16_TLB与流水线
1 前面做的实验起始有缺陷
访问内存之后,后面执行两句代码后;并不能保证刚才访问的代码还在TLB中;有可能被刷新出去了;
实验验证缺陷:
代码 不连续 TLB 被淘汰:
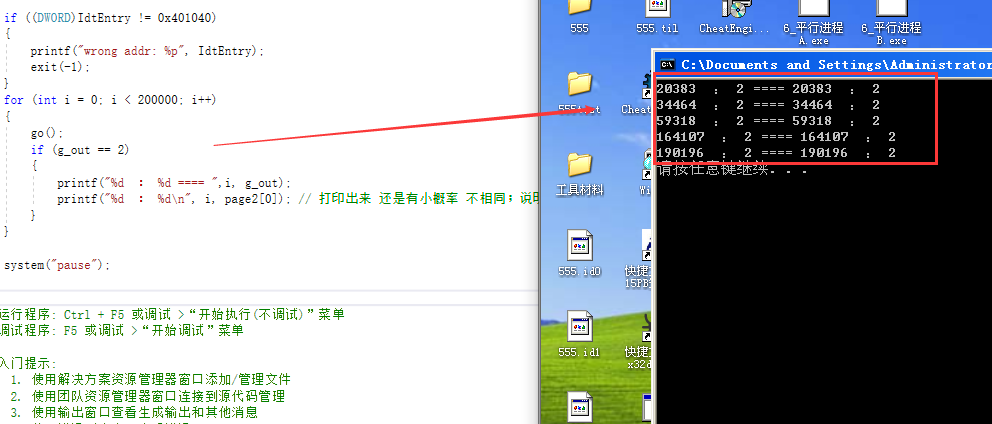
2万次中有1次被淘汰;由于访问代码不连续
代码:
// 7_TLB_test.cpp : 此文件包含 "main" 函数。程序执行将在此处开始并结束。
//
#include "pch.h"
#include<stdio.h>
#include<stdlib.h>
#include<Windows.h>
#define PTE(x) ( (DWORD*)(0xc0000000 + ((x >> 12) << 3)))
#define PDE(X) ( (DWORD*)(0xc0600000 + ((x >> 21) << 3)))
DWORD g_out;
DWORD g_OldPte[2];
#pragma section("data seg", read, write)
_declspec(allocate("data seg"))DWORD pagel[1024]; //41d000
_declspec(allocate("data seg"))DWORD page2[1024]; //41c000
//0x401000
void _declspec(naked) IdtEntry()
{
// 保存旧的pte ,以用来恢复pte 解决不蓝屏
g_OldPte[0] = PTE(0x41c000)[0];
g_OldPte[1] = PTE(0x41c000)[1];
PTE(0x41c000)[0] = PTE(0x41d000)[0];// 不设置G位
PTE(0x41c000)[1] = PTE(0x41d000)[1];
__asm invlpg ds : [0x41c000] // 带有 g 位的刷新;
// 刷新虚拟地址在TLB中
__asm
{
mov eax, ds: [0x41c000];// 这个时候到快表中了 TLB[0x41c000] 中的值因该是 1;
}
// pte 修改回来,但是TLB 中存在所以应该还是 1
PTE(0x41c000)[0] = g_OldPte[0];
PTE(0x41c000)[1] = g_OldPte[1];
__asm
{
mov eax,ds:[0x41c000]
mov g_out,eax
} // 如果前面访问之后还在快表中,那么这里应该是 [0x41d000] 中的 1;
// 如果不再快表中了 那么是修改回来的 ,本来的 [0x41c000] 中的 2;
/*__asm {
mov eax, cr3
mov cr3, eax
}*/
__asm invlpg ds : [0x41c000] // 带有 g 位的刷新;
//// 调用调用;确保在 TL B 中
//__asm mov eax, ds:[0x41c000];
//// 恢复到原来的pte
////---- 这样
//// 按道理 后面一旦后面刷新 TLB 将 普通 TLB 刷新出去,
//// 那么 g_out = page2[0] 的值就 应该是 正常 的原 pte 对应的数据 -- 2。
//PTE(0x41c000)[0] = g_OldPte[0];
//PTE(0x41c000)[1] = g_OldPte[1];
//__asm
//{
//mov eax, cr3
//mov cr3, eax
//}
//g_out = page2[0]; // 讲道理 在非G位下 应该是2(原PTE解析出的) -- 但是这里我们设置了PTE 的G位,
// // so 这里应该是 TLB快表中 对应的 1;
__asm {
iretd
}
}
void _declspec(naked) go() {
{
pagel[0] = 1; //确保物理页存在
page2[0] = 2;
}
__asm int 0x20
__asm ret
}
//eq 8003f500 0040ee00~ 00081000
void main()
{
if ((DWORD)IdtEntry != 0x401040)
{
printf("wrong addr: %p", IdtEntry);
exit(-1);
}
for (int i = 0; i < 200000; i++)
{
go();
if (g_out == 2)
{
printf("%d : %d ==== ",i, g_out);
printf("%d : %d\n", i, page2[0]); // 打印出来 还是有小概率 不相同;说明还是在快表中的。
}
}
system("pause");
}
G位即使存在 访问代码不连续也可能被淘汰:
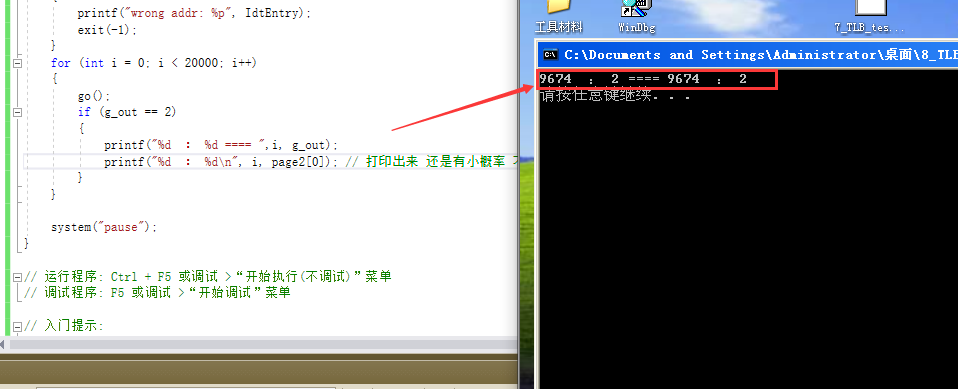
我这里循环了20000次 ,有1次G位即使在也被TLB淘汰了。
代码:
// 7_TLB_test.cpp : 此文件包含 "main" 函数。程序执行将在此处开始并结束。
//
#include "pch.h"
#include<stdio.h>
#include<stdlib.h>
#include<Windows.h>
#define PTE(x) ( (DWORD*)(0xc0000000 + ((x >> 12) << 3)))
#define PDE(X) ( (DWORD*)(0xc0600000 + ((x >> 21) << 3)))
DWORD g_out;
DWORD g_OldPte[2];
#pragma section("data seg", read, write)
_declspec(allocate("data seg"))DWORD pagel[1024]; //41d000
_declspec(allocate("data seg"))DWORD page2[1024]; //41c000
//0x401000
void _declspec(naked) IdtEntry()
{
// 保存旧的pte ,以用来恢复pte 解决不蓝屏
g_OldPte[0] = PTE(0x41c000)[0];
g_OldPte[1] = PTE(0x41c000)[1];
PTE(0x41c000)[0] = PTE(0x41d000)[0]| 0x100;// 设置G位
PTE(0x41c000)[1] = PTE(0x41d000)[1];
__asm invlpg ds : [0x41c000] // 带有 g 位的刷新;
// 刷新虚拟地址在TLB中
__asm
{
mov eax, ds: [0x41c000];// 这个时候到快表中了 TLB[0x41c000] 中的值因该是 1;
}
// pte 修改回来,但是TLB 中存在所以应该还是 1
PTE(0x41c000)[0] = g_OldPte[0];
PTE(0x41c000)[1] = g_OldPte[1];
__asm
{
mov eax,ds:[0x41c000]
mov g_out,eax
} // 如果前面访问之后还在快表中,那么这里应该是 [0x41d000] 中的 1;
// 如果不再快表中了 那么是修改回来的 ,本来的 [0x41c000] 中的 2;
//__asm invlpg ds : [0x41c000] // 带有 g 位的刷新;即前面如果还在快表中,这里刷新pte再返回3环程序后再次输出。做测试用的没有意义了。
__asm {
iretd
}
}
void _declspec(naked) go() {
{
pagel[0] = 1; //确保物理页存在
page2[0] = 2;
}
__asm int 0x20
__asm ret
}
//eq 8003f500 0040ee00~ 00081000
void main()
{
if ((DWORD)IdtEntry != 0x401040)
{
printf("wrong addr: %p", IdtEntry);
exit(-1);
}
for (int i = 0; i < 20000; i++)
{
go();
if (g_out == 2)
{
printf("%d : %d ==== ",i, g_out);
printf("%d : %d\n", i, page2[0]); // 打印出来 还是有小概率 不相同;说明还是在快表中的。
}
}
system("pause");
}
总结: 注意啊 ::: 切换 cr3 刷新TLB G位的 无影响; 得 使用
__asm invlpg ds : [0x41c000] // 无视 g 位的刷新;
3 流水线指令TLB 和数据TLB 得相互影响
前置知识 : 如果我们的页面没有可执行属性的话;在没有TLB中时,我们修改pte后,第一次访问 绝对时修改pte之后的对应的物理页数据;但是如果有可执行属性,那么在cpu 流水线 技术( 执行指令的时候,也在取指令,且根据将会执行的可能性提前取指令):

现象:
没有 可执行属性的时候;且没有主动加入快表的时候;坑定 是可预计的数据:
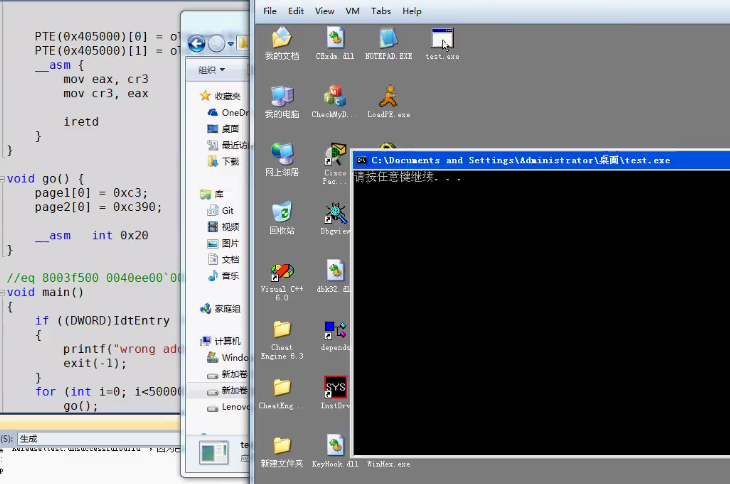
但是 一旦加入了可执行属性,流水线的预先取指令,可能执行到这儿,取后面的指令:
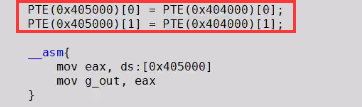
发现后面的指令有 0x405000 ,而且 0x405000 有可执行属性,可能就预先取了这个指令;继而访问;加入了TLB。 (但是即使这样这里也是指令TLB ,但是这里影响到了 数据TLB,但是概率也不高)
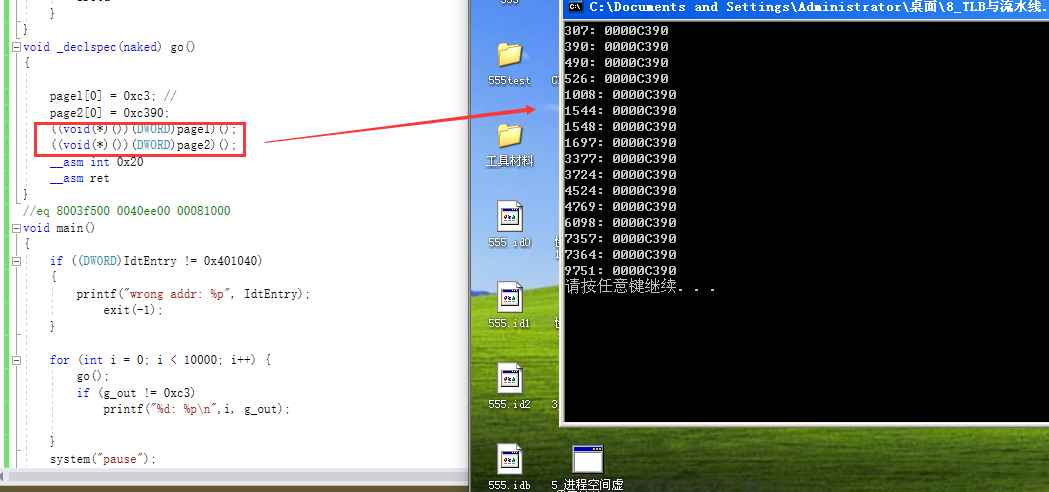
代码:
#include "pch.h"
#include<stdio.h>
#include<stdlib.h>
#include<Windows.h>
#define PTE(x) ( (DWORD*)(0xc0000000 + ((x >> 12) << 3)))
#define PDE(X) ( (DWORD*)(0xc0600000 + ((x >> 21) << 3)))
DWORD g_out;
DWORD g_OldPte[2];
#pragma section("data seg", read, write)
_declspec(allocate("data seg"))DWORD pagel[1024]; //41d000
_declspec(allocate("data seg"))DWORD page2[1024]; //41c000
//0x401000
void _declspec(naked) IdtEntry()
{
// 保存旧的pte ,以用来恢复pte 解决不蓝屏
g_OldPte[0] = PTE(0x41c000)[0];
g_OldPte[1] = PTE(0x41c000)[1];
__asm{
mov eax,cr3
mov cr3,eax
}
//__asm mov eax, ds :[0x41b000]
PTE(0x41c000)[0] = PTE(0x41d000)[0];
PTE(0x41c000)[1] = PTE(0x41d000)[1];
__asm {
mov eax, ds :[0x41c000]
mov g_out, eax
}
PTE(0x41c000)[0] = g_OldPte[0];
PTE(0x41c000)[1] = g_OldPte[1];
_asm {
mov eax, cr3
mov cr3, eax
iretd
}
}
void _declspec(naked) go()
{
pagel[0] = 0xc3; //
page2[0] = 0xc390;
((void(*)())(DWORD)pagel)();
((void(*)())(DWORD)page2)();
__asm int 0x20
__asm ret
}
//eq 8003f500 0040ee00 00081000
void main()
{
if ((DWORD)IdtEntry != 0x401040)
{
printf("wrong addr: %p", IdtEntry);
exit(-1);
}
for (int i = 0; i < 10000; i++) {
go();
if (g_out != 0xc3)
printf("%d: %p\n",i, g_out);
}
system("pause");
}
16_TLB与流水线的更多相关文章
- CI-持续集成(1)-软件工业“流水线”概述
CI-持续集成(1)-软件工业“流水线”概述 1 概述 持续集成(Continuous integration)是一种软件开发实践,即团队开发成员经常集成它们的工作,通过每个成员每天至少集成一次, ...
- 【GoLang】golang 的精髓--流水线,对现实世界的完美模拟
直接上代码: package main import ( "fmt" "runtime" "strconv" "sync" ...
- android so调试时遇到的坑 - arm流水线
直接看下面这段ARM汇编: 此时运行到的代码为ADD R3,PC 此时看一下寄存器窗口的值: 按理来说执行完ADD R3,PC后的效果应该是R3=R3+PC ,R3=40A1D5C8 但是我们可以执行 ...
- 【转载】关于OpenGL的图形流水线
本文转载自 http://blog.csdn.net/racehorse/article/details/6593719 GLSL教程 这是一些列来自lighthouse3d的GLSL教程,非常适合入 ...
- .Net中的并行编程-5.流水线模型实战
自己在Excel整理了很多想写的话题,但苦于最近比较忙(其实这是借口).... 上篇文章<.Net中的并行编程-4.实现高性能异步队列>介绍了异步队列的实现,本篇文章介绍我实际工作者遇到了 ...
- Intel系列CPU的流水线技术的发展
Intel系列CPU的流水线技术的发展 CPU(Central processing Unit),又称“微处理器(Microprocessor)”,是现代计算机的核心部件.对于PC而言,CPU的规格与 ...
- Verilog学习笔记设计和验证篇(一)...............总线和流水线
总线 总线是运算部件之间数据流通的公共通道.在硬线逻辑构成的运算电路中只要电路的规模允许可以比较自由的确定总线的位宽,从而大大的提高数据流通的速度.各个运算部件和数据寄存器组可以通过带有控制端的三态门 ...
- ARM流水线关键技术分析与代码优化
引 言 流水线技术通 过多个功能部件并行工作来缩短程序执行时间,提高处理器核的效率和吞吐率,从而成为微处理器设计中最为重要的技术之一.ARM7处理器核使用了典型三级流 水线的冯·诺伊曼结构,AR ...
- TMS320C54x系列DSP的CPU与外设——第8章 流水线
第8章 流水线 本章描述了TMS320C54x DSP流水线的操作,列出了对不同寄存器操作时的流水线延迟周期.(对应英语原文第7章) 8.1 流水线操作 TMS320C54x DSP有一个6段的指令流 ...
随机推荐
- jumpserver3.0安装
由于来源身份不明.越权操作.密码泄露.数据被窃.违规操作等因素都可能会使运营的业务系统面临严重威胁,一旦发生事故,如果不能快速定位事故原因,运维人员往往就会背黑锅.几种常见的运维人员背黑锅场景:1)由 ...
- zabbix--External checks 外部命令检测
概述zabbix server 运行脚本或者二进制文件来执行外部检测,外部检测不需要在被监控端运行任何 agentditem key 语法如下: 参数 定义 script shell 脚本或者二进制文 ...
- moment.js 快捷查询
格式化日期 当前时间: moment().format('YYYY-MM-DD HH:mm:ss'); //2014-09-24 23:36:09 今天是星期几: moment().format('d ...
- 在Ubuntu下安装deb包需要使用dpkg命令
Dpkg 的普通用法: 1.sudo dpkg -i <package.deb> 安装一个 Debian 软件包,如你手动下载的文件. 2.sudo dpkg -c <package ...
- MYSQL-连续出现的数字
编写一个 SQL 查询,查找所有至少连续出现三次的数字. +----+-----+| Id | Num |+----+-----+| 1 | 1 || 2 | 1 || 3 | 1 || 4 | 2 ...
- Collections 工具类常见方法
Collections 工具类常用方法: 排序 查找,替换操作 同步控制(不推荐,需要线程安全的集合类型时请考虑使用 JUC 包下的并发集合) 排序操作 void reverse(List list) ...
- delphi 打印 PDevMode 说明
//PDevMode = _devicemodeW;// _devicemodeW = record// dmDeviceName: array[0..CCHDEVICENAME - 1] of Wi ...
- 【Flutter学习】基本组件之基本按钮组件
一,概述 由于Flutter是跨平台的,所以有适用于Android和iOS的两种风格的组件.一套是Google极力推崇的Material,一套是iOS的Cupertino风格的组件.无论哪种风格,都是 ...
- 管理员技术(四): 配置NTP网络时间客户端、 创建一个备份包、 配置用户和组账号、配置一个cron任务
一. 配置NTP网络时间客户端 目标: 本例要求配置虚拟机 server0,能够自动校对系统时间.相关信息如下: 1> NTP服务器位于 classroom.example.com ...
- NYOJ 301 递推求值
第一次写博客,拿个矩阵快速幂练练手吧. 首先什么是快速幂,快速幂是让复杂度由线性降为log n的算法,比如8^1024次方暴力要算1024次,但是矩阵快速幂只算10次就好. 此题只不过是把快速幂的底数 ...