Hadoop2.3+Hive0.12集群部署
0 机器说明
|
IP |
Role |
|
192.168.1.106 |
NameNode、DataNode、NodeManager、ResourceManager |
|
192.168.1.107 |
SecondaryNameNode、NodeManager、DataNode |
|
192.168.1.108 |
NodeManager、DataNode |
|
192.168.1.106 |
HiveServer |
1 打通无密钥
配置HDFS,首先就得把机器之间的无密钥配置上。我们这里为了方便,把机器之间的双向无密钥都配置上。
(1)产生RSA密钥信息
ssh-keygen -t rsa
一路回车,直到产生一个图形结构,此时便产生了RSA的私钥id_rsa和公钥id_rsa.pub,位于/home/user/.ssh目录中。
(2)将所有机器节点的ssh证书公钥拷贝至/home/user/.ssh/authorized_keys文件中,三个机器都一样。
(3)切换到root用户,修改/etc/ssh/sshd_config文件,配置:
RSAAuthentication yes
PubkeyAuthentication yes
AuthorizedKeysFile .ssh/authorized_keys
(4)重启ssh服务:service sshd restart
(5)使用ssh服务,远程登录:

ssh配置成功。
2 安装Hadoop2.3
将对应的hadoop2.3的tar包解压缩到本地之后,主要就是修改配置文件,文件的路径都在etc/hadoop中,下面列出几个主要的。
(1)core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/sdc/tmp/hadoop-${user.name}</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://192.168.1.106:9000</value>
</property>
</configuration>
(2)hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>192.168.1.107:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/sdc/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/sdc/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
(3)hadoop-env.sh
主要是将其中的JAVA_HOME赋值:
export JAVA_HOME=/usr/local/jdk1.6.0_27
(4)mapred-site.xml
<configuration>
<property>
<!-- 使用yarn作为资源分配和任务管理框架 -->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<!-- JobHistory Server地址 -->
<name>mapreduce.jobhistory.address</name>
<value>centos1:10020</value>
</property>
<property>
<!-- JobHistory WEB地址 -->
<name>mapreduce.jobhistory.webapp.address</name>
<value>centos1:19888</value>
</property>
<property>
<!-- 排序文件的时候一次同时最多可并行的个数 -->
<name>mapreduce.task.io.sort.factor</name>
<value>100</value>
</property>
<property>
<!-- reuduce shuffle阶段并行传输数据的数量 -->
<name>mapreduce.reduce.shuffle.parallelcopies</name>
<value>50</value>
</property>
<property>
<name>mapred.system.dir</name>
<value>file:/home/sdc/Data/mr/system</value>
</property>
<property>
<name>mapred.local.dir</name>
<value>file:/home/sdc/Data/mr/local</value>
</property>
<property>
<!-- 每个Map Task需要向RM申请的内存量 -->
<name>mapreduce.map.memory.mb</name>
<value>1536</value>
</property>
<property>
<!-- 每个Map阶段申请的Container的JVM参数 -->
<name>mapreduce.map.java.opts</name>
<value>-Xmx1024M</value>
</property>
<property>
<!-- 每个Reduce Task需要向RM申请的内存量 -->
<name>mapreduce.reduce.memory.mb</name>
<value>2048</value>
</property>
<property>
<!-- 每个Reduce阶段申请的Container的JVM参数 -->
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx1536M</value>
</property>
<property>
<!-- 排序内存使用限制 -->
<name>mapreduce.task.io.sort.mb</name>
<value>512</value>
</property>
</configuration>
注意上面的几个内存大小的配置,其中Container的大小一般都要小于所能申请的最大值,否则所运行的Mapreduce任务可能无法运行。
(5)yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>centos1:8080</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>centos1:8081</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>centos1:8082</value>
</property>
<property>
<!-- 每个nodemanager可分配的内存总量 -->
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>${hadoop.tmp.dir}/nodemanager/remote</value>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>${hadoop.tmp.dir}/nodemanager/logs</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>centos1:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>centos1:8088</value>
</property>
</configuration>
此外,配置好对应的HADOOP_HOME环境变量之后,将当前hadoop文件发送到所有的节点,在sbin目录中有start-all.sh脚本,启动可见:

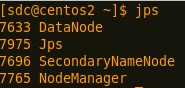

启动完成之后,有如下两个WEB界面:
http://192.168.1.106:8088/cluster

http://192.168.1.106:50070/dfshealth.html
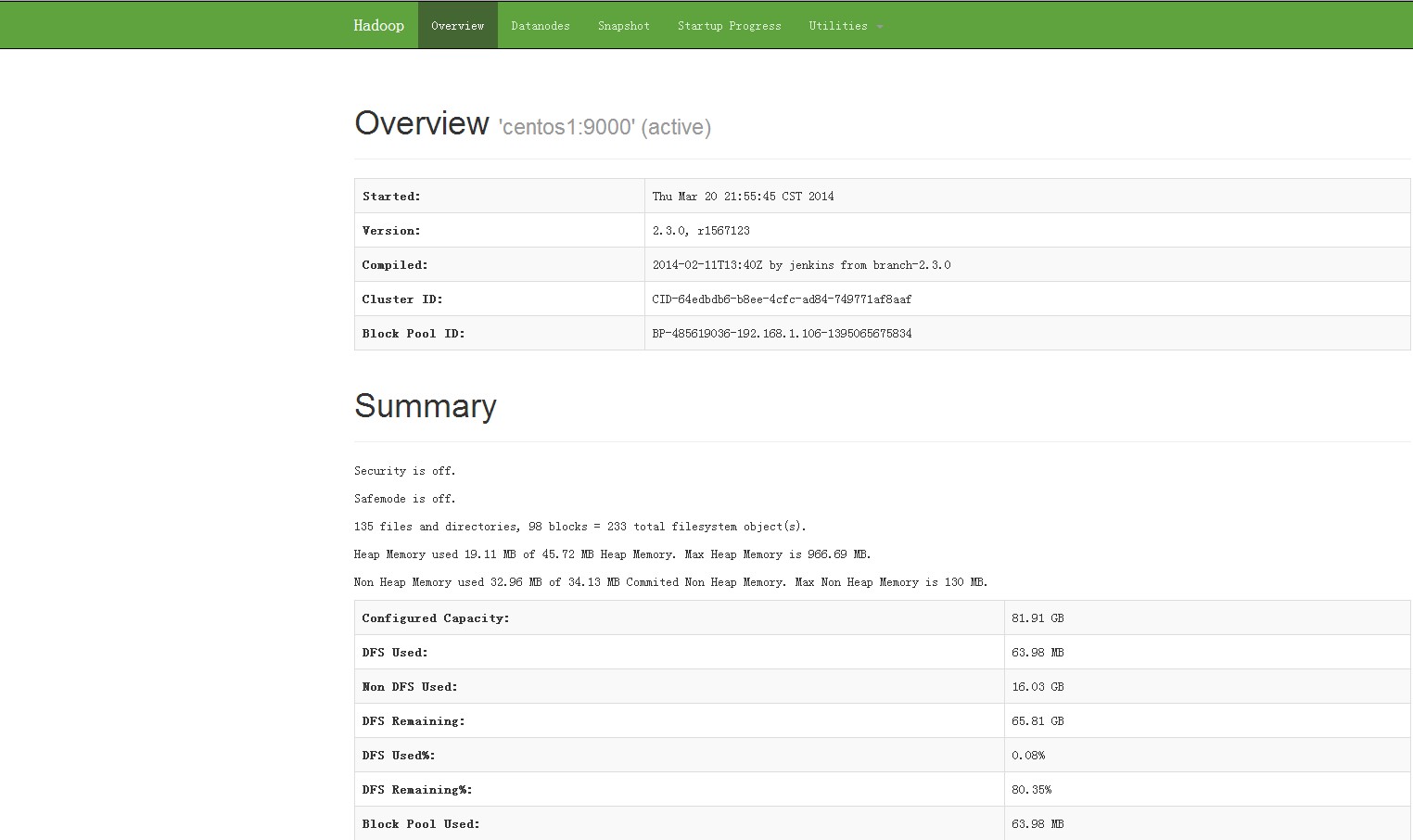
使用最简单的命令检查下HDFS:

3 安装Hive0.12
将Hive的tar包解压缩之后,首先配置下HIVE_HOME的环境变量。然后便是一些配置文件的修改:
(1)hive-env.sh
将其中的HADOOP_HOME变量修改为当前系统变量值。
(2)hive-site.xml
- 修改hive.server2.thrift.sasl.qop属性
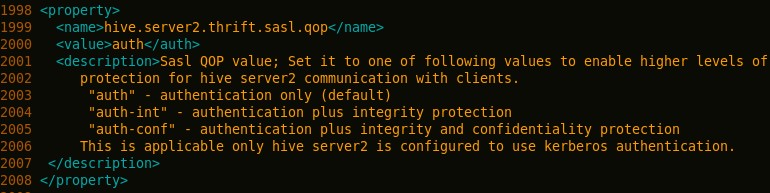
修改为:

- 将hive.metastore.schema.verification对应的值改为false
强制metastore的schema一致性,开启的话会校验在metastore中存储的信息的版本和hive的jar包中的版本一致性,并且关闭自动schema迁移,用户必须手动的升级hive并且迁移schema,关闭的话只会在版本不一致时给出警告。
- 修改hive的元数据存储位置,改为mysql存储:
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?characterEncoding=UTF-8</value>
<description>JDBC connect string for a JDBC metastore</description>
</property> <property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property> <property>
<name>javax.jdo.PersistenceManagerFactoryClass</name>
<value>org.datanucleus.api.jdo.JDOPersistenceManagerFactory</value>
<description>class implementing the jdo persistence</description>
</property> <property>
<name>javax.jdo.option.DetachAllOnCommit</name>
<value>true</value>
<description>detaches all objects from session so that they can be used after transaction is committed</description>
</property> <property>
<name>javax.jdo.option.NonTransactionalRead</name>
<value>true</value>
<description>reads outside of transactions</description>
</property> <property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>username to use against metastore database</description>
</property> <property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123</value>
<description>password to use against metastore database</description>
</property>
在bin下启动hive脚本,运行几个hive语句:

4 安装Mysql5.6
见http://www.cnblogs.com/Scott007/p/3572604.html
5 Pi计算实例、Hive表的计算实例运行
在Hadoop的安装目录bin子目录下,执行hadoop自带的示例,pi的计算,命令为:
./hadoop jar ../share/hadoop/mapreduce/hadoop-mapreduce-examples-2.3.0.jar pi 10 10
运行日志为:
Number of Maps = 10
Samples per Map = 10
14/03/20 23:50:04 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Wrote input for Map #0
Wrote input for Map #1
Wrote input for Map #2
Wrote input for Map #3
Wrote input for Map #4
Wrote input for Map #5
Wrote input for Map #6
Wrote input for Map #7
Wrote input for Map #8
Wrote input for Map #9
Starting Job
14/03/20 23:50:06 INFO client.RMProxy: Connecting to ResourceManager at centos1/192.168.1.106:8080
14/03/20 23:50:07 INFO input.FileInputFormat: Total input paths to process : 10
14/03/20 23:50:07 INFO mapreduce.JobSubmitter: number of splits:10
14/03/20 23:50:08 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1395323769116_0001
14/03/20 23:50:08 INFO impl.YarnClientImpl: Submitted application application_1395323769116_0001
14/03/20 23:50:08 INFO mapreduce.Job: The url to track the job: http://centos1:8088/proxy/application_1395323769116_0001/
14/03/20 23:50:08 INFO mapreduce.Job: Running job: job_1395323769116_0001
14/03/20 23:50:18 INFO mapreduce.Job: Job job_1395323769116_0001 running in uber mode : false
14/03/20 23:50:18 INFO mapreduce.Job: map 0% reduce 0%
14/03/20 23:52:21 INFO mapreduce.Job: map 10% reduce 0%
14/03/20 23:52:27 INFO mapreduce.Job: map 20% reduce 0%
14/03/20 23:52:32 INFO mapreduce.Job: map 30% reduce 0%
14/03/20 23:52:34 INFO mapreduce.Job: map 40% reduce 0%
14/03/20 23:52:37 INFO mapreduce.Job: map 50% reduce 0%
14/03/20 23:52:41 INFO mapreduce.Job: map 60% reduce 0%
14/03/20 23:52:43 INFO mapreduce.Job: map 70% reduce 0%
14/03/20 23:52:46 INFO mapreduce.Job: map 80% reduce 0%
14/03/20 23:52:48 INFO mapreduce.Job: map 90% reduce 0%
14/03/20 23:52:51 INFO mapreduce.Job: map 100% reduce 0%
14/03/20 23:52:59 INFO mapreduce.Job: map 100% reduce 100%
14/03/20 23:53:02 INFO mapreduce.Job: Job job_1395323769116_0001 completed successfully
14/03/20 23:53:02 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=226
FILE: Number of bytes written=948145
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=2670
HDFS: Number of bytes written=215
HDFS: Number of read operations=43
HDFS: Number of large read operations=0
HDFS: Number of write operations=3
Job Counters
Launched map tasks=10
Launched reduce tasks=1
Data-local map tasks=10
Total time spent by all maps in occupied slots (ms)=573584
Total time spent by all reduces in occupied slots (ms)=20436
Total time spent by all map tasks (ms)=286792
Total time spent by all reduce tasks (ms)=10218
Total vcore-seconds taken by all map tasks=286792
Total vcore-seconds taken by all reduce tasks=10218
Total megabyte-seconds taken by all map tasks=440512512
Total megabyte-seconds taken by all reduce tasks=20926464
Map-Reduce Framework
Map input records=10
Map output records=20
Map output bytes=180
Map output materialized bytes=280
Input split bytes=1490
Combine input records=0
Combine output records=0
Reduce input groups=2
Reduce shuffle bytes=280
Reduce input records=20
Reduce output records=0
Spilled Records=40
Shuffled Maps =10
Failed Shuffles=0
Merged Map outputs=10
GC time elapsed (ms)=710
CPU time spent (ms)=71800
Physical memory (bytes) snapshot=6531928064
Virtual memory (bytes) snapshot=19145916416
Total committed heap usage (bytes)=5696757760
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=1180
File Output Format Counters
Bytes Written=97
Job Finished in 175.556 seconds
Estimated value of Pi is 3.20000000000000000000
如果运行不起来,那说明HDFS的配置有问题啊!
Hive中执行count等语句,可以触发mapduce任务:
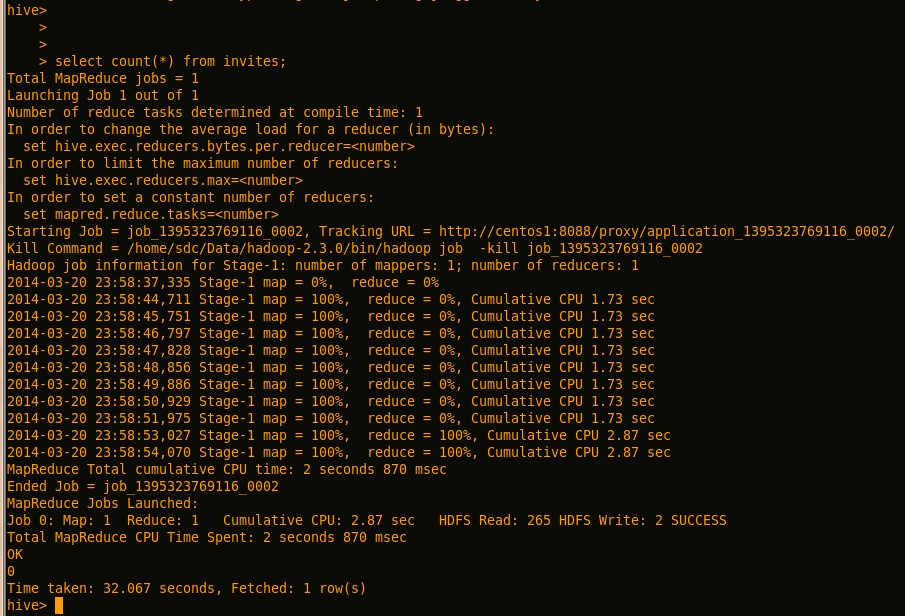
如果运行的时候出现类似于如下的错误:
Error in metadata: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.metastore.HiveMetaStoreClient
说明元数据存储有问题,可能是以下两方面的原因:
(1)HDFS的元数据存储有问题:
$HADOOP_HOME/bin/hadoop fs -mkdir /tmp
$HADOOP_HOME/bin/hadoop fs -mkdir /user/hive/warehouse
$HADOOP_HOME/bin/hadoop fs -chmod g+w /tmp
$HADOOP_HOME/bin/hadoop fs -chmod g+w /user/hive/warehouse
(2)Mysql的授权有问题:
在mysql中执行如下命令,其实就是给Mysql中的Hive数据库赋权
grant all on db.* to hive@'%' identified by '密码';(使用户可以远程连接Mysql)
grant all on db.* to hive@'localhost' identified by '密码';(使用户可以本地连接Mysql)
flush privileges;
具体哪方面的原因,可以查看hive的日志。
-------------------------------------------------------------------------------
如果您看了本篇博客,觉得对您有所收获,请点击右下角的 [推荐]
如果您想转载本博客,请注明出处
如果您对本文有意见或者建议,欢迎留言
感谢您的阅读,请关注我的后续博客
Hadoop2.3+Hive0.12集群部署的更多相关文章
- 超详细从零记录Hadoop2.7.3完全分布式集群部署过程
超详细从零记录Ubuntu16.04.1 3台服务器上Hadoop2.7.3完全分布式集群部署过程.包含,Ubuntu服务器创建.远程工具连接配置.Ubuntu服务器配置.Hadoop文件配置.Had ...
- HP DL160 Gen9服务器集群部署文档
HP DL160 Gen9服务器集群部署文档 硬件配置=======================================================Server Memo ...
- hbase高可用集群部署(cdh)
一.概要 本文记录hbase高可用集群部署过程,在部署hbase之前需要事先部署好hadoop集群,因为hbase的数据需要存放在hdfs上,hadoop集群的部署后续会有一篇文章记录,本文假设had ...
- Hadoop分布式集群部署(单namenode节点)
Hadoop分布式集群部署 系统系统环境: OS: CentOS 6.8 内存:2G CPU:1核 Software:jdk-8u151-linux-x64.rpm hadoop-2.7.4.tar. ...
- Hadoop教程(五)Hadoop分布式集群部署安装
Hadoop教程(五)Hadoop分布式集群部署安装 1 Hadoop分布式集群部署安装 在hadoop2.0中通常由两个NameNode组成,一个处于active状态,还有一个处于standby状态 ...
- Hadoop及Zookeeper+HBase完全分布式集群部署
Hadoop及HBase集群部署 一. 集群环境 系统版本 虚拟机:内存 16G CPU 双核心 系统: CentOS-7 64位 系统下载地址: http://124.202.164.6/files ...
- Hadoop记录-Apache hadoop+spark集群部署
Hadoop+Spark集群部署指南 (多节点文件分发.集群操作建议salt/ansible) 1.集群规划节点名称 主机名 IP地址 操作系统Master centos1 192.168.0.1 C ...
- Openfire 集群部署和负载均衡方案
Openfire 集群部署和负载均衡方案 一. 概述 Openfire是在即时通讯中广泛使用的XMPP协议通讯服务器,本方案采用Openfire的Hazelcast插件进行集群部署,采用Hapro ...
- 基于Tomcat的Solr3.5集群部署
基于Tomcat的Solr3.5集群部署 一.准备工作 1.1 保证SOLR库文件版本相同 保证SOLR的lib文件版本,slf4j-log4j12-1.6.1.jar slf4j-jdk14-1.6 ...
随机推荐
- linux系统的 suid/guid简单介绍 linux suid guid
我们在前面曾经提到过s u i d和g u i d.这种权限位近年来成为一个棘手的问题.很多系统供应商不允许实现这一位,或者即使它被置位,也完全忽略它的存在,因为它会带来安全性风险.那么人们为何如此大 ...
- 8.cadence.CIS[原创]
一.CIS数据库配置 ------ ---------------------------- --------------- ------------------ ---- 二.CIS放置元件 --- ...
- mongoDB使用复制还原数据库节省空间
用db.copyDatabase可以备份复制数据的方法. 1.db.copyDatabase("from","to","127.0.0.1:16161 ...
- git和其他版本控制系统的区别
所有除了Git以外的版本控制系统都使用增量存储方式来保存不同版本,而Git则在每一个commit时,保存一个整个文件的content copy,除非那个文件没有做过改动.Git和其他版本系统的主要区别 ...
- POJ 2524 (简单并查集) Ubiquitous Religions
题意:有编号为1到n的学生,然后有m组调查,每组调查中有a和b,表示该两个学生有同样的宗教信仰,问最多有多少种不同的宗教信仰 简单并查集 //#define LOCAL #include <io ...
- BZOJ 1787 紧急集合
LCA.注意细节. #include<iostream> #include<cstdio> #include<cstring> #include<algori ...
- LeetCode Valid Number 有效数字(有限自动机)
题意:判断一个字符串是否是一个合法的数字,包括正负浮点数和整形. 思路:有限自动机可以做,画个图再写程序就可以解决啦,只是实现起来代码的长短而已. 下面取巧来解决,分情况讨论: (1)整数 (2)浮点 ...
- cURL: PHP并发处理方式
function classic_curl($urls, $delay) { $queue = curl_multi_init(); $map = array(); foreach ($urls as ...
- 关于jsp利用EL和struts2标签来遍历ValueStack的东东 ------> List<Map<K,V>> 以及 Map<K,<List<xxx>>> 的结构遍历
//第一种结构Map<K,<List<xxx>>> <body> <% //显示map<String,List<Object>& ...
- 警惕VPS服务商常用的超售手段
任何商业企业都希望将利益最大化,这是可以理解的.但如果做的过火最终损害的还是自己的利益.VPS服务提供商也一样,为了将利益最大化,他们往往会实用技术手段对所出售的VPS进行“超售”. 那么何谓“超售” ...