2 深入分析 Java IO的工作机制(二)
2.5 I/O调优
- 下面总结一些磁盘I/O和网络I/O的常用优化技巧。
2.5.1 磁盘I/O优化
1. 性能检测
- 应用程序通常都需要访问磁盘来读取数据,而磁盘I/O通常都很耗时,要判断I/O是否是一个瓶颈,有一些参数指标可 以参考。
- 我们可以压力测试应用程序,看系统的I/O wait指标是否正常,例如,测试机器有4个CPU,那么理想的I/O wait参数不应该超过25%,如果超过25%,I/O可能成为应 用程序的性能瓶颈。在Linux操作系统下可以通过iostat命令查看。
- 通常我们在判断I/O性能时还会看到另外一个参数,就是IOPS,即要查看应用程序需要的最低的IOPS是多少,磁盘的 IOPS能不能达到要求。每个磁盘的IOPS通常在一个范围内,这和存储在磁盘上的数据块的大小和访问方式也有关,但主要是由磁盘的转速决定的,磁盘的转速越高,磁盘的IOPS也越高。
- 现在为了提升磁盘I/O的性能,通常采用一种叫作RAID的技术,就是将不同的磁盘组合起来以提高I/O性能,目前有多种RAID技术,每种RAID技术对I/O性能的提升会有不同,可以用一个RAID因子来代表,磁盘的读写吞吐量可以通过iostat命令来获取,于是可以计算出一个理论的IOPS值,计 算公式如下:
- (磁盘数 * 每块磁盘的IOPS)/(磁盘读的吞吐量 + RAID因子 * 磁盘写的吞吐量)= IOPS
2. 提升I/O性能
- 通常提升磁盘I/O性能的方法有:
- 增加缓存,减少磁盘访问次数。
- 优化磁盘的管理系统,设计最优的磁盘方式策略,以及磁盘的寻址策略,这是在底层操作系统层面考虑的。
- 设计合理的磁盘存储数据块,以及访问这些数据块的策略,这是在应用层面考虑的。例如,我们可以给存放的数据设计索引,通过寻址索引来加快和减少磁盘的访问量,还可以采用异步和非阻塞的方式加快磁盘的访问速度。
- 应用合理的RAID策略提升磁盘I/O,RAID策略及说明如表2-3所示。

2.5.2 TCP网络参数调优
要能够建立一个TCP连接,必须知道对方的IP和一个未被使用的端口号,由于32位操作系统的端口号通常由两个字节表示,也就是只有2^16=65535个,所以一台主机能够同时建立的连接数是有限的,当然操作系统还有一些端口0~1024是受保护的,如80端口、22端口,这些端口都不能被随意占用。
在Linux中可以通过查看/proc/sys/net/ipv4/ip_local_port_range文件来知道当前这个主机可以使用的端口范围,如图2-22所示。

图2-22表示可以使用的端口为61000-42768=18232。如果可以分配的端口号偏少,在遇到大量并发请求时就会成为瓶颈,由于端口有限导致大量请求等待建立连接,这样性能就会压不上去。另外如果发现有大量的TIME_WAIT的话,可以设置/proc/sys/net/ipv4/tcp_fin_timeout为更小的值来快速释放请求。我们通过另外一个主机ab -c 30 -n 1000000 10.232.101.208.8080/来压测这台机器,看看网络的连接情况,如图2-23所示。

可以看出TIME_WAIT的连接有26364个,我们设置sudo sh -c "echo 3 > /proc/sys/net/ipv4/tcp_fin_timeout"后再进行测试,如图2-24所示。

调整后TIME_WAIT的数量明显减少。除了增大端口范围之外,还可以让TCP连接复用等,这些调优参数如表2-4所示。
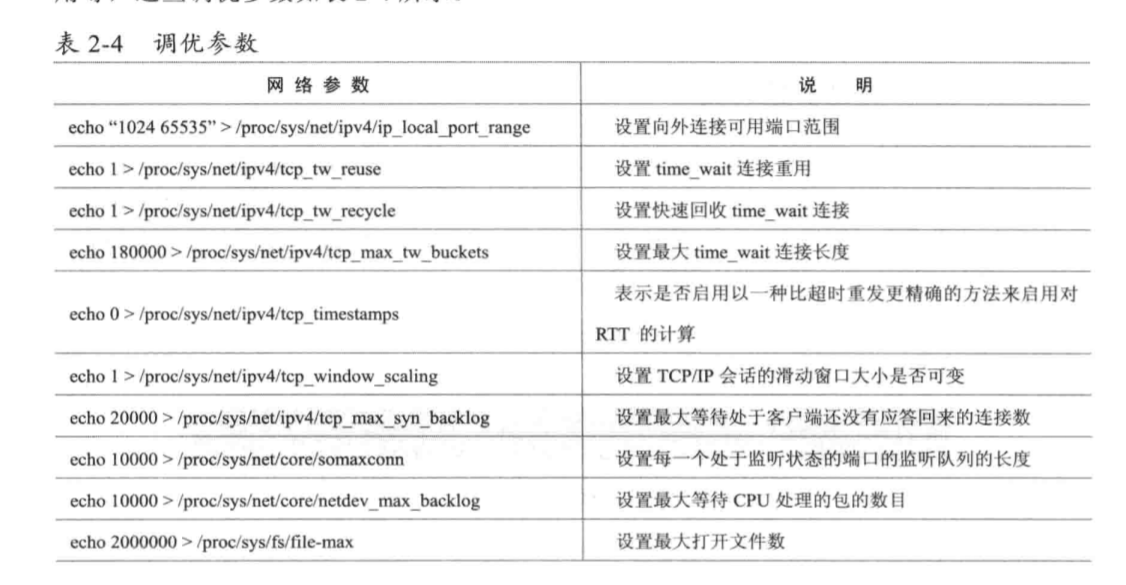

注意,以上设置都是临时性的,系统重新启动后就会丢失。另外iain,Linux还提供了一些工具可用于查看当前的TCP统计信息,如下所示。
- cat /proc/net/netstat: 查看TCP的统计信息
- cat /proc/net/snmp:查看当前系统的连接情况
- netstat -s:查看网络的统计信息
2.5.3 网络I/O优化
网络I/O优化通常有如下一些基本处理原则。
减少网络交互的次数。

减少网络传输数据量的大小。


尽量减少编码。

根据应用场景设计合适的交互方式。所谓的交互场景主要包括同步与异步、阻塞与非阻塞方式,下面进行详细介绍。
1. 同步与异步

2. 阻塞与非阻塞

3. 两种方式的组合
组合的方式有4钟,分别是同步阻塞、同步非阻塞、异步阻塞、异步非阻塞,如表2-5所示。

虽然异步和非阻塞能够提升I/O的性能,但是也会带来一些额外的性能成本,例如,会增加线程数量从而增加CPU的消耗,同时也会导致程序设计复杂度的上升。
下面举一些异步和阻塞的操作实例。
在Cassandra中要查询数据通常会向多个数据节点发送查询命令,但是要检查每个节点返回数据的完整性,就需要一个异步查询同步结果的应用场景,部分代码如下:
class AsyncResult implements IAsyncResult {
private byte[] result_;
private AtomicBoolean done = new AtomicBoolean(false);
private Lock lock_ = new ReentrentLock();
private Condition condition_;
private long startTime_;
public AsyncResult() {
condition_ = lock_.newCondition();//创建一个锁
startTime_ = System.currentTimeMillis();
}
//检查需要的数据是否已经返回,如果没有返回阻塞
public byte[] get() {
lock_.lock();
try {
if (!done_.get()) { condition_.await(); }
} catch (InterruptedException ex) {
throw new AssertionError(ex);
} finally { lock_.unlock(); }
return result_;
}
//检查需要的数据是否已经返回
public boolean isDone() { return done_.get();}
//检查在指定的时间内需要的数据是否已经返回,如果没有返回,抛出超时异常
public byte[] get (long timeout, TimeUnit tu) throws TimeoutException {
lock_.lock();
try {
boolean bVal = true;
try {
if ( !done_.get() ) {
long overall_timeout = timeout - (System.currentTimeMillis() - startTime_);
if (overall_timeout > 0) //设置等待超时的时间
bVal = condition_.await(overall_timeout, TimeUnit.MILLISECONDS);
else bVal = false;
}
} catch (InterruptedException ex) {
throw new AssertionError(ex);
}
if (!bVal && !done_.get()) { //抛出超时异常
throw new TimeoutException("Operation timed out.");
}
} finally { lock_.unlock(); }
return result_;
}
//该函数供另外一个线程设置要返回的数据,并唤醒在阻塞的线程
public void result(Message response) {
try {
lock_.lock();
if (!done_.get()) {
result_ = response.getMessageBody();//设置返回的数据
done_.set(true);
condition_.signal(); //唤醒阻塞的线程
}
} finally { lock_.unlock(); }
}
}
2 深入分析 Java IO的工作机制(二)的更多相关文章
- 2 深入分析 Java IO的工作机制(一)
大部分Web应用系统的瓶颈都是I/O瓶颈 2.1 Java的I/O类库的基本架构 Java的I/O操作类在包java.io下,大概有将近80个类,这些类大概可以分成如下4组. 基于字节操作的I/O接口 ...
- 深入分析Java I/O 工作机制
前言 : I/O 问题是Web 应用中所面临的主要问题之一.而且是任何编程语言都无法回避的问题,是整个人机交互的核心. java 的I/O类操作在java.io 包下,将近80个子类, 大概可以分成 ...
- 高级Java工程师必备 ----- 深入分析 Java IO (二)NIO
接着上一篇文章 高级Java工程师必备 ----- 深入分析 Java IO (一)BIO,我们来讲讲NIO 多路复用IO模型 场景描述 一个餐厅同时有100位客人到店,当然到店后第一件要做的事情就是 ...
- 高级Java工程师必备 ----- 深入分析 Java IO (三)
概述 Java IO即Java 输入输出系统.不管我们编写何种应用,都难免和各种输入输出相关的媒介打交道,其实和媒介进行IO的过程是十分复杂的,这要考虑的因素特别多,比如我们要考虑和哪种媒介进行IO( ...
- Java IO详解(二)------流的分类
一.根据流向分为输入流和输出流: 注意输入流和输出流是相对于程序而言的. 输出:把程序(内存)中的内容输出到磁盘.光盘等存储设备中 输入:读取外部数据(磁盘.光盘等存储设备的数据)到程序(内 ...
- java I/O工作机制
java I/O 的基本架构: 1:基于字节操作的I/O接口 InputStream OutputStream 2:基于字符操作的I/O接口 Writer 和Reader 3:基于磁盘操作的I/O接口 ...
- Java I/O 工作机制(一) —— Java 的 I/O 类库的基本架构
Java 的 I/O 类库的基本架构 Java 的 I/O 操作类在包 java.io 下,有将近 80 个类. 按数据格式分类: 面向字节(Byte)操作的 I/O 接口:InputStream 和 ...
- 浅说Java中的反射机制(二)
写过一篇Java中的反射机制,不算是写,应该是抄了,因为那是别人写的,这一篇也是别人写的,摘抄如下: 引自于Java基础--反射机制的知识点梳理,作者醉眼识朦胧.(()为我手记) 什么是反射? 正常编 ...
- Java io流详解二
原文地址https://www.cnblogs.com/xll1025/p/6418766.html 一.IO流概述 概述: IO流简单来说就是Input和Output流,IO流主要是用来处理设备之间 ...
随机推荐
- Spring Boot2 系列教程(一) | 如何使用 IDEA 构建 Spring Boot 工程
微信公众号:一个优秀的废人 如有问题或建议,请后台留言,我会尽力解决你的问题. Search 前言 新年立了个 flag,好好运营这个公众号.具体来说,就是每周要写两篇文章在这个号发表.刚立的 fla ...
- 求二叉树的深度,从根节点到叶子节点的最大值,以及最大路径(python代码实现)
首先定义一个节点类,包含三个成员变量,分别是节点值,左指针,右指针,如下代码所示: class Node(object): def __init__(self, value): self.value ...
- 【转】oracle条件子句执行顺序
Oracle WHERE条件执行顺序:ORACLE采用自下而上的顺序解析WHERE子句 1.据此那些可以过滤掉最大数量记录的条件必须写在WHERE子句的末尾例如:SELECT … FROM EMP E ...
- ELK学习实验018:filebeat收集docker日志
Filebeat收集Docker日志 1 安装docker [root@node4 ~]# yum install -y yum-utils device-mapper-persistent-data ...
- 使用Robot Framework框架远程操作UNIX系统
bot Framework是一个强大的自动化测试框架,依靠社区力量编写的Test Library为它提供了非常强的扩展性.下面我将介绍的就是如何使用第三方提供的扩展测试库(Test Library)来 ...
- Django 连接mysql 踩过的坑
1.创建数据库 2.在Django项目文件下的settings.py配置数据库 3.在Django项目__init__.py文件中,用pymysql代替MySqlDB import pymysql p ...
- spring Cloud-eureka的保护模式
eureka的首页出现以下警告 EMERGENCY! EUREKA MAY BE INCORRECTLY CLAIMING INSTANCES ARE UP WHEN THEY'RE NOT. REN ...
- [洛谷P3621] [APIO2007] 风铃
Description 你准备给弟弟 Ike 买一件礼物,但是,Ike 挑选礼物的方式很特别:他只喜欢那些能被他排成有序形状的东西. 你准备给 Ike 买一个风铃.风铃是一种多层的装饰品,一般挂在天花 ...
- 个人任务day6
今日计划: 学会将网页放到公用网络上,并生成快捷方式. 昨日成果:完成登录页面.
- 生成URL(而不是链接) Generating URLs (and Not Links) | 在视图中生成输出URL |高级路由特性 | 精通ASP-NET-MVC-5-弗瑞曼
结果呢: