[DB] HDFS
体系架构
- NameNode
- HDFS主节点、管理员
- 接收客户端(命令行、Java程序)的请求:创建目录、上传、下载、删除数据
- 管理和维护HDFS的日志和元信息
- 日志文件(edits文件)
- 二进制文件,记录客户端所有操作,同时体现HDFS的最新状态
- $HADOOP_HOME/tmp/dfs/name/current
- 日志查看器(edits viewer):把edits转成文本(XML)格式
- hdfs oev -i edits_inprogress_0000000000000000107 -o ~/a.xml
- 元信息(fsimage文件)
- 记录数据块的位置信息、数据块的冗余信息,不体现HDFS的最新状态
- $HADOOP_HOME/tmp/dfs/name/current
- image viewer,把fsimage文件转为文本或者xml
- 日志文件(edits文件)
- DataNode
- 数据节点
- 按数据块保存数据库(1.x:64M,2.x:128M)
- /root/training/hadoop-2.7.3/tmp/dfs/data/current/BP-419062579-192.168.157.111-1535553141546/current/finalized/subdir0/subdir0
- 数据块冗余度设置原则:一般跟数据节点的个数一样,但是最大不要超过3
- Hadoop 3.x以后,HDFS纠删码技术,大大的节约存储的空间(节约一半 )
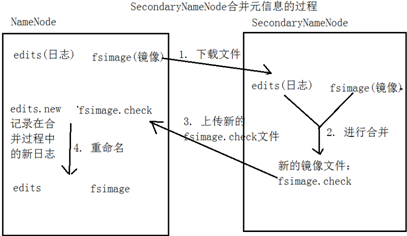
- SecondaryNameNode
- 第二名称节点
- 进行日志信息的合并
- 由于edits文件记录了最新的状态信息,并且随着操作越来越多,edits就会越大
- 把edits中的最新信息写到fsimage中
- edits文件就可以清空
- 通常和NameNode部署在一台机器上,提高下载速度
- 什么时候合并?HDFS发出检查点时(checkpoint)
- HDFS每隔60分钟产生一个检查点(fs.check.period)
- edits文件达到64M(fs.check.size)
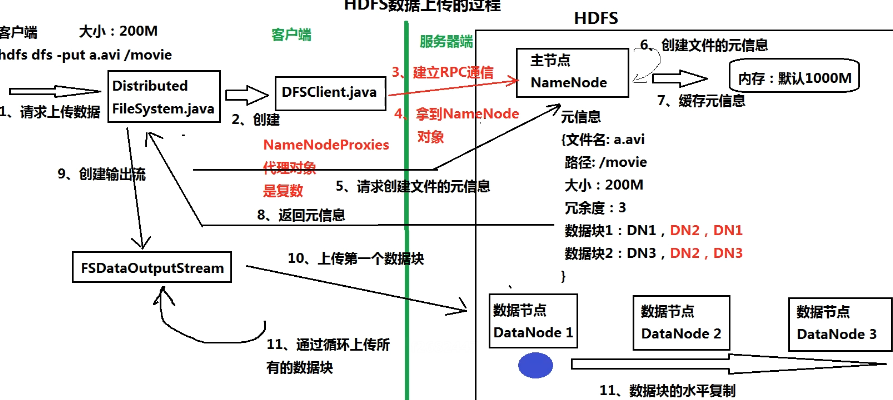
数据传输
- 数据上传
- 请求上传数据 Distributed FileSystem.java
- 创建 DFSClient.java
- 建立RPC通信
- 拿到NameNode代理对象NameNodeProxies(HA)
- 请求创建文件元信息
- 创建文件元信息
- 将元信息返回给 Distributed FileSystem
- 创建输出流 FSDataOutputStream
- 上传数据到DataNode
- 根据元信息,水平复制
- 数据下载
- 请求
- 创建
- 建立RPC通信
- 请求得到元信息
- 查找元信息(先查缓存,再查fsimage)
- 返回元信息
- 创建输入流
- 下载数据块
- 把下载的数据块合成一个文件

高级特性
- 安全模式
- 只读,正常运行时off
- HDFS的自我保护机制,检查数据块副本率
- 如果冗余度小于设定的副本率(DataNode坏掉),就水平复制
- 在hdfs-default.xml中设定副本率
- 快照
- 全部文件系统或某目录在某时刻的镜像,默认关闭
- 启用目录的快照功能
- 创建快照 -createSnapshot 目录 快照名称
- 用于以下场景
- 防止用户误操作/备份/测试/灾难恢复
- 一般不建议使用,因为本来就有冗余,再生成新的冗余,太浪费空间
- 配额
- HDFS为每个目录分配的大小空间
- 名称配额
- 设置该目录中最多存放的文件(目录)个数
- 空间配额
- 设置该目录中最大能够存放的文件大小
- 回收站
- 默认禁用
- 放入/trash
- 回收站中文件可快速恢复
- 可设置一个时间,超过后文件自动删除
- 用户权限管理
- 功能较弱
- 建议使用 Hadoop Kerberos
启动过程
- 网页->Startup Progress
- Loading fsimage
- Loading edits
- Saving checkpoint
- Safe mode
底层原理
- RPC(remote procedure call)
- 远程过程调用(协议)
- 在客户端调用服务器端的程序
- 一个框架,调用者和被调用者运行在其中完成通信
- 调用远程代码,需要实现调用者和被调用者间的连接与通信
- 基于Client/Server进程间相互通信的一种同步通信形式
- Client是请求服务的调用者,Server是执行Client的请求而被调用的程序
- Hadoop用Java实现RPC
- 客户端
- 服务器端
- 远程过程调用(协议)
MyRPCClient.java


1 package rpc.client;
2
3 import java.io.IOException;
4 import java.net.InetSocketAddress;
5
6 import org.apache.hadoop.conf.Configuration;
7 import org.apache.hadoop.ipc.RPC;
8
9 import rpc.server.MyInterface;
10
11 public class MyRPCClient {
12
13 public static void main(String[] args) throws IOException {
14 // 使用Hadoop RPC框架调用Server端程序
15 // 得到Server部署对象的代理对象
16 MyInterface proxy = RPC.getProxy(MyInterface.class,
17 MyInterface.versionID,
18 new InetSocketAddress("localhost",7788),
19 new Configuration());
20 // 使用代理对象调用Server程序
21 String result = proxy.sayHello("Tom");
22 System.out.println(result);
23 }
24 }
MyInterface.java
1 package rpc.server;
2
3 import org.apache.hadoop.ipc.VersionedProtocol;
4
5 public interface MyInterface extends VersionedProtocol{
6 // 定义版本号
7 // 使用版本号进行签名
8 public static long versionID = 1;
9
10 // 定义业务方法
11 public String sayHello(String name);
12 }
MyInterfaceImpl.java
1 package rpc.server;
2
3 import java.io.IOException;
4
5 import org.apache.hadoop.ipc.ProtocolSignature;
6
7 public class MyInterfaceImpl implements MyInterface{
8
9 @Override
10 public ProtocolSignature getProtocolSignature(
11 String arg0, long arg1, int arg2)
12 throws IOException {
13 // 通过版本号定义签名信息
14 return new ProtocolSignature(MyInterface.versionID,null);
15 }
16
17 @Override
18 public long getProtocolVersion(String arg0, long arg1)
19 throws IOException {
20 // 返回版本号
21 return MyInterface.versionID;
22 }
23
24 @Override
25 public String sayHello(String name) {
26 System.out.println("**********调用Server端**********");
27 return "Hello " + name;
28 }
29 }
MyRPCServer.java
1 package rpc.server;
2
3 import java.io.IOException;
4
5 import org.apache.hadoop.HadoopIllegalArgumentException;
6 import org.apache.hadoop.conf.Configuration;
7 import org.apache.hadoop.ipc.RPC;
8 import org.apache.hadoop.ipc.RPC.Server;
9
10 public class MyRPCServer {
11 public static void main(String[] args) throws HadoopIllegalArgumentException, IOException {
12 // 利用Hadoop的RPC框架实现RPC Server
13
14 // 使用RPC Builder构建
15 RPC.Builder builder = new RPC.Builder(new Configuration());
16
17 // 定义Server的参数
18 builder.setBindAddress("localhost");
19 builder.setPort(7788);
20
21 // 部署程序
22 builder.setProtocol(MyInterface.class);
23 builder.setInstance(new MyInterfaceImpl());
24
25 // 创建RPC Server
26 Server server = builder.build();
27
28 server.start();
29 }
30 }



- Java动态代理对象
- 如果一个类的名字有$,表示这是一个代理对象
- 是一种包装设计模式
- 可以增强类的功能
- 应用:数据库连接池
- newProxyInstance 参数
- ClassLoader 类加载器
- Class<?>[ ] 真正对象实现的接口
- InvocationHandler 实现接口来处理客户端调用
MyBusiness.java
1 package proxy;
2
3 public interface MyBusiness {
4 public void method1();
5 public void method2();
6 }
MyBusinessImpl.java
1 package proxy;
2
3 public class MyBusinessImpl implements MyBusiness {
4
5 @Override
6 public void method1() {
7 System.out.println("*********method1*********");
8 }
9
10 @Override
11 public void method2() {
12 System.out.println("*********method2*********");
13 }
14 }
TestMain.java
1 package proxy;
2
3 import java.lang.reflect.InvocationHandler;
4 import java.lang.reflect.Method;
5 import java.lang.reflect.Proxy;
6
7 public class TestMain {
8
9 public static void main(String[] args) {
10 // 创建对象
11 MyBusiness obj = new MyBusinessImpl();
12 // 创建代理对象
13 MyBusiness proxy = (MyBusiness) Proxy.newProxyInstance(TestMain.class.getClassLoader(),
14 obj.getClass().getInterfaces(),
15 new InvocationHandler(){
16 @Override
17 public Object invoke(Object proxy,Method method,Object[] args)throws Throwable {
18 if(method.getName().equals("method1")) {
19 //重写
20 System.out.println("*************代理对象中的method1*************");
21 return null;
22 }else {
23 // 其他方法
24 return method.invoke(obj, args);
25 }
26 }
27 });
28 // 通过代理对象调用真正对象
29 proxy.method1();
30 proxy.method2();
31 }
32 }

命令
- hdfs dfs
- -ls /:查看所有目录下的文件
- -ls /data:查看/data下的所有文件
- -mkdir /data:在hdfs上创建目录/data
- -cp:拷贝文件
- -rm:删除文件
- -get:复制文件到本地
参考
HDFS文件存储格式
https://blog.csdn.net/chuya1943/article/details/100618738
https://blog.csdn.net/weixin_40235225/article/details/85118333
[DB] HDFS的更多相关文章
- Hive-1.2.1_03_DDL操作
Hive官方文档:Home-UserDocumentation Hive DDL官方文档:LanguageManual DDL 参考文章:Hive 用户指南 注意:各个语句的版本时间,有的是在 hiv ...
- Python记录-python执行shell命令
# coding=UTF-8 import os def distcp(): nncheck = os.system('lsof -i:8020') dncheck = os.system('lsof ...
- FAILED: SemanticException Unable to determine if hdfs://tmaster:8020/user/root/words.db/test_t2 is encrypted
使用hive时,建立数据库,建表,写数据: 读数据:select * from test_t2; 报错SemanticException 原因:建表时使用了其他路径,或者在另一个路径的数据库(建立数 ...
- hive和hbase本质区别——hbase本质是OLTP的nosql DB,而hive是OLAP 底层是hdfs,需从已有数据库同步数据到hdfs;hive可以用hbase中的数据,通过hive表映射到hbase表
对于hbase当前noSql数据库的一种,最常见的应用场景就是采集的网页数据的存储,由于是key-value型数据库,可以再扩展到各种key-value应用场景,如日志信息的存储,对于内容信息不需要完 ...
- mapreduce导出MSSQL的数据到HDFS
今天想通过一些数据,来测试一下我的<基于信息熵的无字典分词算法>这篇文章的正确性.就写了一下MapReduce程序从MSSQL SERVER2008数据库里取数据分析.程序发布到hadoo ...
- Sqoop_mysql,hive,hdfs导入导出操作
前言: 搭建环境,这里使用cdh版hadoop+hive+sqoop+mysql 下载 hadoop-2.5.0-cdh5.3.6.tar.gz hive-0.13.1-cdh5.3.6.tar.gz ...
- HDFS之HBase伪分布安装
1.HBase简介 HBase是Apache Hadoop中的一个子项目,Hbase依托于Hadoop的HDFS作为最基本存储基础单元,通过使用hadoop的DFS工具就可以看到这些这些数据 存储文件 ...
- 【原创】大叔经验分享(44)hdfs副本数量
当hdfs空间不足时,除了删除临时数据或垃圾数据之外,还可以适当调整部分大目录的副本数量,多管齐下: 1 查看 $ hdfs dfs -ls /user/hive/warehouse/temp.db/ ...
- HDFS之HA
HDFS高可用环境HA的架构 HDFS组件由一个对外提供服务的namenode(存储元数据)和N个datanode组成:Zookeeper有三个作用:1.为了统一配置文件 config 2.多个节点的 ...
随机推荐
- Elasticsearch 分页查询
目录 前言 from + size search after scroll api 总结 参考资料 前言 我们在实际工作中,有很多分页的需求,商品分页.订单分页等,在MySQL中我们可以使用limit ...
- 博文推荐|多图详解 Apache Pulsar 消息存储模型
关于 Apache Pulsar Apache Pulsar 是 Apache 软件基金会顶级项目,是下一代云原生分布式消息流平台,集消息.存储.轻量化函数式计算为一体,采用计算与存储分离架构设计,支 ...
- 【剑指offer】7:斐波那契数列
题目描述: 大家都知道斐波那契数列,现在要求输入一个整数n,请你输出斐波那契数列的第n项(从0开始,第0项为0,第1项是1).假设 n≤39 解题思路: 斐波拉契数列:1,1,2,3,5,8--,总结 ...
- 【macOS】显示/隐藏 允许“任何来源”的应用
问题产生 在macOS中安装某些版本软件时会提示: "xxx"已损坏,打不开.您应该将它移动到废纸篓. 某些情况下实际上并不是软件已损坏,而是因为macOS对于开发者的验证导致软件 ...
- ElementPlusViteStarterPnpm版本
1 起因 由于最近Vite升级了2.x版本,项目中需要改动的东西有点多,本来想基于官方给出的starter重做,但是又看到了一个叫pnpm的仓库,构建速度会比原生npm/yarn快两倍以上: 因此模仿 ...
- Mybatis3源码笔记(一)环境搭建
1. 源码下载 地址:https://github.com/mybatis/mybatis-3.git. 国内访问有时确实有点慢,像我就直接先fork.然后从git上同步到国内的gitte上,然后在i ...
- 【pytest官方文档】解读fixtures - 11. fixture的执行顺序,3要素详解(长文预警)
当pytest要执行一个测试函数,这个测试函数还请求了fixture函数,那么这时候pytest就要先确定fixture的执行顺序了. 影响因素有三: scope,就是fixture函数的作用范围,比 ...
- Docker系列——InfluxDB+Grafana+Jmeter性能监控平台搭建(三)
在之前系列博文中,已经介绍完了数据采集和数据存储,那数据如何展示呢?所以今天就专门来讲下数据如何展示的问题. 以前博文参考: Docker系列--InfluxDB+Grafana+Jmeter性能监控 ...
- Faiss源码剖析:类结构分析
摘要:在下文中,我将尝试通过Faiss源码中各种类结构的设计来梳理Faiss中的各种概念以及它们之间的关系. 本文分享自华为云社区<Faiss源码剖析(一):类结构分析>,原文作者:HW0 ...
- 谈谈SSRF漏洞挖掘
最近看了很多ssrf漏洞挖掘技巧和自己以往挖掘ssrf漏洞的一些技巧和经验,简单的总结下: 之前自己总结的: ssrf=服务器端请求伪造 基于服务器攻击 url链接 -->内网漫游/内网服务探测 ...