python15正则表达式
------------恢复内容开始------------

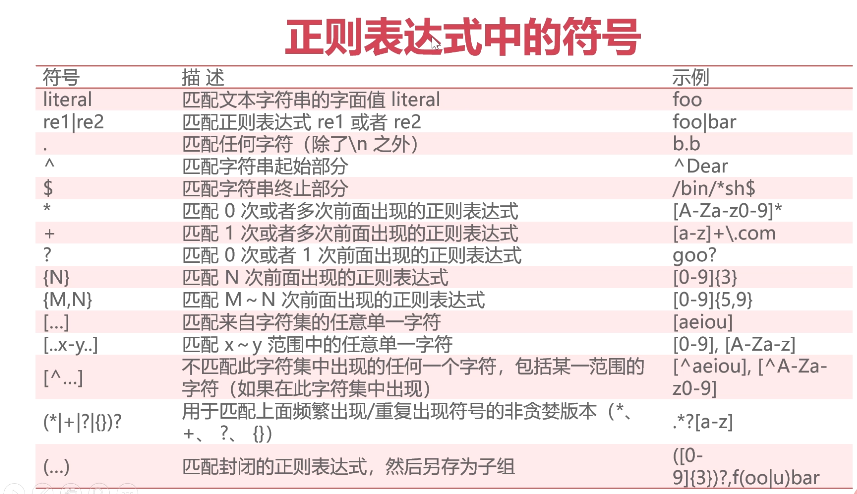


















python实现实现实现实现


import re #将表达式编译,返回一个对象,
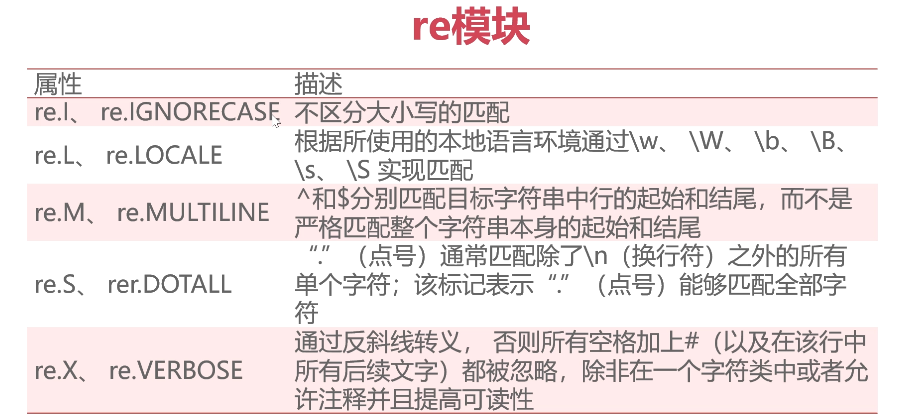
pattern = re.compile(r"hello",re.I)#re.I忽略大小写 print(dir(pattern))
#使用对象的方法,通过match匹配
rest = pattern.match("hellossss")
print(rest)
rest1 = pattern.match("Hellossss")
print(rest1)
print(dir(rest1)) 结果:
['__class__', '__copy__', '__deepcopy__', '__delattr__', '__dir__', '__doc__', '__eq__',
'__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__',
'__init_subclass__', '__le__', '__lt__', '__ne__', '__new__', '__reduce__',
'__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__',
'findall', 'finditer', 'flags', 'fullmatch', 'groupindex', 'groups', 'match', 'pattern',
'scanner', 'search', 'split', 'sub', 'subn']
<re.Match object; span=(0, 5), match='hello'>
<re.Match object; span=(0, 5), match='Hello'>
['__class__', '__copy__', '__deepcopy__', '__delattr__', '__dir__', '__doc__',
'__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__gt__', '__hash__',
'__init__', '__init_subclass__', '__le__', '__lt__', '__ne__', '__new__', '__reduce__',
'__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__',
'end', 'endpos', 'expand', 'group', 'groupdict', 'groups', 'lastgroup', 'lastindex',
'pos', 're', 'regs', 'span', 'start', 'string']

浏览全部字符串,匹配所有合规则的字符串,匹配到的字符串放到一个列表中,未匹配成功返回空列表 一旦匹配成,再次匹配,是从前一次匹配成功的,后面一位开始的,也可以理解为匹配成功的字符串,不在参与下次匹配 无分组:匹配所有合规则的字符串,匹配到的字符串放到一个列表中 有分组:只将匹配到的字符串里,组的部分放到列表里返回,相当于groups()方法 多个分组:只将匹配到的字符串里,组的部分放到一个元组中,最后将所有元组放到一个列表里返 相当于在group()结果里再将组的部分,分别,拿出来放入一个元组,最后将所有元组放入一个列表返回 分组中有分组:只将匹配到的字符串里,组的部分放到一个元组中,先将包含有组的组,看作一个整体也就是一个组,把这个整体组放入一个元组里,然后在把组里的组放入一个元组,最后将所有组放入一个列表返回
import re #使用编译
coent = "Oone1twoT2three3"
p = re.compile(r"[a-z]+",re.I)#r表示其后的字符串按原样表示,不使用转义字符
rest = p.findall(coent) #一列表的额形式返回
print(rest) #不编译直接使用方法
print(re.findall(r"[a-z]+",coent,re.I))
结果:
['Oone', 'twoT', 'three']
['Oone', 'twoT', 'three']

import re
content = "quan zhiqiang"
p = re.compile(r"zhi")
rest = p.search(content)
print(rest) print("QQQQQQQQQQQQQQQQ")
rest1 = p.match(content)
print(rest1)
#因为match从第一个字符开始寻找,第一个字符不匹配直接不寻找了,
#search会继续下一个查找 print("不编译,不编译")
no_rest = re.search("zhi",content)
print(no_rest)
结果:
<re.Match object; span=(5, 8), match='zhi'>
QQQQQQQQQQQQQQQQ
None
不编译,不编译
<re.Match object; span=(5, 8), match='zhi'>

import re def test_g():
content = "quanzhiqiang"
p = re.compile(r"zhi")
rest = p.search(content)
print(rest)#注意,当匹配不到的时候,需要对if rest 进行判断,不然直接
if rest:
#使用group打印会出错
print(rest.group())
#如果前面使用分株,可以group(1)
print(rest.groups())#因为没有进行分组,所以为空的元组 def test_id():
p = re.compile(r"(\d{6})(\d{4})((\d{2})(\d{2}))\d{2}\d{1}([0-9]|X)")
id1 = "440882199904142235"
id2 = "44088219990214228X"
rest1 = p.search(id2)
print(rest1.group(1))
print(rest1.groups())#放回说有的组
print("#######################")
print(rest1.groupdict()) if __name__ == "__main__":
test_g()
test_id() 结果:
<re.Match object; span=(4, 7), match='zhi'>
zhi
()
440882
('440882', '1999', '0214', '02', '14', 'X')
#######################
{}
import re def test_g():
content = "quanzhiqiang"
p = re.compile(r"zhi")
rest = p.search(content)
print(rest)#注意,当匹配不到的时候,需要对if rest 进行判断,不然直接
if rest:
#使用group打印会出错
print(rest.group())
#如果前面使用分株,可以group(1)
print(rest.groups())#因为没有进行分组,所以为空的元组 def test_id():
#p = re.compile(r"(\d{6})(\d{4})((\d{2})(\d{2}))\d{2}\d{1}([0-9]|X)")
p = re.compile(r"(\d{6})(?P<year>\d{4})((?P<month>\d{2})(?P<day>\d{2}))\d{2}\d{1}([0-9]|X)")
id1 = "440882199904142235"
id2 = "44088219990214228X"
rest1 = p.search(id2)
print(rest1.group(1))
print(rest1.groups())#放回说有的组
print("#######################")
print(rest1.groupdict()) if __name__ == "__main__":
test_g()
test_id() 结果;
<re.Match object; span=(4, 7), match='zhi'>
zhi
()
440882
('440882', '1999', '0214', '02', '14', 'X')
#######################
{'year': '1999', 'month': '02', 'day': '14'}

import re s = "one1two2three333four"
p = re.compile(r"\d+")
rest = p.split(s)
print(rest) 结果:
['one', 'two', 'three', 'four']

import re s = "one1two2three333four"
p = re.compile(r"\d+")
rest = p.split(s,2)#只分割前两个
print(rest) 结果:
['one', 'two', 'three333four']
import re s = "one1two2three333four"
#s = "one@two@three@four" p = re.compile(r"\d+")
rest = p.sub("@",s)
print(rest) #原始的替换方法:
print("@@@@@@@@@@@@@@@@@@@@@@@@@@@")
rest1 = s.replace("1","@").replace("2","@").replace("333","@")
print(rest1) #更换位置
s2 = "hello world"
p2 = re.compile(r"(\w+) (\w+)")
rest3 = p2.sub(r"\2 \1",s2)
print(rest3) #使用函数进行替换更换并大写:
def f(m):
return m.group(2).upper() + " " + m.group(1)
print("HHHHHHHHHHHHHHHHHHHHHHH")
rest4 = p2.sub(f,s2)
print(rest4) #使用匿名函数替换
print("QQQQQQQQQQQQQQQQQQQQQQ")
rest6 = p2.sub(lambda m :m.group(2).upper() + " " + m.group(1),s2)
print(rest6) 结果:
one@two@three@four
@@@@@@@@@@@@@@@@@@@@@@@@@@@
one@two@three@four
world hello
HHHHHHHHHHHHHHHHHHHHHHH
WORLD hello
QQQQQQQQQQQQQQQQQQQQQQ
WORLD hello
------------恢复内容结束------------
python15正则表达式的更多相关文章
- JS正则表达式常用总结
正则表达式的创建 JS正则表达式的创建有两种方式: new RegExp() 和 直接字面量. //使用RegExp对象创建 var regObj = new RegExp("(^\\s+) ...
- Python高手之路【五】python基础之正则表达式
下图列出了Python支持的正则表达式元字符和语法: 字符点:匹配任意一个字符 import re st = 'python' result = re.findall('p.t',st) print( ...
- C# 正则表达式大全
文章导读 正则表达式的本质是使用一系列特殊字符模式,来表示某一类字符串.正则表达式无疑是处理文本最有力的工具,而.NET提供的Regex类实现了验证正则表达式的方法.Regex 类表示不可变(只读)的 ...
- C#基础篇 - 正则表达式入门
1.基本概念 正则表达式(Regular Expression)就是用事先定义好的一些特定字符(元字符)或普通字符.及这些字符的组合,组成一个“规则字符串”,这个“规则字符串”用来判断我们给定的字符串 ...
- JavaScript正则表达式,你真的知道?
一.前言 粗浅的编写正则表达式,是造成性能瓶颈的主要原因.如下: var reg1 = /(A+A+)+B/; var reg2 = /AA+B/; 上述两个正则表达式,匹配效果是一样的,但是,效率就 ...
- Python 正则表达式入门(中级篇)
Python 正则表达式入门(中级篇) 初级篇链接:http://www.cnblogs.com/chuxiuhong/p/5885073.html 上一篇我们说在这一篇里,我们会介绍子表达式,向前向 ...
- 【JS基础】正则表达式
正则表达式的() [] {}有不同的意思. () 是为了提取匹配的字符串.表达式中有几个()就有几个相应的匹配字符串. (\s*)表示连续空格的字符串. []是定义匹配的字符范围.比如 [a-zA-Z ...
- JavaScript 正则表达式语法
定义 JavaScript定义正则表达式有两种方法. 1.RegExp构造函数 var pattern = new RegExp("[bc]at","i"); ...
- [jquery]jquery正则表达式验证(手机号、身份证号、中文名称)
数字判断方法:isNaN()函数 test()方法 判断字符串中是否匹配到正则表达式内容,返回的是boolean值 ( true / false ) // 验证中文名称 function isChin ...
随机推荐
- 使用flink实现一个简单的wordcount
使用flink实现一个简单的wordcount 一.背景 二.需求 三.前置条件 1.jdk版本要求 2.maven版本要求 四.实现步骤 1.创建 flink 项目 2.编写程序步骤 1.创建Str ...
- 线路由器频段带宽是是20M好还是40M好
无线路由器频段带宽还是40M好. 40M的信号强,速度快. 1.20MHz在11n的情况下能达到144Mbps带宽.穿透性不错.传输距离较远 40MHz在11n的情况下能达到300Mbps带宽.穿 ...
- C语言中都有哪些常见的数据结构你都知道几个??
上次在面试时被面试官问到学了哪些数据结构,那时简单答了栈.队列/(ㄒoㄒ)/~~其它就都想不起来了,今天有空整理了一下几种常见的数据结构,原来我们学过的数据结构有这么多~ 首先,先来回顾下C语言中常见 ...
- TT模板的作用及使用
一.假如你在ef中添加一个实体,没有模板,你需要在DAL层中新建一个"莫某Dal"和"I某某Dal"以及在公共的DbSession中加你的这个dal,然后需要在 ...
- Docker 安装 MySQL8
1. 环境准备 创建挂载数据目录和配置文件 mkdir -p /mnt/mysql/data /etc/mysql/conf touch /etc/mysql/conf/my.cnf 2. 拉取镜像 ...
- 数值的整数次方 牛客网 剑指Offer
数值的整数次方 牛客网 剑指Offer 题目描述 给定一个double类型的浮点数base和int类型的整数exponent.求base的exponent次方 class Solution: #run ...
- zabbix 监控redis 挂掉自动重启 并发送企业微信
1.创建redis监控项[配置]-[主机]-[监控项]-创建监控项,监控6379端口(注意关闭防火墙或者开启防火墙端口6379) redis配置文件设置允许任何地址监听: 添加监控项 2.创建redi ...
- C# StringBuilder和string
StringBuilder和string 1.string是引用类型还是值类型 MSDN官方说string是引用类型: 引用类型:引用分配栈内存,引用类型本身的数据存储在堆中: 值类型:在函数中创建, ...
- 羽夏看Win系统内核——SourceInsight 配置 WRK
写在前面 此系列是本人一个字一个字码出来的,包括示例和实验截图.由于系统内核的复杂性,故可能有错误或者不全面的地方,如有错误,欢迎批评指正,本教程将会长期更新. 如有好的建议,欢迎反馈.码字不易, ...
- 什么是 Webhook?
1. 什么是 Webhook? Webhook 是一个 API 概念,是微服务 API 的使用范式之一,也被成为反向 API,即前端不主动发送请求,完全由后端推送:举个常用例子,比如你的好友发了一条朋 ...