【设计】schema
- 在数据建模的基础上将关系模型转为数据库表
- 满足业务模型需要基础上根据数据库和应用特点优化表结构
.png)
- 满足业务功能需求
- 同性能密切相关
- 数据库扩展性
- 满足周边需求(统计,迁移等)
- 着眼于实现当前功能
- 完全基于功能的设计可能存在一些隐患
- 不合理的表结构或索引设计造成性能问题
- 没有合理评估到数据量的增长造成空间紧张而且难以维护
- 需求频繁修改造成表结构经常变更
- 业务重大调整导致数据经常需要重构订正
- 根据查询需要设计好索引
- 根据核心查询需求, 适当调整表结构
- 基于一些特殊业务需求,调整实现方式
- 正确使用索引
- 更新尽可能使用主键或唯一索引
- 主键尽可能使用自增ID字段
- 核心查询使用覆盖索引
- 用户登录需要根据用户名返回密码用于验证
- create index idx_uname_passwd on tb_user (username,passwd);
- 建立联合索引避免回表取数据
.png)
.png)
.png)

.png)
.png)

.png)
.png)
.png)
.png)
.png)

.png)


.png)
.png)

.png)

.png)

.png)

.png)
- 基于历史经验教训,预防和解决同类问题
- 把折腾DBA够呛的索引Schema改造的原因记录并分析总结
- 数据库结果大量改动,增加了加密字段,验证策略表,所有表重新订正数据等等
- 是否所有用到用户信息管理的应用都要去上线就用密文?

- schema设计关系性能
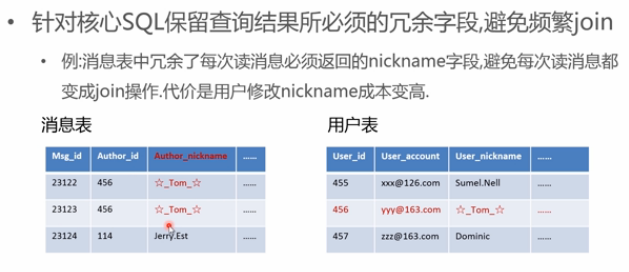
- 反范式,冗余必要字段
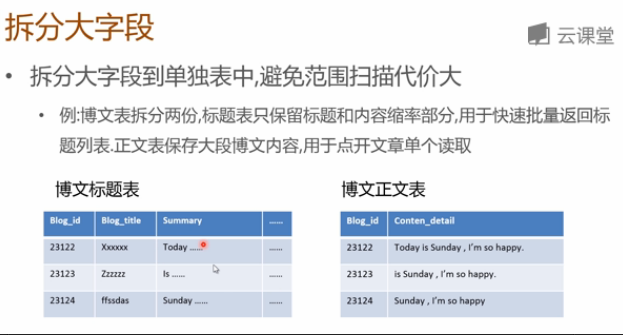
- 拆分大字段
- 避免过多字段或过长字段
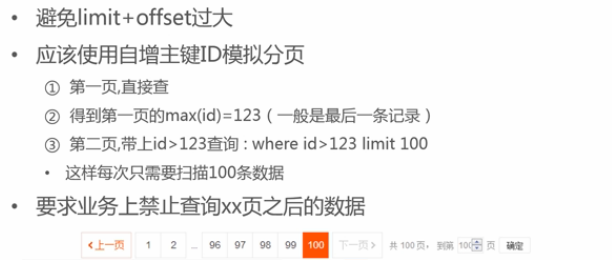
- 分页查询
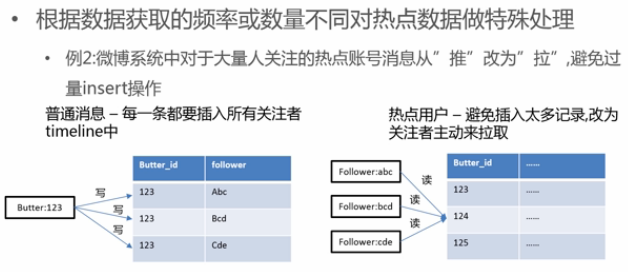
- 热点读数据特殊处理:置顶表与普通表分开
- 热点写数据特殊处理:
- 微博普通用户发消息,则写入关注他的人的消息列表中;微博大V发消息,则关注他的人都去读他的消息列表;
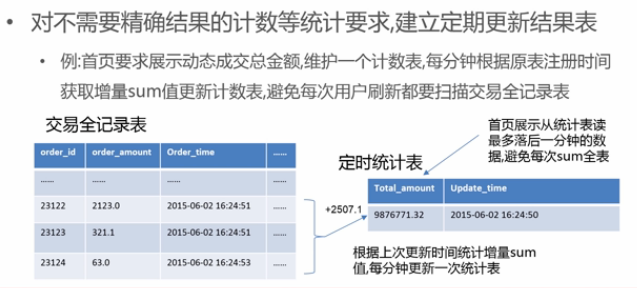
- 准实时统计:
- 定时统计表,更据上次更新时间统计全表中增量sum值,每分钟更新统计表;
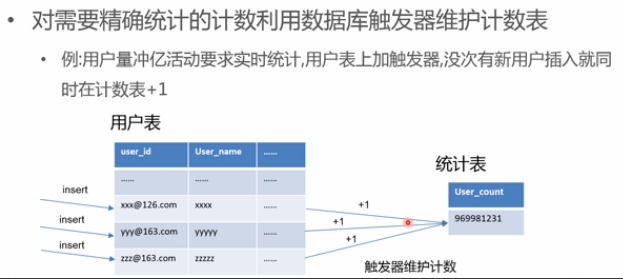
- 实时统计:
- 触发器实时统计,在用户插入时,更新统计表;
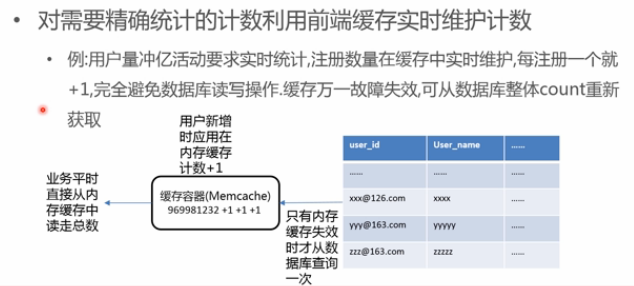
- 缓存实时统计,应用将用户新增写在内存缓存中,业务平时从缓存中读,缓存失效,从数据库做一次查询,接着写在缓存;
- 分区表与数据淘汰
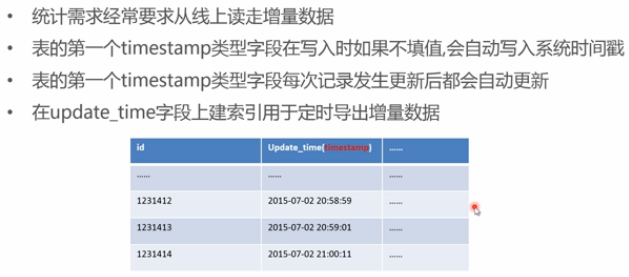
- 满足周边需求:
- 如后台统计任务而增加特殊索引,
- 为数据迁移或统计增加时间戳
- 自动更新时间戳
- schema设计与前瞻性
【设计】schema的更多相关文章
- BizTalk开发系列(十二) Schema设计之Group与Order
开发BizTalk项目的时候会先约定各系统之间往来的消息格式. 由于BizTalk内部唯一使用XML文档.因此消息的格式为XML Schema(XML Schema 用于描述 XML 文档的结构).虽 ...
- schema设计
Schema设计 Schema:表的模式: 设计数据的表,索引,以及表和表的关系 在数据建模的基础上将关系模型转为数据库表 满足业务模型需要基础上根据数据库和应用特点优化表结构 关系模型图 ...
- Design7:数据删除设计
在设计一个新系统的Table Schema的时候,不仅需要满足业务逻辑的复杂需求,而且需要考虑如何设计schema才能更快的更新和查询数据,减少维护成本. 模拟一个场景,有如下Table Schema ...
- Schema与数据类型优化
良好的逻辑设计和物理设计是高性能的基石,应该根据系统将要执行的查询数据来设计schema,这往往需要权衡各种因素. MySQL支持的数据类型非常多,选择正确的数据类型对于获得高性能至关重要. 更小的通 ...
- NOSQL schema创建原则
(1)数据规模 Bigtable类数据库系统(HBase,Cassandra等)是为了解决海量数据规模的存储需要设计的.这里说的海量数据规模指的是单个表存储的数据量是在TB或者PB规模,单个表是由千亿 ...
- MySQL 数据库设计的“奥秘”
2 MySQL 数据库设计的"奥秘" [主题]逻辑设计:数据类型与 Schema 所谓"万丈高楼平地起",一个稳固的建筑离不开扎实的基础.同样,良好的的「逻辑设 ...
- MySQL Schema 与数据类型优化
良好的逻辑设计和物理设计是高性能的基石,应该根据系统将要执行的查询语句来设计schema,这往往需要权衡各种因素. 例如,反范式的设计可以加快某些类型的查询,但同时可能使另一些类型的查询变慢:添加计数 ...
- Redis的使用场景 by 杨卫华
转载自新浪微博架构师杨卫华的博客 http://timyang.net/tag/redis/,省略了部分内容 按:杨卫华在2010年就已经测试了Redis的性能,并给出了初步的结论:“Redis性能惊 ...
- NoSQL数据库笔谈(转)
NoSQL数据库笔谈 databases , appdir , node , paper颜开 , v0.2 , 2010.2 序 思想篇 CAP 最终一致性 变体 BASE 其他 I/O的五分钟法则 ...
- umf(转)
深入浅出Eclipse Modeling Framework (EMF) Eclipse Modeling Framework (EMF),简单的说,就是Eclipse提供的一套建模框架,可以用EMF ...
随机推荐
- 【学术篇】CF932E Team Work && bzoj5093 图的价值
两个题的传送门 对于CF这道题, 分别考虑每种可能的集合大小, 每个大小为\(k\)的集合数量有\(\binom nk\)个, 所以最后的答案就是 \[\sum_{i=0}^n\binom{n}{i} ...
- js 单行间隙滚动
代码: <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3. ...
- 数组循环移动 空间复杂度O(1)
---恢复内容开始--- 题目大意: 输入元素个数,输入数组,输入右移步数,输出结果: 基本思路: 可以把数组(从下标为0开始存储)看成两部分,分别是[0,n-step-1],[n-step,n-1] ...
- HttpClient异常处理手册
HttpClient异常处理手册 开源中国 发表于 2014-08-26 19:44:06 异常处理 HttpClient的使用者在执行HTPP方法(GET,PUT,DELETE等),可能遇到会两种主 ...
- Kafka速览
一.基本结构 三台机器组成的Kafka集群,每台机器启动一个Kafka进程,即Broker 向broker发送消息的客户端是Producer,拉取消息的客户端是Consumer Producer和Co ...
- Java虚拟机(一)
一.Java发展历程 Java之父,James Gosling博士 时间 事件 1991年4月 James Gosling博士领导的Green Project启动,java语言前身Oak启动 1995 ...
- leetcood学习笔记-14*-最长公共前缀
笔记: python if not 判断是否为None的情况 if not x if x is None if not x is None if x is not None`是最好的写法,清晰,不 ...
- java中设置http响应头控制浏览器禁止缓存当前文档内容
response.setDateHeader("expries", -1); response.setHeader("Cache-Control", " ...
- 随机生成一串字符串(java)
该随笔为开发笔记 今天在公司接手了一个项目,在看该项目老代码时,发现上一位大佬写的随机取一串字符串还不错,在此做一次开发笔记 在他的基础上我做了点改动,但是原理一样 /** * 随机取一段字符串方法1 ...
- Delphi 虚拟桌面
Delphi创建虚拟桌面实现后台调用外部程序 核心提示:最近在做的一个软件,其中有一部分功能需要调用其它的软件来完成,而那个软件只有可执行文件,根本没有源代码,幸好,我要做的事不难,只需要在我的程序启 ...