Alibaba Cluster Data 开源:270GB 数据揭秘你不知道的阿里巴巴数据中心
打开一篇篇 IT 技术文章,你总能够看到“大规模”、“海量请求”这些字眼。如今,这些功能强大的互联网应用,都运行在大规模数据中心上,然而,对于大规模数据中心,你又了解多少呢?实际上,除了阅读一些科技文章之外,你很难得到更多关于数据中心的信息。数据中心每个机器的运行情况如何?这些机器上运行着什么样的应用?这些应用有有什么特点?对于这些问题,除了少数资深从业者之外,普通学生和企业的研究者很难了解其中细节。
1 什么是Alibaba Cluster Data?
2015 年,我们尝试在阿里巴巴的数据中心,将延迟不敏感的批量离线计算任务和延迟敏感的在线服务部署到同一批机器上运行,让在线服务用不完的资源充分被离线使用以提高机器的整体利用率。经过 3 年多的试验论证、架构调整和资源隔离优化,目前这个方案已经走向大规模生产。我们通过混部技术将集群平均资源利用率从 10% 大幅度提高到 45%。另外,通过各种优化手段,可以让更多任务运行在数据中心,将“双11”平均每万笔交易成本下降了 17%,等等。

那么,实施了一系列优化手段之后的计算机集群究竟是什么样子?混部的情况究竟如何?除了文字性的介绍,直接发布数据能够更加拉近我们与学术研究、业界同行之间的距离。为了让有兴趣的学生以及相关研究人员,可以从数据上更加深入地理解大规模数据中心,我们特别发布了这份数据集。数据集中记录了某个生产集群中服务器以及运行任务的详细情况。在数据集中,你可以详细了解到我们是如何通过混部把资源利用率提高到 45%;我们每天到底运行了多少任务;以及业务的资源需求有什么特点,等等。如何使用这份数据集,完全取决于你的需要。
2 你用这个数据可以做什么?
刚刚发布的 Alibaba Cluster Data V2018 包含 6 个文件,压缩后大小近 50GB(压缩前 270+GB),里面包含了 4000 台服务器、相应的在线应用容器和离线计算任务长达 8 天的运行情况,具体信息你可以在 GitHub 中找到。
通过这份数据,你可以:
- 了解当代先进数据中心的服务器以及任务运行特点;
- 试验你的调度、运筹等各种任务管理和集群优化方面的各种算法并撰写论文;
- 利用这份数据学习如何进行数据分析,揭示更多我们自己都未曾发现的规律。
只看上面这几点,没有接触过类似数据的朋友,可能对于这份数据的用处还是没有概念,下面我举几个简单的例子:
- 电商业务在白天和晚上面临的压力不同,我们如何在业务存在波峰波谷的情况下提高整体资源利用率?
- 你知道我们最长的 DAG 有多少依赖吗?
- 一个典型的容器存在时间是多久?
- 一个计算型任务的典型存在时间是多少?一个 Task 的多个 Instance 理论上彼此很相似,但是它们运行的时间都一样吗?
实际上,学者们甚至可以用这些数据作出更加精彩地分析。
2017年,我们曾开放的第一波数据(Alibaba Cluster Data V2017),已经产生了多篇优秀的学术成果。以下是学者们在论文中引用数据(Alibaba Cluster Data V2017)的例子,其中不乏被 OSDI 这样顶级学术会议收录的优秀文章。我们期待,未来你也能与我们共同分享你用这份数据产生的成果!
"LegoOS: A Disseminated, Distributed OS for Hardware Resource Disaggregation, Yizhou Shan, Yutong Huang, Yilun Chen, and Yiying Zhang, Purdue University. OSDI'18" (Best paper award!)
"Imbalance in the Cloud: an Analysis on Alibaba Cluster Trace, Chengzhi Lu et al. BIGDATA 2017"
"CharacterizingCo-located Datacenter Workloads: An Alibaba Case Study, Yue Cheng, Zheng Chai,Ali Anwar. APSys2018"
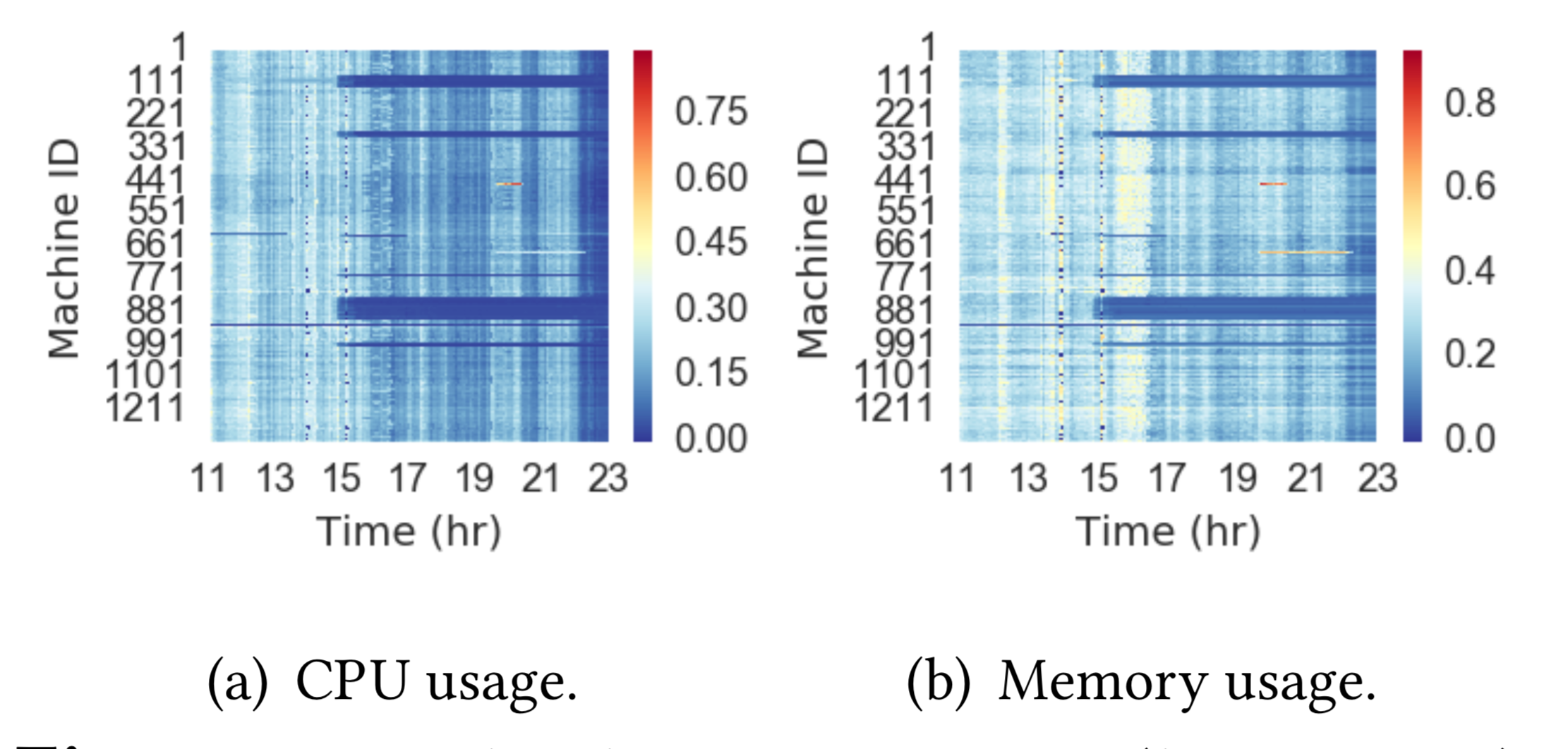
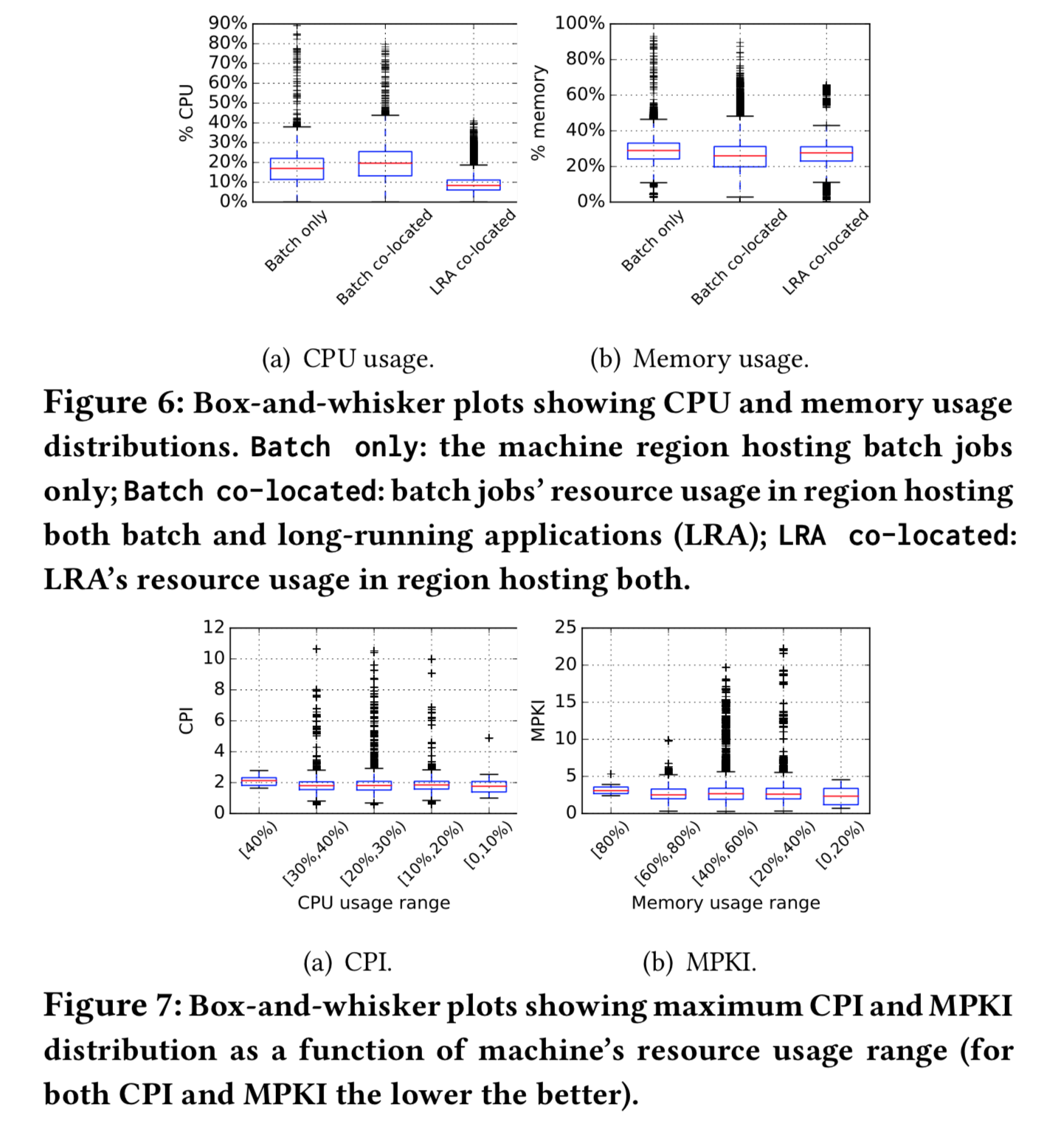
"The Elasticity and Plasticity in Semi-Containerized Co-locating Cloud Workload: aView from Alibaba Trace, Qixiao Liu and Zhibin Yu. SoCC2018"


3 Cluster Data V2018的不同
新版本 V2018 与 V2017 存在两个最大的区别:
DAG 信息加入
我们加入了离线任务的 DAG 任务信息,据了解,这是目前来自实际生产环境最大的 DAG 数据。
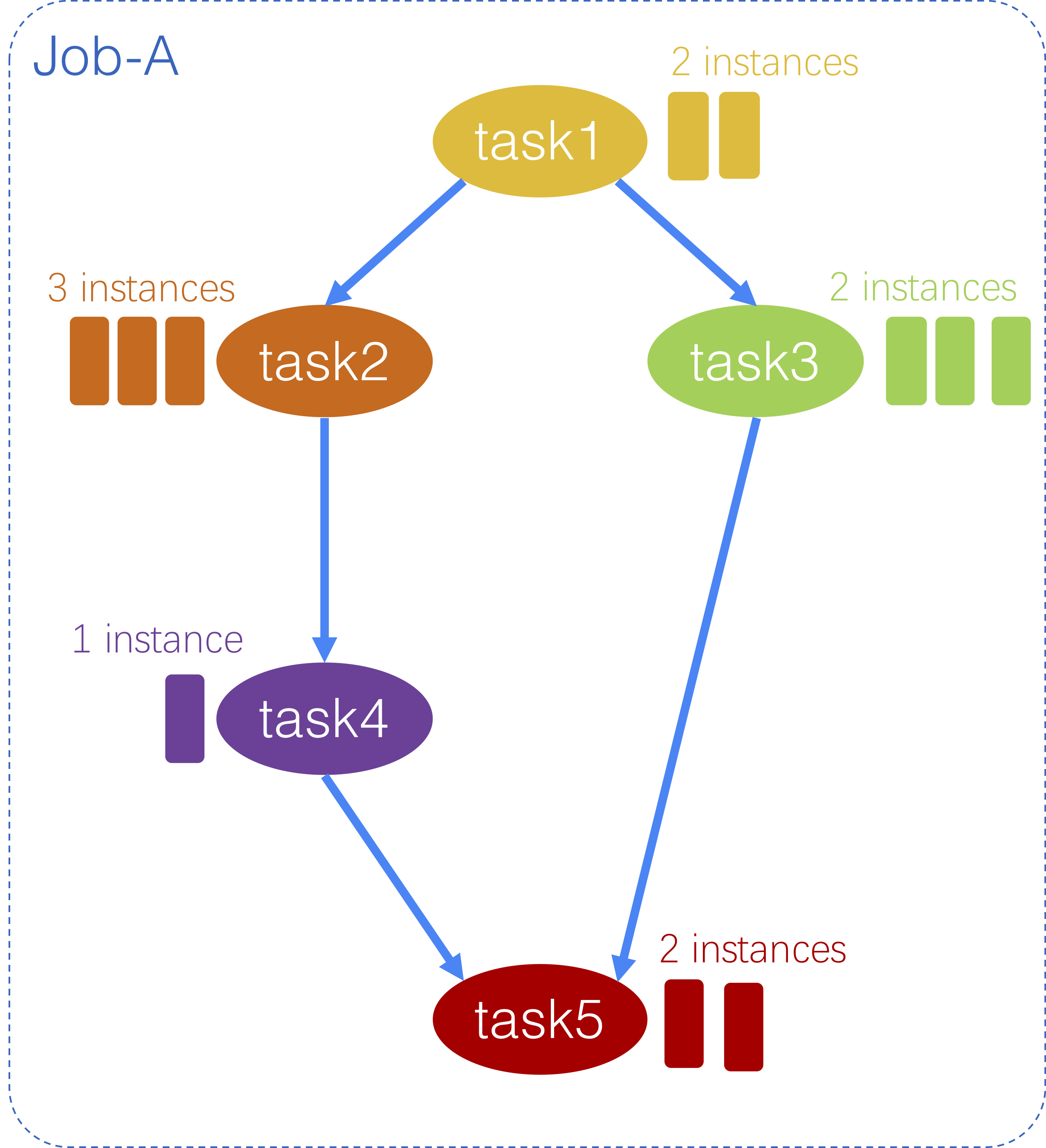
什么是 DAG?
离线计算任务,例如 Map Reduce、Hadoop、Spark、Flink 中常用的任务,都是以有向无环图(Directed Acyclic Graph,DAG)的形式进行编排的,其中涉及到任务之间的并行、依赖等方面。下面是一个 DAG 的例子。
规模更大
上一版数据包含了约 1300 台机器在约 24 小时的内容数据,而新版 Cluster Data V2018 中包括了 4000 台机器 8 天的数据。
- 完成问卷即可获取数据格式描述和数据的下载链接:http://alibabadeveloper.mikecrm.com/BdJtacN
- 欢迎加入钉钉群:23112775与团队取得联系
- 对看到更多的数据有兴趣?我们长期招收研究型实习生,与我们一起攻克难题和撰写论文,简历投递:haiyang.dhy@alibaba-inc.com
Alibaba Cluster Data 开源:270GB 数据揭秘你不知道的阿里巴巴数据中心的更多相关文章
- Alibaba Cluster Data 开放下载:270GB 数据揭秘你不知道的阿里巴巴数据中心
打开一篇篇 IT 技术文章,你总能够看到“大规模”.“海量请求”这些字眼.如今,这些功能强大的互联网应用,都运行在大规模数据中心上,然而,对于大规模数据中心,你又了解多少呢?实际上,除了阅读一些科技文 ...
- Salesforce开源TransmogrifAI:用于结构化数据的端到端AutoML库
AutoML 即通过自动化的机器学习实现人工智能模型的快速构建,它可以简化机器学习流程,方便更多人利用人工智能技术.近日,软件行业巨头 Salesforce 开源了其 AutoML 库 Transmo ...
- facebook开源了他们的分布式大数据DB
https://github.com/facebook/presto facebook 3天前开源了他们的 分布式大数据DB Distributed SQL query engine for big ...
- Farseer.net轻量级开源框架 入门篇:添加数据详解
导航 目 录:Farseer.net轻量级开源框架 目录 上一篇:Farseer.net轻量级开源框架 入门篇: 分类逻辑层 下一篇:Farseer.net轻量级开源框架 入门篇: 修改数据详解 ...
- Farseer.net轻量级开源框架 入门篇:修改数据详解
导航 目 录:Farseer.net轻量级开源框架 目录 上一篇:Farseer.net轻量级开源框架 入门篇: 添加数据详解 下一篇:Farseer.net轻量级开源框架 入门篇: 删除数据详解 ...
- Farseer.net轻量级开源框架 入门篇:删除数据详解
导航 目 录:Farseer.net轻量级开源框架 目录 上一篇:Farseer.net轻量级开源框架 入门篇: 修改数据详解 下一篇:Farseer.net轻量级开源框架 入门篇: 查询数据详解 ...
- Farseer.net轻量级开源框架 入门篇:查询数据详解
导航 目 录:Farseer.net轻量级开源框架 目录 上一篇:Farseer.net轻量级开源框架 入门篇: 删除数据详解 下一篇:Farseer.net轻量级开源框架 中级篇: Where条 ...
- Tapdata 与阿里云 PolarDB 开源数据库社区联合共建开放数据技术生态
近日,阿里云 PolarDB 开源数据库社区宣布将与 Tapdata 联合共建开放数据技术生态.在此之际,一直专注实时数据服务平台的 Tapdata ,也宣布开源其数据源开发框架--PDK(Plu ...
- 数据访问模式:数据并发控制(Data Concurrency Control)
1.数据并发控制(Data Concurrency Control)简介 数据并发控制(Data Concurrency Control)是用来处理在同一时刻对被持久化的业务对象进行多次修改的系统.当 ...
随机推荐
- pair queue____多源图广搜
.简介 class pair ,中文译为对组,可以将两个值视为一个单元.对于map和multimap,就是用pairs来管理value/key的成对元素.任何函数需要回传两个值,也需要pair. 该函 ...
- Eclipse中发布Maven管理的Web项目时找不到类的问题根源和解决办法(转)
转自:http://blog.csdn.net/lvguanming/article/details/37812579?locationNum=12 写在前面的话 现在是越来越太原讨厌Eclipse这 ...
- json数据返回数字,页面显示文字处理
var obj = { 1:'你好1', 2:'你好2', 3:'你好3' } var e = obj[1]; e; //'你好1'
- 75. InputStreamReader和OutputStreamWriter(转换流--字节流转换成字符流)
转换流: InputStreamReader 输入字节流转换成输入字符流OutputStreamWriter 输出字节流转换成输出字符流 总结:就是字节流转换成字符流,但是不能字节流转换成字节流 ...
- Java高并发网络编程(一)
一.OSI网络七层模型 因特网是一个极为复杂的网络,分层有助于我们对网络的理解 .分层也是一种标准,为了使不同厂商的计算机能够互相通信,以便在更大范围内建立计算机网络,有必要建立一个国际范围的网络体系 ...
- Mysql安装多版本数据库
1.下载对应版本压缩包 2.解压缩文件 3.到解压缩文件,添加my.ini文件,修改相关的配置,如端口,文件路径等 # For advice on how to change settings ple ...
- 【版本】Spring Cloud 版本
Spring Cloud 版本 Spring Cloud没有数字版本号,而是对应一个开发代号 Cloud代号 Boot版本(train) Boot版本(tested) lifecycle Angle ...
- Java学习之集合(LinkedList链表集合)
一.什么是链表集合,通过图形来看,比如33只知道它下一个是55 如果:现在要删除33的话,就是把55赋值给45,这样看它操作集合速度会非常快. 二.LinkedList特有方法 1.添加 addFir ...
- Dubbo入门到精通学习笔记(十五):Redis集群的安装(Redis3+CentOS)、Redis集群的高可用测试(含Jedis客户端的使用)、Redis集群的扩展测试
文章目录 Redis集群的安装(Redis3+CentOS) 参考文档 Redis 集群介绍.特性.规范等(可看提供的参考文档+视频解说) Redis 集群的安装(Redis3.0.3 + CentO ...
- C++——编译器运行过程
C++ 编译过程简介 C/C++程序编译流程: 预处理->编译->汇编->链接 具体的就是: 源代码(source coprede)→预处理器(processor)→编译器(co ...