大数据学习(15)—— B+树和LSM
这一节介绍数据库存储引擎常用的两种数据结构。作为关系型数据库的代表,MySql的InnoDB使用B+树来存储索引。作为NoSQL的代表,HBase使用的LSM树,我们来看看两者有什么区别。
B+树
B+树是大学数据结构里的内容。要了解什么是B+树,先从简单的开始。
二叉排序树
简单的说,二叉排序树首先是一个二叉树,每个结点最多只有两个分支,每个结点存储一个数据。左子树的所有结点都比父结点小(或相等),右子树的所有结点都比父结点大(或相等)。两个括号里的“或相等”附加说明,只能存在一个。
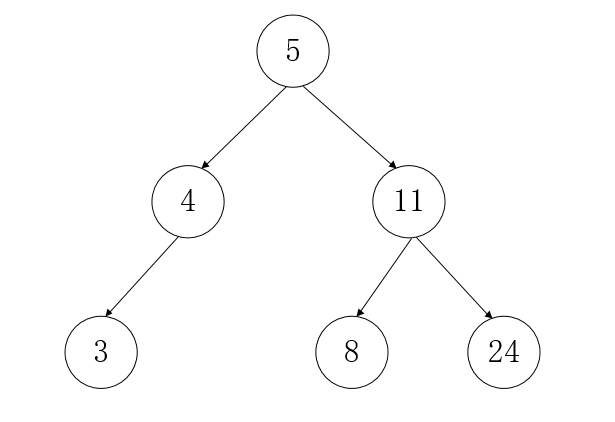
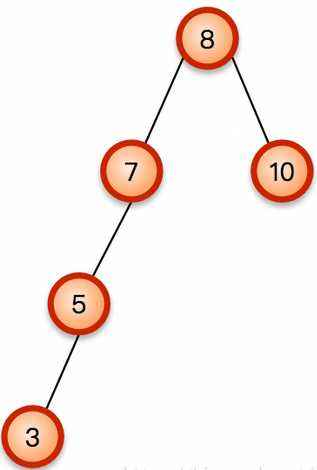
上面这两个图片都是二叉排序树。第一个树是平衡二叉树(任意结点左右子树高度差小于等于1,AVL),第二个树不平衡。不平衡会导致数据查询效率下降,因此要避免数据倾斜。
B树
二叉树的结点能保存数据,但是它存在缺点,如果数据量很大,它的深度会很大,查询效率低。比如:20层的满二叉树也只能存储100多万条数据。对于动辄数百万条记录的关系型数据库来说,要是查找一条记录如果要发生十几次IO,这个延时是不能接受的。
平衡树(B树,Balance Tree)是一种平衡多叉树,结点之间和结点内部也是有序的,每个结点有多个子结点,每个结点可以存储多个数据。二叉树因为瘦高,查询效率低。B树因为矮胖,降低了树的深度,查询效率快很多。具体定义自行百度。
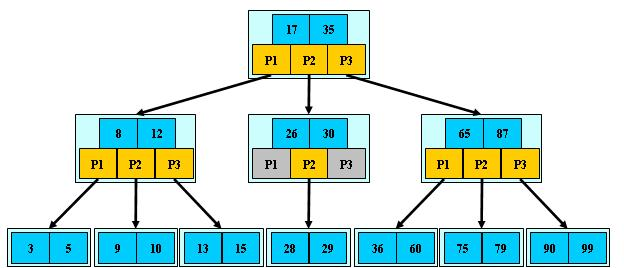
B+树
B+树是B树的一个变形,B+树的非叶子结点不存储数据,只作为索引。B+树的叶子结点内部,数据是有序排列的。
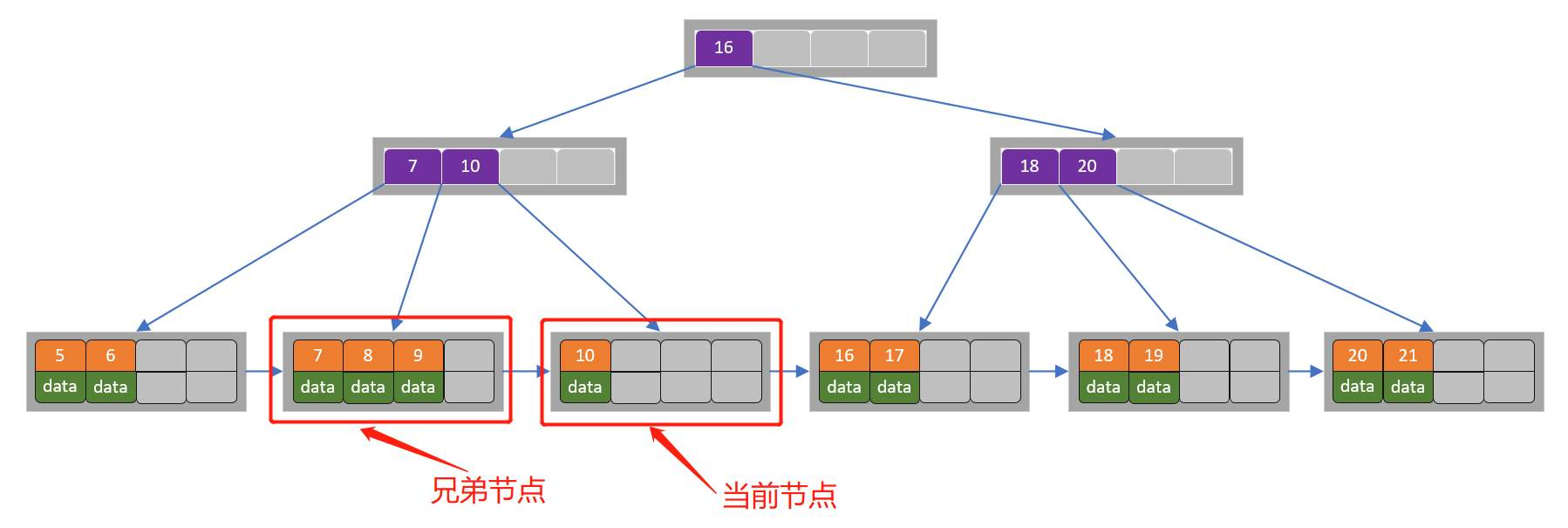
B+树的叶子结点兄弟之间有从左至右的指针,方便范围查询。
LSM
Log-Structured Merge-Tree,日志结构合并树,强调三点:一是这不是一个具体的数据结构只是一种做法,二是像写日志那样只追加,三是树会合并。
LSM为KV存储系统量身定做,只追加不修改不删除的特性很好地利用了机械硬盘顺序写入快、随机写入慢的特性。LSM首先是写内存,在内存中是一颗小树,内存要足够大,这比直接写磁盘也快了十万倍。内存写满了再落盘,追加到尾部,并且对大量的小文件做合并操作形成大树。为了将随机写转换为顺序写,LSM存储了大量的重复过时数据,这是空间换时间的做法。
上面这一点对于大量的写操作是非常高效的,但是读性能会略微受影响。读取数据的时候由于没有一颗完整有序的大树,所以要从最新的小树里查找数据,找不到的话就往前找。当然,这个缺陷可以使用布隆过滤器来优化。
我看了很多资料,都提到LSM是基于机械硬盘磁臂移动慢出现的,那么换成SSD还有这问题吗?老外对这个问题已经有研究了,看这里Separating Keys from Values in SSD-conscious Storage
当机械硬盘退出生产环境舞台的时候,LSM也许会迎来一波变革吧。
大数据学习(15)—— B+树和LSM的更多相关文章
- 大数据学习之BigData常用算法和数据结构
大数据学习之BigData常用算法和数据结构 1.Bloom Filter 由一个很长的二进制向量和一系列hash函数组成 优点:可以减少IO操作,省空间 缺点:不支持删除,有 ...
- 大数据学习(16)—— HBase环境搭建和基本操作
部署规划 HBase全称叫Hadoop Database,它的数据存储在HDFS上.我们的实验环境依然基于上个主题Hive的配置,参考大数据学习(11)-- Hive元数据服务模式搭建. 在此基础上, ...
- 大数据学习之 LINUX
##大数据学习 古斌6.6 01. linux系统的搭建: 选用 Contos 6.5 x64位系统 (CentOS-6.5-x86_64-minimal.iso) 我选择的为迷你版 模板机: bla ...
- 大数据学习day26----hive01----1hive的简介 2 hive的安装(hive的两种连接方式,后台启动,标准输出,错误输出)3. 数据库的基本操作 4. 建表(内部表和外部表的创建以及应用场景,数据导入,学生、分数sql练习)5.分区表 6加载数据的方式
1. hive的简介(具体见文档) Hive是分析处理结构化数据的工具 本质:将hive sql转化成MapReduce程序或者spark程序 Hive处理的数据一般存储在HDFS上,其分析数据底 ...
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
- 大数据学习系列之五 ----- Hive整合HBase图文详解
引言 在上一篇 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机) 和之前的大数据学习系列之二 ----- HBase环境搭建(单机) 中成功搭建了Hive和HBase的环 ...
- 大数据学习系列之六 ----- Hadoop+Spark环境搭建
引言 在上一篇中 大数据学习系列之五 ----- Hive整合HBase图文详解 : http://www.panchengming.com/2017/12/18/pancm62/ 中使用Hive整合 ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- 大数据学习系列之九---- Hive整合Spark和HBase以及相关测试
前言 在之前的大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 中介绍了集群的环境搭建,但是在使用hive进行数据查询的时候会非常的慢,因为h ...
- 大数据学习之Linux进阶02
大数据学习之Linux进阶 1-> 配置IP 1)修改配置文件 vi /sysconfig/network-scripts/ifcfg-eno16777736 2)注释掉dhcp #BOOTPR ...
随机推荐
- 如何编写shell脚本
1.首先创建一个目录 vi hello.sh 2.编写shell第一行 #!/bin/bash (为了声明是shell脚本,第一行都要这么写) 3.可以添加注释 #the first p ...
- 选择适合小企业的CRM软件
随着信息时代的到来和客户掌握的信息变多,大多数企业开始从"以产品为中心"转变为"以客户为中心".为了适应市场的变化,许多企业开始使用客户关系管理软件来提高工作效 ...
- vim编辑器使用方法(相关指令)
1.跳到文本的最后一行:按"G",即"shift+g" 2.跳到最后一行的最后一个字符 : 先重复1的操作即按"G",之后按"$& ...
- Python报错“UnicodeDecodeError: 'ascii' codec can't decode byte 0xe9 in position 0: ordinal not in range(128)”的解决办法
最近在用Python处理中文字符串时,报出了如下错误: UnicodeDecodeError: 'ascii' codec can't decode byte 0xe9 in position 0: ...
- 洛谷 P4402 BZOJ1552 / 3506 [Cerc2007]robotic sort 机械排序
FHQ_Treap 太神辣 蒟蒻初学FHQ_Treap,于是来到了这道略显板子的题目 因为Treap既满足BST的性质,又满足Heap的性质,所以,对于这道题目,我们可以将以往随机出的额外权值转化为每 ...
- Linux文件系统与日志分析
Linux文件系统与日志分析一.inode与block概述① 文件数据包括元信息(类似文件属性)与实际数据② 文件存储在硬盘上,硬盘最小存储单位是"扇区"(sector),每个扇区 ...
- IP数据包格式与ARP转发原理
一.网络层简介1.网络层功能2.网络层协议字段二.ICMP与封装三.ARP协议与ARP欺骗1.ARP协议2.ARP欺骗 1.网络层功能 1. 定义了基于IP地址的逻辑地址2. 连接不同的媒介3. 选择 ...
- C语言:猴子吃桃问题
//猴子吃桃问题:猴子第一天摘下若干个桃子,当即吃了一半,还不过瘾,又多吃了一个. //第二天早上又将第一天剩下的桃子吃掉一半,有多吃了一个.以后每天早上都吃了前一天剩下的一半零一个. //到第 10 ...
- .h .cpp区别
首先,我们可以将所有东西都放在一个.cpp文件内. 然后编译器就将这个.cpp编译成.obj,obj是什么东西? 就是编译单元了.一个程序,可以由一个编译单元组成, 也可以有多个编译单元组成. 如果你 ...
- Centos7下的rabbitmq-server-3.8.11安装配置
推荐大家看看这篇文章:https://blog.csdn.net/qq_27669839/article/details/113418827 下载安装文件 在网上去下载rabbmitmq-3.8.11 ...