数据同步Datax与Datax_web的部署以及使用说明
一、DataX3.0概述
DataX 是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。
请看下图:
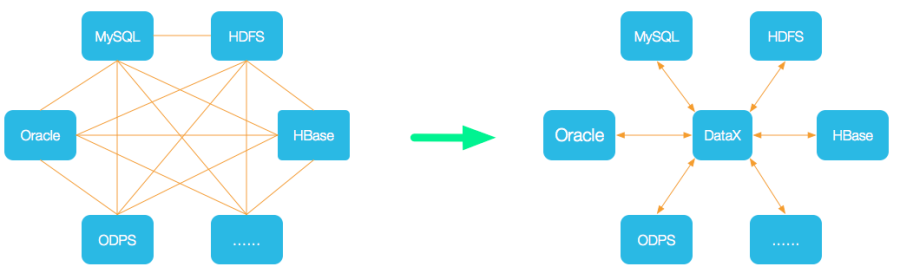
设计理念:
为了解决异构数据源同步问题,DataX将复杂的网状的同步链路变成了星型数据链路,DataX作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到DataX,便能跟已有的数据源做到无缝数据同步。
当前使用状况:
DataX在阿里巴巴集团内被广泛使用,承担了所有大数据的离线同步业务,并已持续稳定运行了6年之久。目前每天完成同步8w多道作业,每日传输数据量超过300TB。
二、DataX3.0框架设计

DataX本身作为离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中。
1、Reader:Reader为数据采集模块,负责采集数据源的数据,将数据发送给Framework。
2、Writer: Writer为数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。
3、Framework:Framework用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。
三、插件体系
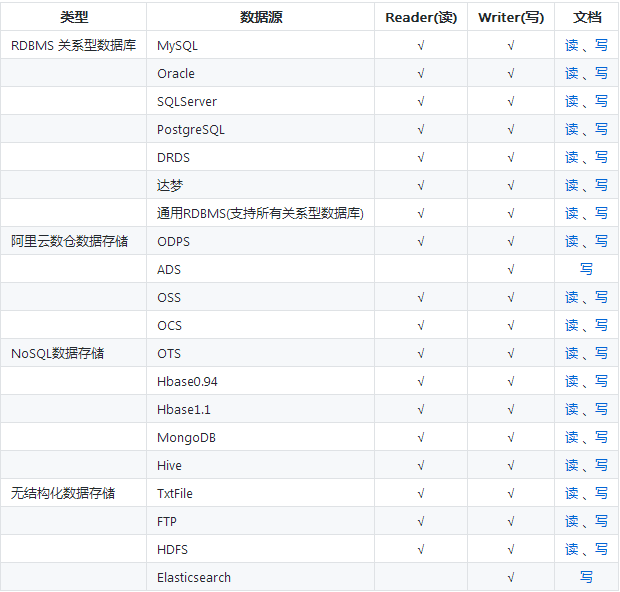
DataX目前已经有了比较全面的插件体系,主流的RDBMS数据库、NOSQL、大数据计算系统都已经接入。
DataX目前支持数据如下:
四、DataX3.0核心架构
DataX 3.0 开源版本支持单机多线程模式完成同步作业运行,按一个DataX作业生命周期的时序图,从整体架构设计非常简要说明DataX各个模块相互关系。
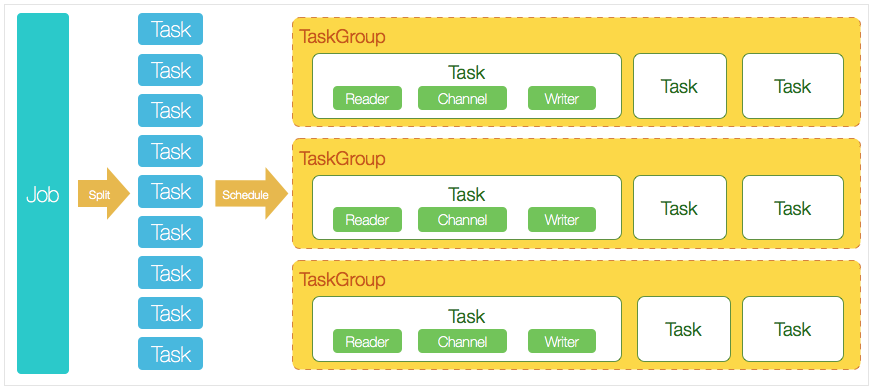
1、DataX完成单个数据同步的作业,我们称之为Job,DataX接受到一个Job之后,将启动一个进程来完成整个作业同步过程。
DataX Job模块是单个作业的中枢管理节点,承担了数据清理、子任务切分(将单一作业计算转化为多个子Task)、TaskGroup管理等功能。
2、DataXJob启动后,会根据不同的源端切分策略,将Job切分成多个小的Task(子任务),以便于并发执行。Task便是DataX作业的最小单元,每一个Task都会负责一部分数据的同步工作。
3、切分多个Task之后,DataX Job会调用Scheduler模块,根据配置的并发数据量,将拆分成的Task重新组合,组装成TaskGroup(任务组)。每一个TaskGroup负责以一定的并发运行完毕分配好的所有Task,默认单个任务组的并发数量为5。
4、每一个Task都由TaskGroup负责启动,Task启动后,会固定启动Reader—>Channel—>Writer的线程来完成任务同步工作。
5、DataX作业运行起来之后, Job监控并等待多个TaskGroup模块任务完成,等待所有TaskGroup任务完成后Job成功退出。否则,异常退出,进程退出值非0。
五、DataX调度流程:
用户提交了一个DataX作业,并且配置了20个并发,目的是将一个100张分表的mysql数据同步到odbs里面。 DataX的调度决策思路是:
1、DataXJob根据分库分表切分成了100个Task。
2、根据20个并发,DataX计算共需要分配4个TaskGroup。
3、4个TaskGroup平分切分好的100个Task,每一个TaskGroup负责以5个并发共计运行25个Task。
六、Datax3.0安装部署
1、环境准备
Linux
jdk 1.8
python 2.7.5(datax是由python2开发的)
2、datax下载地址
https://github.com/alibaba/DataX?spm=a2c4e.11153940.blogcont59373.11.7a684c4fvubOe1
查看安装成功:在bin目录下执行 python datax.py ../job/job.json
3、查看配置文件
在bin目录下已经给出了样例配置,但不同的数据源配置文件不一样。通过命令查看配置模板
# python datax.py -r {YOUR_READER} -w {YOUR_WRITER}
示例:[xxx@xxxbin]$ python datax.py -r mysqlreader -w hdfswriter
七、json配置文件模板说明
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"querySql": "", #自定义sql,支持多表关联,当用户配置querySql时,直接忽略table、column、where条件的配置。
"fetchSize": "", #默认1024,该配置项定义了插件和数据库服务器端每次批量数据获取条数,该值决定了DataX和服务器端的网络交互次数,能够较大的提升数据抽取性能,注意,该值过大(>2048)可能造成DataX进程OOM
"splitPk": "db_id", #仅支持整形型数据切分;如果指定splitPk,表示用户希望使用splitPk代表的字段进行数据分片,如果该值为空,代表不切分,使用单通道进行抽取
"column": [], #"*"默认所有列,支持列裁剪,列换序
"connection": [
{
"jdbcUrl": ["jdbc:mysql://IP:3306/database?useUnicode=true&characterEncoding=utf8"],
"table": [] #支持多张表同时抽取
}
],
"password": "",
"username": "",
"where": "" #指定的column、table、where条件拼接SQL,可以指定limit 10,也可以增量数据同步,如果该值为空,代表同步全表所有的信息
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [], #必须指定字段名,字段类型,{"name":"","tpye":""}
"compress": "", #hdfs文件压缩类型,默认不填写意味着没有压缩。其中:text类型文件支持压缩类型有gzip、bzip2;orc类型文件支持的压缩类型有NONE、SNAPPY(需要用户安装SnappyCodec)。
"defaultFS": "", #Hadoop hdfs文件系统namenode节点地址。
"fieldDelimiter": "", #需要用户保证与创建的Hive表的字段分隔符一致
"fileName": "", #HdfsWriter写入时的文件名,需要指定表中所有字段名和字段类型,其中:name指定字段名,type指定字段类型。
"fileType": "", #目前只支持用户配置为”text”或”orc”
"path": "", #存储到Hadoop hdfs文件系统的路径信息,hive表在hdfs上的存储路径
"hadoopConfig": {} #hadoopConfig里可以配置与Hadoop相关的一些高级参数,比如HA的配置。
"writeMode": "" #append,写入前不做任何处理,文件名不冲突;nonConflict,如果目录下有fileName前缀的文件,直接报错。
}
}
}
],
"setting": {
"speed": { #流量控制
"byte": 1048576, #控制传输速度,单位为byte/s,DataX运行会尽可能达到该速度但是不超过它
"channel": "" #控制同步时的并发数
}
"errorLimit": { #脏数据控制
"record": 0 #对脏数据最大记录数阈值(record值)或者脏数据占比阈值(percentage值,当数量或百分比,DataX Job报错退出
}
}
}
}
{
"job":{
"setting":{
"speed":{
"channel":1
}
},
"content":[
{
"reader":{
"name":"sqlserverreader",
"parameter":{
"username":"xxxx",
"password":"xxxx",
"column":[
"UserGroupId",
"Name"
],
"connection":[
{
"table": [
"UserGroups"
],
"jdbcUrl":[
"jdbc:sqlserver://xxxx:1433;DatabaseName=TEST"
]
}
]
}
},
"writer":{
"name":"mysqlwriter",
"parameter":{
"username":"xxxx",
"password":"xxxx",
"column":[
"user_group_id",
"user_group_name"
],
"connection":[
{
"jdbcUrl": "jdbc:mysql://xxxx:3306/test_recruit",
"table": ["gcp_user_groups"]
}
],
"visible":false,
"encoding":"UTF-8"
}
}
}
]
}
}
八、datax-web安装
1、参考官方的安装,包可以这里下载
https://github.com/WeiYe-Jing/datax-web/blob/master/doc/datax-web/datax-web-deploy.md
2、在选定的安装目录,解压安装包
tar -zxvf datax-web-{VERSION}.tar.gz
3、执行安装脚本(需要安装数据库mysql)
[root@roobbin datax-web-2.1.2]# ./bin/install.sh
2020-10-17 10:00:09.430 [INFO] (22745) Creating directory: [/usr/local/datax-web-2.1.2/bin/../modules].
2020-10-17 10:00:09.459 [INFO] (22745) ####### Start To Uncompress Packages ######
2020-10-17 10:00:09.462 [INFO] (22745) Uncompressing....
Do you want to decompress this package: [datax-admin_2.1.2_1.tar.gz]? (Y/N)y
2020-10-17 10:00:17.298 [INFO] (22745) Uncompress package: [datax-admin_2.1.2_1.tar.gz] to modules directory
Do you want to decompress this package: [datax-executor_2.1.2_1.tar.gz]? (Y/N)
按照提示输入数据库地址,端口号,用户名,密码以及数据库名称,大部分情况下即可快速完成初始化。 如果服务上并没有安装mysql命令,则可以取用目录下/bin/db/datax-web.sql脚本去手动执行,完成后修改相关配置文件
vi ./modules/datax-admin/conf/bootstrap.properties
#Database
#DB_HOST=
#DB_PORT=
#DB_USERNAME=
#DB_PASSWORD=
#DB_DATABASE=
在项目目录下/modules/datax-execute/bin/env.properties 指定PYTHON_PATH的路径
vi ./modules/{module_name}/bin/env.properties ### 执行datax的python脚本地址
PYTHON_PATH= ### 保持和datax-admin服务的端口一致;默认是9527,如果没改datax-admin的端口,可以忽略
DATAX_ADMIN_PORT=
4、启动DataX_web
./bin/start-all.sh
进入可视化界面
http://ip:9527/index.html
登陆用户名admin 密码123456
over!
数据同步Datax与Datax_web的部署以及使用说明的更多相关文章
- 数据同步DataX
数据同步那些事儿(优化过程分享) 简介 很久之前就想写这篇文章了,主要是介绍一下我做数据同步的过程中遇到的一些有意思的内容,和提升效率的过程. 当前在数据处理的过程中,数据同步如同血液一般充满全过 ...
- Spark记录-阿里巴巴开源工具DataX数据同步工具使用
1.官网下载 下载地址:https://github.com/alibaba/DataX DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 MySQL.Oracle.SqlSe ...
- 数据同步工具Sqoop和DataX
在日常大数据生产环境中,经常会有集群数据集和关系型数据库互相转换的需求,在需求选择的初期解决问题的方法----数据同步工具就应运而生了.此次我们选择两款生产环境常用的数据同步工具进行讨论 Sqoop ...
- TiDB 部署及数据同步
简介 TiDB 是 PingCAP 公司受 Google Spanner / F1 论文启发而设计的开源分布式 HTAP (Hybrid Transactional and Analytical Pr ...
- 基于datax的数据同步平台
一.需求 由于公司各个部门对业务数据的需求,比如进行数据分析.报表展示等等,且公司没有相应的系统.数据仓库满足这些需求,最原始的办法就是把数据提取出来生成excel表发给各个部门,这个功能已经由脚本转 ...
- 环境篇:数据同步工具DataX
环境篇:数据同步工具DataX 1 概述 https://github.com/alibaba/DataX DataX是什么? DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 ...
- centos7部署inotify与rsync实现实时数据同步
实验环境:CentOS Linux release 7.6.1810 node1:192.168.216.130 客户端(向服务端发起数据同步) node2:192.168.216.132 服务端(接 ...
- 高可用数据同步方案-SqlServer迁移Mysql实战
简介 随着业务量的上升,以前的架构已经不满足业务的发展,数据作为业务中最重要的一环,需要有更好的架构作为支撑.目前我司有sql server转mysql的需求,所以结合当前业务,我挑选了阿里云开源的一 ...
- 基于 MySQL Binlog 的 Elasticsearch 数据同步实践 原
一.背景 随着马蜂窝的逐渐发展,我们的业务数据越来越多,单纯使用 MySQL 已经不能满足我们的数据查询需求,例如对于商品.订单等数据的多维度检索. 使用 Elasticsearch 存储业务数据可以 ...
随机推荐
- checked 和 prop() (散列性比较少的)
在<input class="sex1" type="radio" checked>男 checked表示该框会被默认选上 prop()操作的是D ...
- QT windows 应用程序 exe ,设置详细信息并解决中文乱码问题
原博主:https://blog.csdn.net/xiezhongyuan07/article/details/87691490 1.新创建一个.rc文件,随意命名,例如叫app.rc 并编辑 1 ...
- Play-book格式写法
Play-Book playbook的组成 play 角色(主机或者主机组) task 任务,演戏的动作 总结:playbook是有多个play组成,一个play有多个task:剧本由一个或者多个演员 ...
- 拉勾、Boss直聘、内推、100offer
BOSS直聘 拉勾.Boss直聘.内推.100offer
- OSI 七层参考模型与 TCP/IP 四层协议
OSI 七层参考模型 OSI (Open System Interconnect,开放系统互连参考模型)是由 ISO(国际标准化组织)定义的,它是个灵活的.稳健的和可互操作的模型,并不是协议,常用来分 ...
- ubuntu 14.04安装mysql-python
网上看到的是想安装mysql-python都得安装mysql本身,可是我就不想安装这个数据库,而是用于连接到别的服务器上的mysql,所以下面就是安装过程: 1. 直接运行: pip install ...
- Go语言设计模式之函数式选项模式
Go语言设计模式之函数式选项模式 本文主要介绍了Go语言中函数式选项模式及该设计模式在实际编程中的应用. 为什么需要函数式选项模式? 最近看go-micro/options.go源码的时候,发现了一段 ...
- 在Go语言项目中使用Zap日志库
在Go语言项目中使用Zap日志库 本文先介绍了Go语言原生的日志库的使用,然后详细介绍了非常流行的Uber开源的zap日志库,同时介绍了如何搭配Lumberjack实现日志的切割和归档. 在Go语言项 ...
- Ubuntu 20.04 Docker 安装并配置
前言 Docker 的使用能极大地方便我们的开发,减少环境搭建,依赖安装等繁琐且容易出错的问题. 安装 Docker Ubuntu 20.04 官方 apt 源中就有 Docker,我们可以直接通过 ...
- YOLOv4 资源环境配置和测试样例效果
YOLOv4 资源环境配置和测试样例效果 基本环境:cuda=10.0,cudnn>=7.0, opencv>=2.4 一.下载yolov4 git clone https://githu ...