pandas(3):索引Index/MultiIndex
一、索引概念
“索引”类似一本书的目录(页码),通过目录(页码),让我们能快速找到想看的位置。对于一个DataFrame数据框,其中:
- 行索引(Label index),是一条完整数据的索引,通过这个索引,能快速取出对应的某条数据记录。
- 列索引(Columns Names),指向的是每一个Series。
- 行是一条完整信息记录,索引在业务上一般不允许重复,好的索引能方便处理数据,重复的索引导入数据库可能出现限制,可以设置默认配置。
- 无论是行索引还是列索引,在 Pandas 里其实都是一个** Index 对象,都有类似的属性和方法**。
- pandas的索引有不同的类型,目的都是为更方便处理数据。
二、创建索引
源Excel文件index.xlsx:
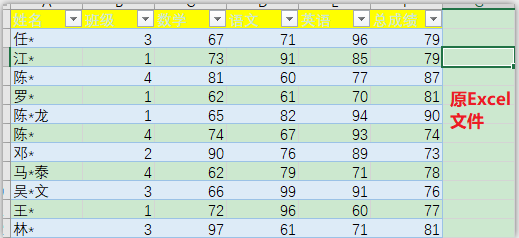
①导入数据时指定索引
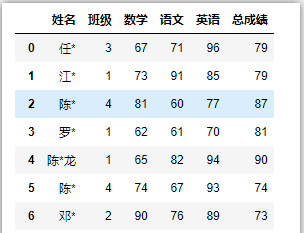
- 未指定时,python会自动生成从0开始的行索引,列名默认为第1行
pandas不知道你实际业务情况,所以只能自动生成0-N的自然索引。
df = pd.read_excel('C:/Users/asus/Desktop/index.xlsx')
df
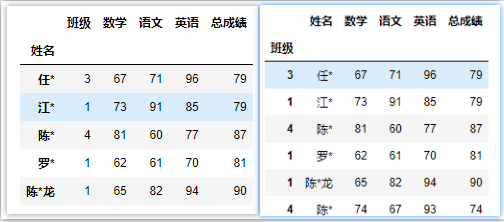
- 自定义指定
# 指定’姓名‘或’班级‘这一列为行索引
df = pd.read_excel('C:/Users/asus/Desktop/index.xlsx',index_col='姓名')
# df = pd.read_excel('C:/Users/asus/Desktop/index.xlsx',index_col='班级')
df
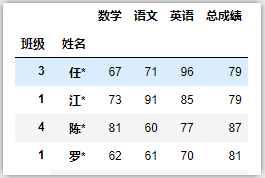
# 指定’班级‘、’姓名‘这两列为层级索引MultiIndex
df = pd.read_excel('C:/Users/asus/Desktop/index.xlsx',index_col=[1,0])
df
也可以根据header参数指定哪行作为列名,或根据names参数自定义列名,具体见:https://www.cnblogs.com/xiaoshun-mjj/p/14538695.html
②导入数据后指定索引df.set_index()
DataFrame.set_index(keys, drop=True, append=False,
inplace=False, verify_integrity=False)
参数说明:
- keys:列标签或列标签/列表/series,需要设置为索引的列;
- drop:是否保留设置索引的原列。默认为True,不保留;
- append:是否保留原索引。默认为False,不保留;
- inplace:输入布尔值,表示当前操作是否对原数据生效,默认为False。
- verify_integrity:检查新索引的副本。否则,请将检查推迟到必要时进行。将其设置为false将提高该方法的性能,默认为false。
# 导入数据时,未指定索引
df = pd.read_excel('C:/Users/asus/Desktop/index.xlsx')
df.set_index('姓名') # 设置姓名为索引
df.set_index(['班级','姓名']) # 设置班级和姓名为索引
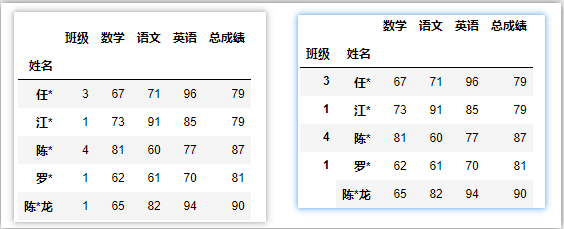
df.set_index('姓名',drop=False) # 保留原列
df.set_index('姓名',append=True) # 保留原索引
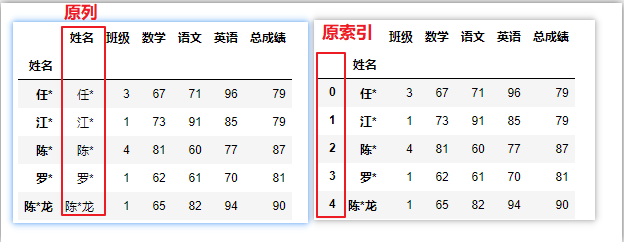
三、常用的索引属性
以df.index为例,也适用于 df.columns, 因为两者都是 index 对象
df = pd.read_excel('C:/Users/asus/Desktop/index.xlsx') # 导入数据时,未指定索引
df.set_index('姓名',drop=False,inplace=True) # 保留原列,对原数据生效
# 查看索引信息(值和类型,还有可能有名称)
df.columns
df.index

df.index.name # 行索引名称
df.index.dtype # 索引数据类型
df.index.shape # 形状
df.index.size # 元素数量,行记录条数
# df.columns.size
df.index.values # 索引的值,array 数组
# df.index.value_counts() # 去重统计
# df.index.values.tolist() # array 数组转换成列表list
df.index.is_unique # 判断是否有重复,业务上原则一般不会重复,有重复返回False
四、常用索引方法
一样适用于 df.columns。
df.columns.isin(['姓名','语文']) # 是否存在,快速查看是否有该列名或行

df.index.nunique() # 不重复值的数量
df.index.sort_values(ascending=False) # 排序,倒序
df.index.to_frame(index=False) # 转成 DataFrame
df.index.unique() # 去重
df.index.value_counts() # 去重分组统计
df.index.where(df.index=='林*') # 筛选,查看是否由该行记录
df.index.max() # 最大值
df.index.map(lambda x:x+'_') # 批量处理索引

五、索引重置reset_index()
列可以变成索引,索引也能回复成列。
DataFrame.reset_index(level=None, drop=False,
inplace=False, col_level=0, col_fill='')
参数说明:
- level:数值类型可以为:int、str、tuple或list,默认无,仅从索引中删除给定级别。默认情况下移除所有级别。控制了具体要还原的那个等级的索引 。
- drop:当指定drop=False时,则索引列会被还原为普通列;否则,经设置后的新索引值被会丢弃。默认为False。
- inplace:输入布尔值,表示当前操作是否对原数据生效,默认为False。
- col_level:数值类型为int或str,默认值为0,如果列有多个级别,则确定将标签插入到哪个级别。默认情况下,它将插入到第一级。
- col_fill:对象,默认‘’,如果列有多个级别,则确定其他级别的命名方式。如果没有,则重复索引名。
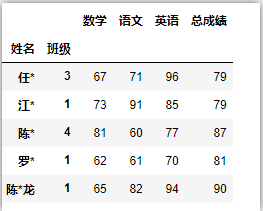
df = pd.read_excel('C:/Users/asus/Desktop/index.xlsx') # 导入数据时,未指定索引
df = df.set_index(['姓名','班级']) # 设置MultiIndex
df
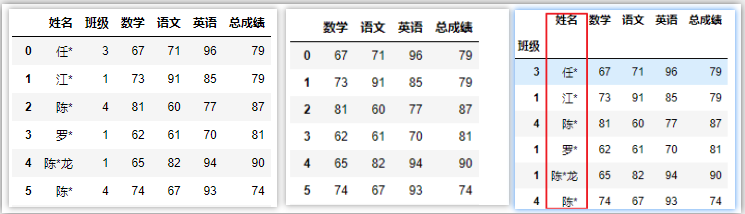
df.reset_index() # 移除所有层级索引,并把索引还原成列
df.reset_index(drop=True) # 移除所有层级索引,舍弃原索引
df.reset_index(['姓名']) # 只把姓名这一层索引还原层列
六、修改索引值(修改列名)
# 一对一对应修改
df.rename(columns={'数学': 'maths'})
# 也可以通过一些函数进行批量修改
df.rename(lambda x:'t_' + x, axis=1) # 通过lambda表达式批量给列名加前缀
pandas(3):索引Index/MultiIndex的更多相关文章
- pandas层级索引1
层级索引(hierarchical indexing) 下面创建一个Series, 在输入索引Index时,输入了由两个子list组成的list,第一个子list是外层索引,第二个list是内层索引. ...
- pandas层级索引
层级索引(hierarchical indexing) 下面创建一个Series, 在输入索引Index时,输入了由两个子list组成的list,第一个子list是外层索引,第二个list是内层索引. ...
- (三)pandas 层次化索引
pandas层次化索引 1. 创建多层行索引 1) 隐式构造 最常见的方法是给DataFrame构造函数的index参数传递两个或更多的数组 Series也可以创建多层索引 import numpy ...
- Python数据科学手册-Pandas:层级索引
一维数据 和 二维数据 分别使用Series 和 DataFrame 对象存储. 多维数据:数据索引 超过一俩个 键. Pandas提供了Panel 和 Panel4D对象 解决三维数据和四维数据. ...
- SQL Server 索引(index) 和 视图(view) 的简单介绍和操作
--索引(index)和视图(view)-- --索引(index)----概述: 数据库中的索引类似于书籍的目录,他以指针形式包含了表中一列或几列组合的新顺序,实现表中数据库的逻辑排序.索引创建在数 ...
- Handlebars.js循环中索引(@index)使用技巧(访问父级索引)
使用Handlebars.js过程中,难免会使用循环,比如构造数据表格.而使用循环,又经常会用到索引,也就是获取当前循环到第几次了,一般会以这个为序号显示在页面上. Handlebars.js中获取循 ...
- 关于分区技术的索引 index
关于分区技术---索引 Index 一. 分区索引分类: 本地前缀分区索引(local prefixedpartitioned index) 全局分区索引(global partitionedin ...
- Mysql数据库学习笔记之数据库索引(index)
什么是索引: SQL索引有两种,聚集索引和非聚集索引,索引主要目的是提高了SQL Server系统的性能,加快数据的查询速度与减少系统的响应时间. 聚集索引:该索引中键值的逻辑顺序决定了表中相应行的物 ...
- 使用jQuery+huandlebars循环中索引(@index)使用技巧(访问父级索引)
兼容ie8(很实用,复制过来,仅供技术参考,更详细内容请看源地址:http://www.cnblogs.com/iyangyuan/archive/2013/12/12/3471227.html) & ...
随机推荐
- 推荐一款好用的免费远程控制软件——ToDesk
创作立场声明:我在本文中评测的软件为自用,感觉不错并且全免费,第一时间发出来和大家分享,欢迎理性观点交流碰撞. 疫情刚开始的时候,待在家里不能上班,但是还是有很多工作需要在线完成,常常需要跑回办公室拿 ...
- 读懂框架设计的灵魂—Java反射机制
尽人事,听天命.博主东南大学硕士在读,热爱健身和篮球,乐于分享技术相关的所见所得,关注公众号 @ 飞天小牛肉,第一时间获取文章更新,成长的路上我们一起进步 本文已收录于 CS-Wiki(Gitee 官 ...
- 使用CSS计数器美化数字有序列表
在web设计中,使用一种井井有条的方法来展示数据是十分重要的,这样用户就可以很清晰的理解网站所展示的数据结构和内容,使用有序列表就是实现数据有组织的展示的一种简单方法. 如果你需要更加深入地控制有序列 ...
- 185. 部门工资前三高的所有员工 + 多表联合 + join + dense_rank()
185. 部门工资前三高的所有员工 LeetCode_MySql_185 题目描述 方法一:使用join on # Write your MySQL query statement below sel ...
- 剑指 Offer 44. 数字序列中某一位的数字 + 找规律 + 数位
剑指 Offer 44. 数字序列中某一位的数字 Offer_44 题目描述 题解分析 java代码 package com.walegarrett.offer; /** * @Author Wale ...
- Java 读取Word文本框中的文本/图片/表格
Word可插入文本框,文本框中可嵌入文本.图片.表格等内容.对文档中的已有文本框,也可以读取其中的内容.本文以Java程序代码来展示如何读取文本框,包括读取文本框中的文本.图片以及表格等. [程序环境 ...
- 前端笔记:React的form表单全部置空或者某个操作框置空的做法
1.全部置空的做法,一般在弹出框关闭后,需要重置该form所有表单: this.props.form.resetFields(); 2.针对某个操作框置空的做法 例如,form表单里有一个部门和一个张 ...
- 记一次 mysql主从复制安装配置 过程
mysql主从复制安装配置 1.centos安装及准备 去centos官网下载相应source版本的镜像文件并在vmware中安装,安装中会遇到填写installation source,输入以下即可 ...
- linux云服务搭建Minecraft服务器
1 准备工作 以下内容全部要在root用户内完成 1.1 安装文件传输工具 为了方便传文件到服务器上,这里先装一个远程传输工具. yum -y install lrzsz 1.2 安装java Min ...
- Django1和2的区别
一.路由的区别 1.Django1中的url from django.conf.urls import url # 使用url关键字 urlpatterns = [ url('article-(\d+ ...