残差网络resnet理解与pytorch代码实现
写在前面
深度残差网络(Deep residual network, ResNet)自提出起,一次次刷新CNN模型在ImageNet中的成绩,解决了CNN模型难训练的问题。何凯明大神的工作令人佩服,模型简单有效,思想超凡脱俗。
直观上,提到深度学习,我们第一反应是模型要足够“深”,才可以提升模型的准确率。但事实往往不尽如人意,先看一个ResNet论文中提到的实验,当用一个平原网络(plain network)构建很深层次的网络时,56层的网络的表现相比于20层的网络反而更差了。说明网络随着深度的加深,会更加难以训练。
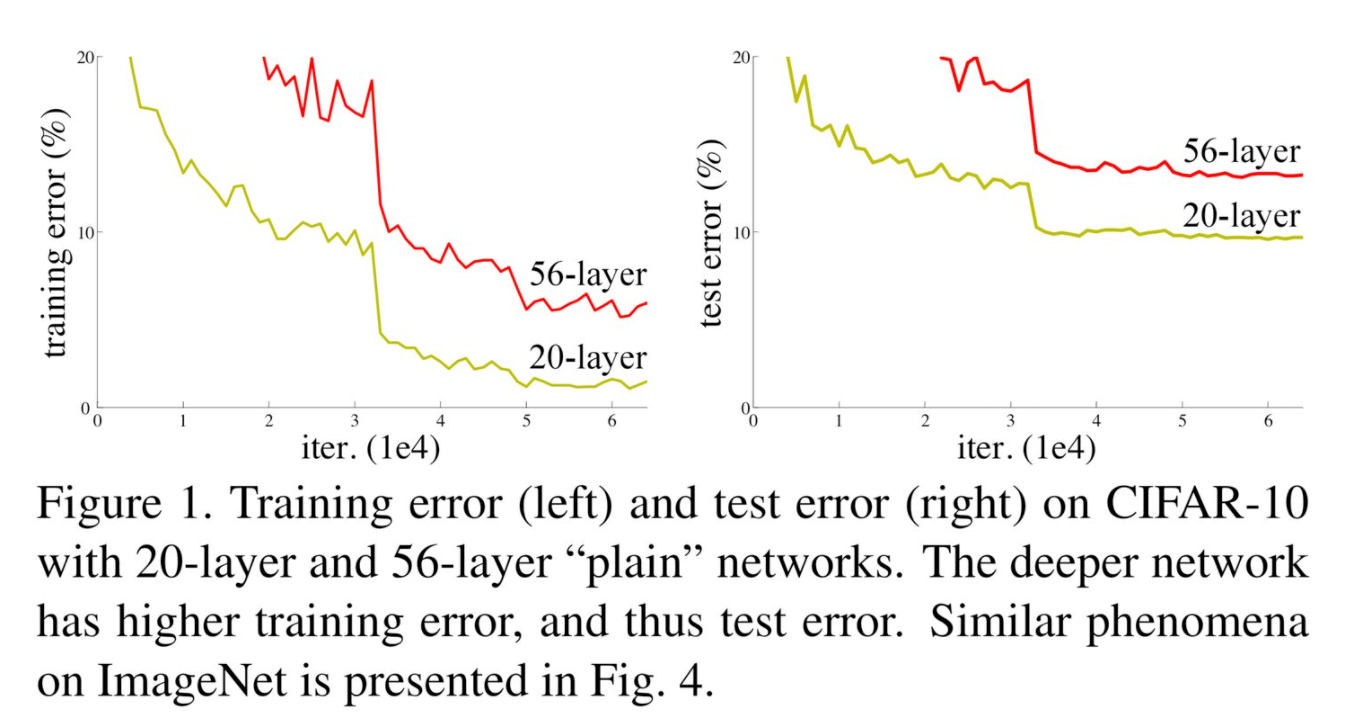
图一:模型退化问题
若模型随着网络深度的增加,准确率先上升,然后达到饱和,深度增加准确率下降。那么如果在模型达到饱和时,后面接上几个恒等变换层,这样可以保证误差不会增加,resnet便是这种思想来解决网络退化问题。
第一部分
模型
假设网络的输入是x, 期望输出为H(x),我们转化一下思路,把网络要学到的H(x)转化为期望输出H(x)与输出x之间的差值F(x) = H(x) - x。当残差接近为0时, 相当于网络在此层仅仅做了恒等变换,而不会使网络的效果下降。
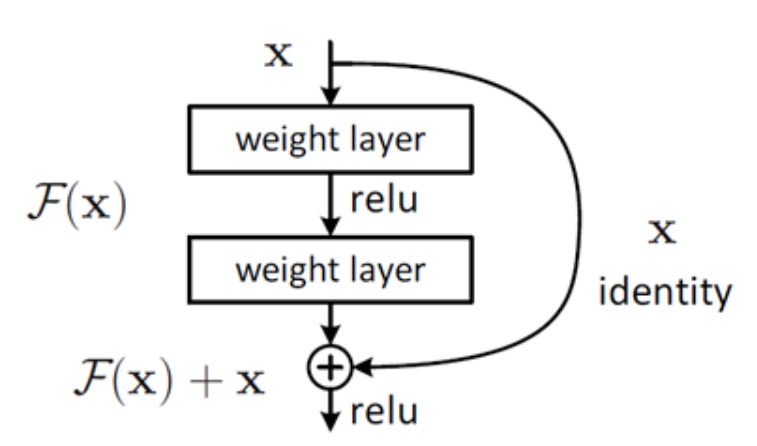
图二:残差结构
残差为什么容易学习?
此处参考一位知乎大佬的分析(原文在文末有链接),因为网络要学习的残差项通常比较小:
其中 和
分别表示的是第
个残差单元的输入和输出,注意每个残差单元一般包含多层结构。
是残差函数,表示学习到的残差,而
表示恒等映射,
是ReLU激活函数。基于上式,我们求得从浅层
到深层
的学习特征为:
利用链式规则,可以求得反向过程的梯度:
式子的第一个因子 表示的损失函数到达
的梯度,小括号中的1表明短路机制可以无损地传播梯度,而另外一项残差梯度则需要经过带有weights的层,梯度不是直接传递过来的。残差梯度不会那么巧全为-1,而且就算其比较小,有1的存在也不会导致梯度消失。所以残差学习会更容易。要注意上面的推导并不是严格的证明。
深度残差网络结构如下:
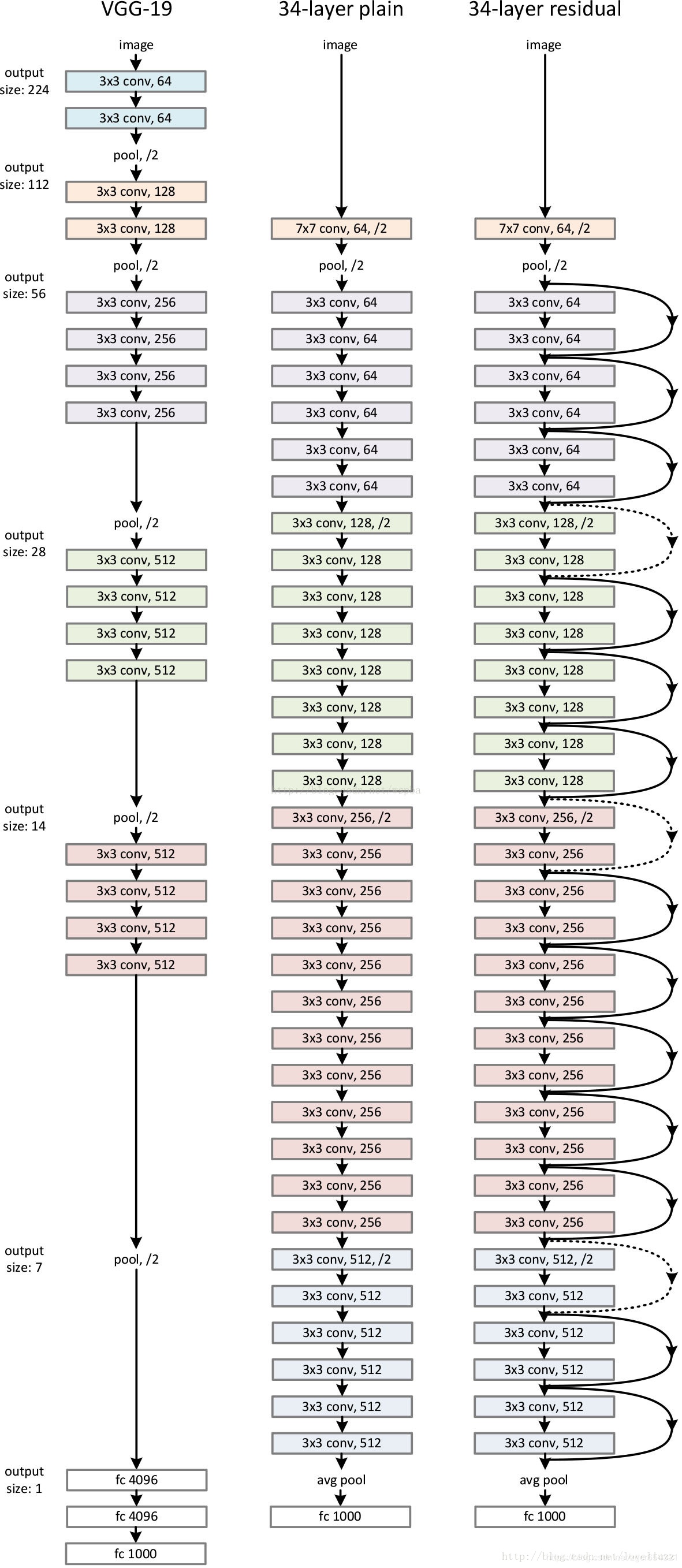
第二部分
pytorch代码实现
# -*- coding:utf-8 -*-
# handwritten digits recognition
# Data: MINIST
# model: resnet
# date: 2021.10.8 14:18
import math
import torch
import torchvision
import torchvision.transforms as transforms
import torch.nn as nn
import torch.utils.data as Data
import torch.optim as optim
import pandas as pd
import matplotlib.pyplot as plt
train_curve = []
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# param
batch_size = 100
n_class = 10
padding_size = 15
epoches = 10
train_dataset = torchvision.datasets.MNIST('./data/', train=True, transform=transforms.ToTensor(), download=True)
test_dataset = torchvision.datasets.MNIST('./data/', train=False, transform=transforms.ToTensor(), download=False)
train = Data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True, num_workers=5)
test = Data.DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=False, num_workers=5)
def gelu(x):
"Implementation of the gelu activation function by Hugging Face"
return x * 0.5 * (1.0 + torch.erf(x / math.sqrt(2.0)))
class ResBlock(nn.Module):
# 残差块
def __init__(self, in_size, out_size1, out_size2):
super(ResBlock, self).__init__()
self.conv1 = nn.Conv2d(
in_channels = in_size,
out_channels = out_size1,
kernel_size = 3,
stride = 2,
padding = padding_size
)
self.conv2 = nn.Conv2d(
in_channels = out_size1,
out_channels = out_size2,
kernel_size = 3,
stride = 2,
padding = padding_size
)
self.batchnorm1 = nn.BatchNorm2d(out_size1)
self.batchnorm2 = nn.BatchNorm2d(out_size2)
def conv(self, x):
# gelu效果比relu好呀哈哈
x = gelu(self.batchnorm1(self.conv1(x)))
x = gelu(self.batchnorm2(self.conv2(x)))
return x
def forward(self, x):
# 残差连接
return x + self.conv(x)
# resnet
class Resnet(nn.Module):
def __init__(self, n_class = n_class):
super(Resnet, self).__init__()
self.res1 = ResBlock(1, 8, 16)
self.res2 = ResBlock(16, 32, 16)
self.conv = nn.Conv2d(
in_channels = 16,
out_channels = n_class,
kernel_size = 3,
stride = 2,
padding = padding_size
)
self.batchnorm = nn.BatchNorm2d(n_class)
self.max_pooling = nn.AdaptiveAvgPool2d(1)
def forward(self, x):
# x: [bs, 1, h, w]
# x = x.view(-1, 1, 28, 28)
x = self.res1(x)
x = self.res2(x)
x = self.max_pooling(self.batchnorm(self.conv(x)))
return x.view(x.size(0), -1)
resnet = Resnet().to(device)
loss_fn = nn.CrossEntropyLoss()
optimizer = optim.SGD(params=resnet.parameters(), lr=1e-2, momentum=0.9)
# train
total_step = len(train)
sum_loss = 0
for epoch in range(epoches):
for i, (images, targets) in enumerate(train):
optimizer.zero_grad()
images = images.to(device)
targets = targets.to(device)
preds = resnet(images)
loss = loss_fn(preds, targets)
sum_loss += loss.item()
loss.backward()
optimizer.step()
if (i+1)%100==0:
print('[{}|{}] step:{}/{} loss:{:.4f}'.format(epoch+1, epoches, i+1, total_step, loss.item()))
train_curve.append(sum_loss)
sum_loss = 0
# test
resnet.eval()
with torch.no_grad():
correct = 0
total = 0
for images, labels in test:
images = images.to(device)
labels = labels.to(device)
outputs = resnet(images)
_, maxIndexes = torch.max(outputs, dim=1)
correct += (maxIndexes==labels).sum().item()
total += labels.size(0)
print('in 1w test_data correct rate = {:.4f}'.format((correct/total)*100))
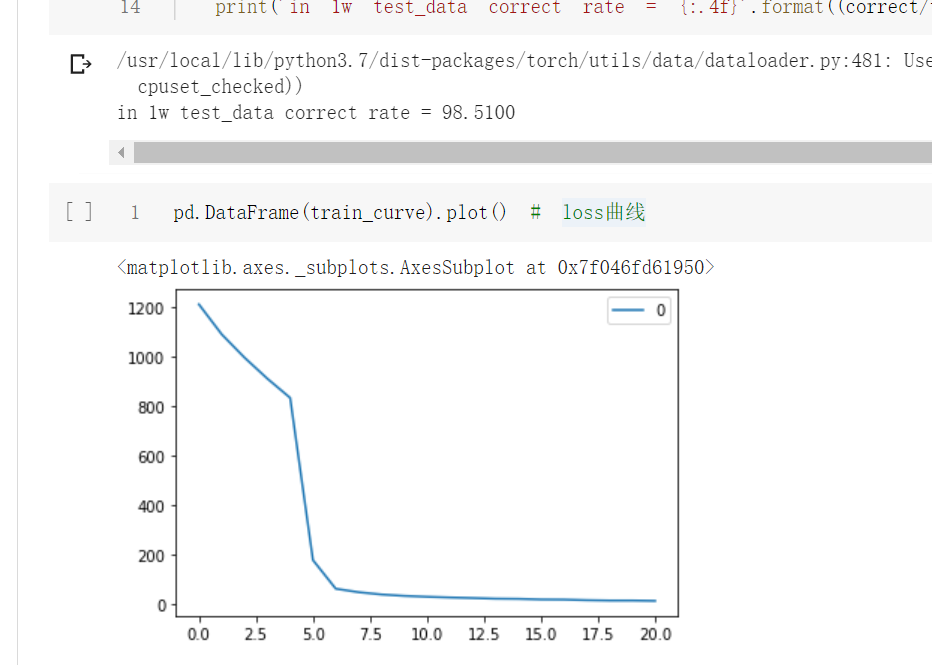
pd.DataFrame(train_curve).plot() # loss曲线
测试了1万条测试集样本结果:
代码链接:
jupyter版本:https://github.com/PouringRain/blog_code/blob/main/deeplearning/resnet.ipynb
py版本:https://github.com/PouringRain/blog_code/blob/main/deeplearning/resnet.py
喜欢的话,给萌新的github仓库一颗小星星哦……^ _^
参考资料:
https://zhuanlan.zhihu.com/p/31852747
https://zhuanlan.zhihu.com/p/80226180
残差网络resnet理解与pytorch代码实现的更多相关文章
- 从头学pytorch(二十):残差网络resnet
残差网络ResNet resnet是何凯明大神在2015年提出的.并且获得了当年的ImageNet比赛的冠军. 残差网络具有里程碑的意义,为以后的网络设计提出了一个新的思路. googlenet的思路 ...
- 深度学习——手动实现残差网络ResNet 辛普森一家人物识别
深度学习--手动实现残差网络 辛普森一家人物识别 目标 通过深度学习,训练模型识别辛普森一家人动画中的14个角色 最终实现92%-94%的识别准确率. 数据 ResNet介绍 论文地址 https:/ ...
- 深度残差网络(ResNet)
引言 对于传统的深度学习网络应用来说,网络越深,所能学到的东西越多.当然收敛速度也就越慢,训练时间越长,然而深度到了一定程度之后就会发现越往深学习率越低的情况,甚至在一些场景下,网络层数越深反而降低了 ...
- 深度残差网络——ResNet学习笔记
深度残差网络—ResNet总结 写于:2019.03.15—大连理工大学 论文名称:Deep Residual Learning for Image Recognition 作者:微软亚洲研究院的何凯 ...
- 使用dlib中的深度残差网络(ResNet)实现实时人脸识别
opencv中提供的基于haar特征级联进行人脸检测的方法效果非常不好,本文使用dlib中提供的人脸检测方法(使用HOG特征或卷积神经网方法),并使用提供的深度残差网络(ResNet)实现实时人脸识别 ...
- 残差网络ResNet笔记
发现博客园也可以支持Markdown,就把我之前写的博客搬过来了- 欢迎转载,请注明出处:http://www.cnblogs.com/alanma/p/6877166.html 下面是正文: Dee ...
- CNN卷积神经网络_深度残差网络 ResNet——解决神经网络过深反而引起误差增加的根本问题,Highway NetWork 则允许保留一定比例的原始输入 x。(这种思想在inception模型也有,例如卷积是concat并行,而不是串行)这样前面一层的信息,有一定比例可以不经过矩阵乘法和非线性变换,直接传输到下一层,仿佛一条信息高速公路,因此得名Highway Network
from:https://blog.csdn.net/diamonjoy_zone/article/details/70904212 环境:Win8.1 TensorFlow1.0.1 软件:Anac ...
- 残差网络resnet学习
Deep Residual Learning for Image Recognition 微软亚洲研究院的何凯明等人 论文地址 https://arxiv.org/pdf/1512.03385v1.p ...
- 深度残差网络(DRN)ResNet网络原理
一说起“深度学习”,自然就联想到它非常显著的特点“深.深.深”(重要的事说三遍),通过很深层次的网络实现准确率非常高的图像识别.语音识别等能力.因此,我们自然很容易就想到:深的网络一般会比浅的网络效果 ...
随机推荐
- 未解决:为什么在struts2下新建ognl的包,会出错?
首先开始在src下新建了一个名叫ognl的包: 发现在其中放置了一个loginAction,即使是最简单的跳转都不能实现: 直接抛出了java.lang.Exception; 传递参数更出现了异常: ...
- UVA1620 Lazy Susan(结论证明)
结论: 当 \(n\geq 6\) 时,若 \(n\) 是奇数且输入序列的逆序对数是奇数,则无解,否则有解. 当 \(n=4\) 或 \(n=5\) 时,答案个数及其有限,只有这个环是 \(1\) 到 ...
- 一个简单的 aiax请求例子
<!DOCTYPE html> <html> <head> <meta http-equiv="content-type" content ...
- linux多次登录失败锁定账户
2021-07-22 1.配置对系统进行失败的ssh登录尝试后锁定用户帐户 # 配置登录访问的限制 vi /etc/pam.d/system-auth 或者 vi etc/pam.d/password ...
- Qt5之正则表达式
字符 描述 \ 将下一个字符标记为一个特殊字符.或一个原义字符.或一个 向后引用.或一个八进制转义符.例如,'n' 匹配字符 "n".'\n' 匹配一个换行符.序列 '\\' 匹配 ...
- 基于Linux系统Samba服务器的部署
1.基础信息 用 Internet 文件系统 CIFS(Common Internet File System)是适用于MicrosoftWindows 服务器和客户端的标准文件和打印机共享系统信息块 ...
- Zookeeper:进大厂不得不学的分布式协同利器!
大家好,我是冰河~~ 最近,有很多小伙伴让我更新一些Zookeeper的文章,正好也趁着清明假期把之前自己工作过程当中总结的Zookeeper知识点梳理了一番,打算写一个[精通Zookeeper系列] ...
- 微信支付 V3 开发教程(一):初识 Senparc.Weixin.TenPayV3
前言 我在 9 年前发布了 Senparc.Weixin SDK 第一个开源版本,一直维护至今,如今 Stras 已经破 7K,这一路上得到了 .NET 社区的积极响应和支持,也受到了非常多的宝贵建议 ...
- Linux下查看哪个网口插了网线
场景: 一台服务器有多个网卡,一个网卡有多个网口,当插了一根网线的时候,不知道网线是插在哪一个网口. 1.查看网口信息 2.查看网口是否插了网线(命令ethtool) 命令:ethtool + 网口名 ...
- Intel® QAT加速卡之编程demo框架
QAT demo流程框架 示例一: 代码路径:qat1.5.l.1.13.0-19\quickassist\lookaside\access_layer\src\sample_code\functio ...