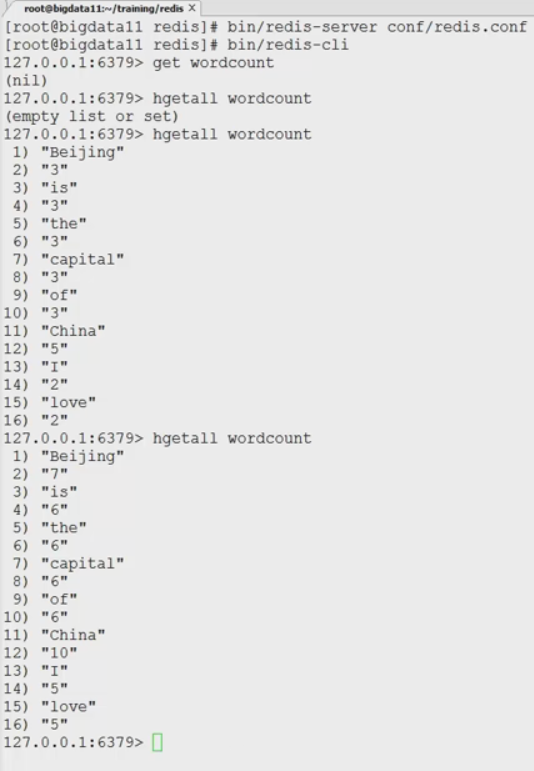
集成redis结果:
集成hdfs:

集成hbase:
WordCountHBaseBolt.java
package demo; import java.util.Map; import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.generated.master.table_jsp;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.IRichBolt;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Tuple; /**
* 创建一个HBASE的表:create 'result','info'
*
*/
public class WordCountHBaseBolt extends BaseRichBolt { //定义一个Hbase的客户端
private HTable htable; @Override
public void execute(Tuple tuple) {
//得到上一个组件处理的数据
String word = tuple.getStringByField("word");
int total = tuple.getIntegerByField("total"); //创建一个put对象
Put put = new Put(Bytes.toBytes(word));
//列族:info 列:word 值:word
put.add(Bytes.toBytes("info"), Bytes.toBytes("word"), Bytes.toBytes(word));
put.add(Bytes.toBytes("info"), Bytes.toBytes("total"), Bytes.toBytes(String.valueOf(total)));
try {
htable.put(put);
} catch (Exception e) {
e.printStackTrace();
}
} @Override
public void prepare(Map arg0, TopologyContext arg1, OutputCollector arg2) {
// 初始化:指定HBASE的相关信息 } @Override
public void declareOutputFields(OutputFieldsDeclarer arg0) {
// TODO Auto-generated method stub } }
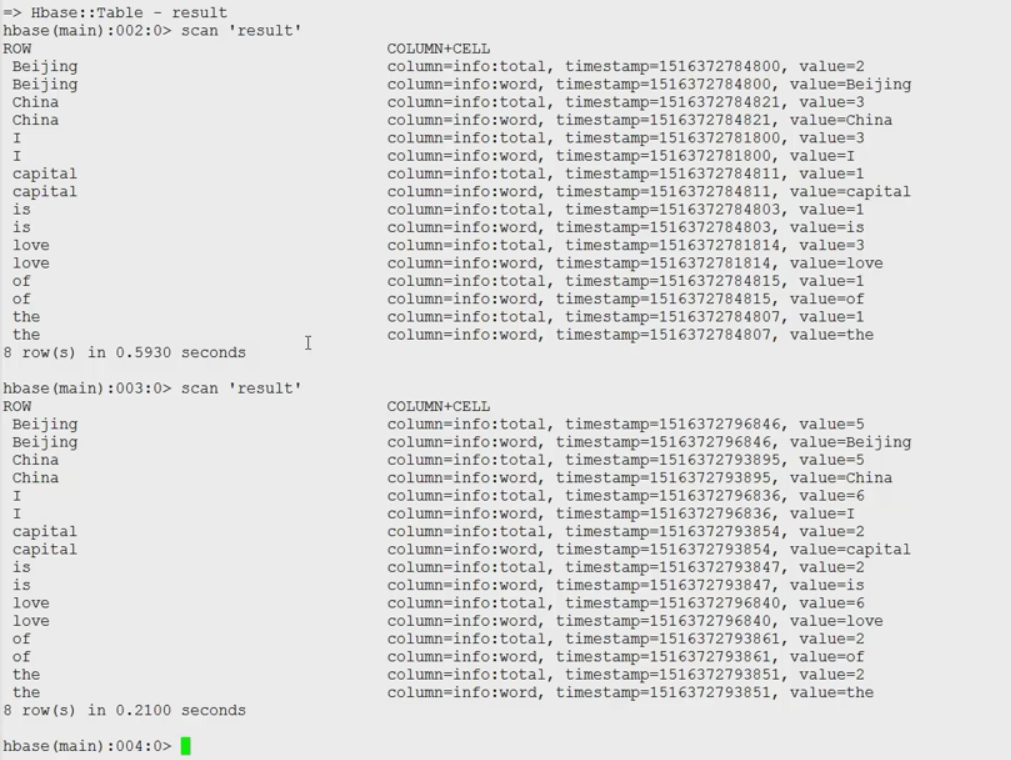
通过hbase shell打开hbase命令行
五.Strom任务提交的过程
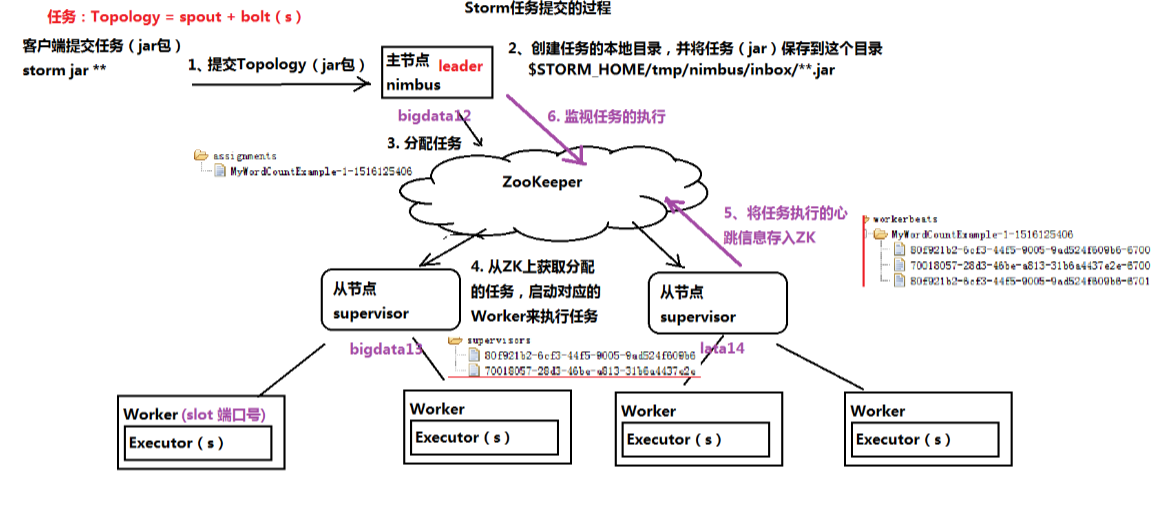
1.客户端提交任务
2.创建任务的本地目录
3.nimbus分配任务到zookeeper
4.supervisor从ZK获取分配的任务,启动对应的worker来执行任务
5.将任务执行的心跳存入ZK
6.nimbus监听任务的执行
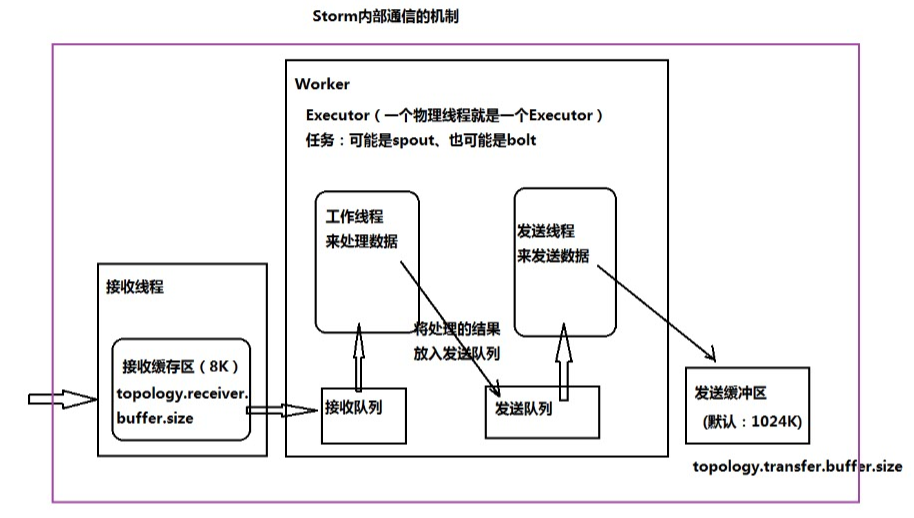
六、Storm内部通信的机制
任务的执行:worker中的Executor
大数据笔记(二十二)——大数据实时计算框架Storm的更多相关文章
- 大数据笔记(十二)——使用MRUnit进行单元测试
package demo.wc; import java.util.ArrayList; import java.util.List; import org.apache.hadoop.io.IntW ...
- Android群英传笔记——第十二章:Android5.X 新特性详解,Material Design UI的新体验
Android群英传笔记--第十二章:Android5.X 新特性详解,Material Design UI的新体验 第十一章为什么不写,因为我很早之前就已经写过了,有需要的可以去看 Android高 ...
- (C/C++学习笔记) 二十二. 标准模板库
二十二. 标准模板库 ● STL基本介绍 标准模板库(STL, standard template library): C++提供的大量的函数模板(通用算法)和类模板. ※ 为什么我们一般不需要自己写 ...
- 深度学习课程笔记(十二) Matrix Capsule
深度学习课程笔记(十二) Matrix Capsule with EM Routing 2018-02-02 21:21:09 Paper: https://openreview.net/pdf ...
- 汇编入门学习笔记 (十二)—— int指令、port
疯狂的暑假学习之 汇编入门学习笔记 (十二)-- int指令.port 參考: <汇编语言> 王爽 第13.14章 一.int指令 1. int指令引发的中断 int n指令,相当于引 ...
- VSTO 学习笔记(十二)自定义公式与Ribbon
原文:VSTO 学习笔记(十二)自定义公式与Ribbon 这几天工作中在开发一个Excel插件,包含自定义公式,根据条件从数据库中查询结果.这次我们来做一个简单的测试,达到类似的目的. 即在Excel ...
- python3.4学习笔记(二十二) python 在字符串里面插入指定分割符,将list中的字符转为数字
python3.4学习笔记(二十二) python 在字符串里面插入指定分割符,将list中的字符转为数字在字符串里面插入指定分割符的方法,先把字符串变成list然后用join方法变成字符串str=' ...
- OllyDbg 使用笔记 (十二)
OllyDbg 使用笔记 (十二) 參考 书:<加密与解密> 视频:小甲鱼 解密系列 视频 演示样例程序下载地址:http://pan.baidu.com/s/1eQiV6aI 安装好程序 ...
- 学习笔记:CentOS7学习之二十二: 结构化命令case和for、while循环
目录 学习笔记:CentOS7学习之二十二: 结构化命令case和for.while循环 22.1 流程控制语句:case 22.2 循环语句 22.1.2 for-do-done 22.3 whil ...
随机推荐
- C++学习——在C文件中调用C++文件中的函数
1.CPP文件中的内容 #include "mytest.h" #include <iostream> using namespace std; int add(con ...
- python-day12(正式学习)
目录 可变长参数 可变长形参之* 可变长实参之* 可变长形参之** 可变长实参之** 可变长参数应用 命名关键字形参 函数对象 四大功能 引用 当作参数传给一个函数 可以当作函数的返回值 可以当作容器 ...
- 看电视剧<潜伏>有感
前几天看了老电视剧-潜伏,有一些感慨. 一,立场和真相都不重要,形式才是最重要的. 二.历史在不断的轮回中. 好汉历经千辛万苦杀掉了为害一方的恶霸,好汉的威望达到了顶峰,自然的成了村庄的守护者和掌控者 ...
- RabbitMQ入门教程(六):路由选择Routing
原文:RabbitMQ入门教程(六):路由选择Routing 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog. ...
- git常用命令之log
查看提交日志记录 基础命令: git log commit ca82a6dff817ec66f44342007202690a93763949 Author: Scott Chacon < ...
- php 中英文混合字符串长度计算
(strlen($string) + mb_strlen($string,'UTF8')) / 2;tw 这样计算的
- cacti监控
cacti监控 cacti简介 Cacti是一套基于php,mysql,snmp及rrdtool开发的网络流量监测图形分析工具.它通过snmpget获取数据,使用rrdtool绘画图形 Cacti轮询 ...
- Java并发编程实战 第4章 对象的组合
Java监视器模式 java监视器模式就是在将共享的数据封装在一个类里面,然后然后所有访问或者修改这些数据的方法都标注为synchronize. 车辆追踪模拟: 使用监视器模式: CarTracker ...
- DevExpress WPF v19.1新版亮点:Gantt/Map控件新功能
行业领先的.NET界面控件DevExpress 日前正式发布v19.1版本,本站将以连载的形式介绍各版本新增内容.在本系列文章中将为大家介绍DevExpress WPFv19.1中新增的一些控件及部分 ...
- React 错误处理(componentDidCatch)
前言 看react 文档突然发现有这个 错误处理函数,好像是17年9月出的,这个真的绝了可以帮助我们捕捉错误咯 React 16 将提供一个内置函数 componentDidCatch,如果 rend ...