Java:ConcurrentHashMap类小记-1(概述)
Java:ConcurrentHashMap类小记-1(概述)
对 Java 中的 ConcurrentHashMap类,做一个微不足道的小小小小记,分三篇博客:
概述
ConcurrentHashMap 是 Java 并发包中提供的一个线程安全且高效的 HashMap 实现,其在并发编程的场景中使用频率非常之高
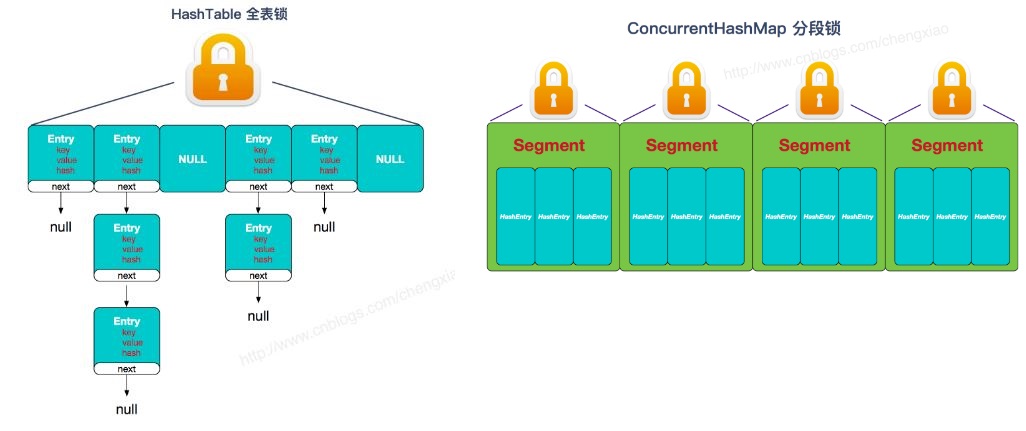
众所周知,哈希表是种非常高效,复杂度为 O(1) 的数据结构,在Java开发中,我们最常见到最频繁使用的就是 HashMap 和 HashTable,但是在线程竞争激烈的并发场景中使用都不够合理。
关于 HashMap 和 HashTable 的进一步了解,可见:Java:HashMap类小记,Java:HashTable类小记 这两篇博文
这里就先谈一下 HashMap 和 HashTable 与 ConcurrentHashMap 的区别所在:
HashMap 与 ConcurrentHashMap 区别:
后续指的是 JDK1.7 中的 ConcurrentHashMap
HashMap 不是线程安全的,而 ConcurrentHashMap 是线程安全的;
ConcurrentHashMap 采用锁分段技术,将整个 Hash 桶进行了分段 segment,也就是将这个大的数组分成了几个小的片段 segment,而且每个小的片段 segment 上面都有锁存在,那么在插入元素的时候就需要先找到应该插入到哪一个片段 segment,然后再在这个片段上面进行插入,虽然这里还需要获取 segment 锁,但这样做明显减小了锁的粒度。
HashTable 和 ConcurrentHashMap 的区别:
HashTable 和 ConcurrentHashMap 相比,效率低。 Hashtable 之所以效率低主要是使用了 synchronized 关键字对 put 等操作进行加锁,而 synchronized 关键字加锁是对整张 Hash 表的,即每次锁住整张表让线程独占,致使效率低下,而 ConcurrentHashMap 在对象中保存了一个 Segment 数组,即将整个 Hash 表划分为多个分段;而每个Segment 元素,即每个分段则类似于一个 Hashtable;这样,在执行 put 操作时首先根据 hash 算法定位到元素属于哪个 Segment,然后对该 Segment 加锁即可,因此, ConcurrentHashMap 在多线程并发编程中可是实现多线程 put操作。
总结:
ConcurrentHashMap 的出现也意味着 HashTable 的落幕,所以在以后的项目中,尽量少用 HashTable;
对于普通场景可以使用 HashMap 实现,如果是高并发场景建议使用 ConcurrentHashMap 实现
实现原理
这里仅进行一个简单的说明,后续对于 ConcurrentHashMap 在 JDK7 与 JDK8 中的实现会做进一步分析
JDK 7 中的 ConcurrentHashMap
JDK7 中 ConcurrentHashMap 采用了 数组 + Segment + 分段锁 的方式实现。
以下内容主要参考:https://www.cnblogs.com/chengxiao/p/6842045.html,稍微了解了一下
ConcurrentHashMap 采用了非常精妙的"分段锁"策略,ConcurrentHashMap 的主干是个 Segment 数组。
final Segment<K,V>[] segments;
Segment 继承了 ReentrantLock,所以它就是一种可重入锁(ReentrantLock)。在 ConcurrentHashMap,一个 Segment 就是一个子哈希表,Segment 里维护了一个 HashEntry 数组,并发环境下,对于不同 Segment 的数据进行操作是不用考虑锁竞争的。就按默认的 ConcurrentLevel 为 16 来讲,理论上就允许 16 个线程并发执行。
所以,对于同一个 Segment 的操作才需考虑线程同步,不同的 Segment 则无需考虑。Segment 类似于 HashMap,一个 Segment 维护着一个HashEntry 数组:
transient volatile HashEntry<K,V>[] table;
HashEntry 是目前我们提到的最小的逻辑处理单元了。一个 ConcurrentHashMap 维护一个 Segment 数组,一个 Segment 维护一个 HashEntry 数组。
因此,ConcurrentHashMap 定位一个元素的过程需要进行两次 Hash 操作。第一次 Hash 定位到 Segment,第二次 Hash 定位到元素所在的链表的头部。
JDK 8 中的 ConcurrentHashMap
JDK 8:中 ConcurrentHashMap 参考了 JDK 8 HashMap 的实现,采用了 数组 + 链表 + 红黑树 的实现方式来设计,内部大量采用 CAS 操作。
这里仅做一个总结,进一步分析见后续博文
JDK1.8 取消了 segment 数组,直接用 table 保存数据,锁的粒度更小,减少并发冲突的概率。
// 所有数据都存在table中, 只有当第一次插入时才会被加载,扩容时总是以2的倍数进行
transient volatile Node<K,V>[] table;
JDK1.8 存储数据时采用了链表+红黑树的形式,纯链表的形式时间复杂度为O(n),红黑树则为 O(logn),性能提升很大。
什么时候链表转红黑树?
- 当在一个桶中元素形成的链表中元素个数超过8个的时候;
- table的size大于64
JDK1.8 的实现降低锁的粒度,JDK1.7版本锁的粒度是基于Segment的,包含多个 HashEntry,而JDK1.8锁的粒度就是HashEntry(首节点)
JDK1.8 版本的数据结构变得更加简单,使得操作也更加清晰流畅,因为已经使用 synchronized 来进行同步,所以不需要分段锁的概念,也就不需要 Segment 这种数据结构了,由于粒度的降低,实现的复杂度也增加了
JDK1.8 使用红黑树来优化链表,基于长度很长的链表的遍历是一个很漫长的过程,而红黑树的遍历效率是很快的,代替一定阈值的链表,这样形成一个最佳拍档
JDK1.8 为什么使用内置锁synchronized来代替重入锁ReentrantLock,我觉得有以下几点
- 因为粒度降低了,在相对而言的低粒度加锁方式,synchronized并不比ReentrantLock差,在粗粒度加锁中ReentrantLock可能通过Condition来控制各个低粒度的边界,更加的灵活,而在低粒度中,Condition的优势就没有了
- JVM的开发团队从来都没有放弃synchronized,而且基于JVM的synchronized优化空间更大,使用内嵌的关键字比使用API更加自然
- 在大量的数据操作下,对于JVM的内存压力,基于API的ReentrantLock会开销更多的内存,虽然不是瓶颈,但是也是一个选择依据
Unsafe类
由于在ConcurrentHashMap中,为了避免进行加锁操作,使用了大量的CAS操作,而CAS操作在Java中是通过 Unsafe 类进行实现的,故在此先分析一波 Unsafe 类
概述
Unsafe类相当于是一个Java语言中的后门类,提供了硬件级别的原子操作,所以在一些并发编程中被大量使用。JDK 已经作出说明,该类对程序员而言不是一个安全操作,在后续的JDK升级过程中,可能会禁用该类。所以这个类的使用是一把双刃剑,实际项目中谨慎使用,以免造成JDK升级不兼容问题。
API
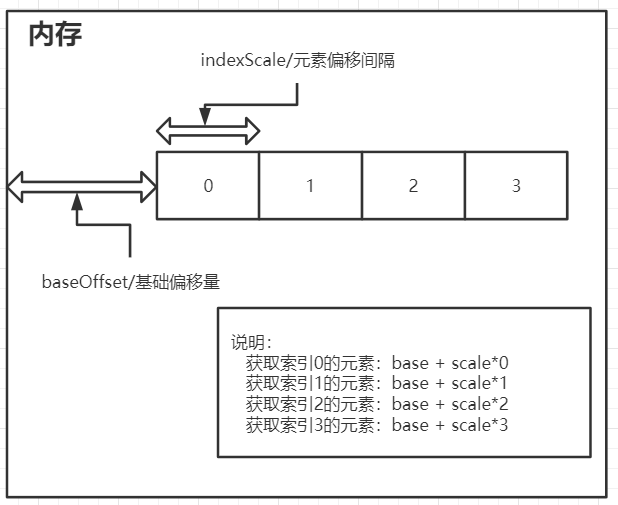
这个类是获取对象的偏移情况,而在ConcurrentHashMap中体现的就是数组对象,后续API中就以数组来进行说明
public native int arrayBaseOffset(Class<?> var1):获取数组的基础偏移量;public native int arrayIndexScale(Class<?> var1):获取数组中元素的偏移间隔,要获取对应所以的元素,将索引号和该值相乘,获得数组中指定角标元素的偏移量public native Object getObjectVolatile(Object var1, long var2):获取对象上的属性值或者数组中的元素public native Object getObject(Object var1, long var2):获取对象上的属性值或者数组中的元素,已过时public native void putOrderedObject(Object var1, long var2, Object var4):设置对象的属性值或者数组中某个角标的元素,更高效,但不保证线程间即时可见性public native void putObjectVolatile(Object var1, long var2, Object var4):设置对象的属性值或者数组中某个角标的元素,volatile 保证线程间及时可见性public native void putObject(Object var1, long var2, Object var4);:设置对象的属性值或者数组中某个角标的元素,已过时
代码演示
public class Demo {
public static void main(String[] args) throws Exception {
// 数组对象
Integer[] arr = {2,5,1,8,10};
// 暴力反射获取Unsafe对象
Unsafe unsafe = getUnsafe();
// 获取Integer[]的基础偏移量
int baseOffset = unsafe.arrayBaseOffset(Integer[].class);
// 获取Integer[]中元素的偏移间隔
int indexScale = unsafe.arrayIndexScale(Integer[].class);
// 获取数组中索引为2的元素对象:baseoffset + 2*indexScale
Object o = unsafe.getObjectVolatile(arr, (2 * indexScale) + baseOffset);
System.out.println(o); // 1
// 设置数组中索引为2的元素值为100
unsafe.putOrderedObject(arr,(2 * indexScale) + baseOffset,100);
System.out.println(Arrays.toString(arr)); // [2, 5, 100, 8, 10]
}
// 反射获取Unsafe对象
public static Unsafe getUnsafe() throws Exception {
// 获取Unsafe类无法直接通过Unsafe的内置函数getUnsafe来获取
Field theUnsafe = Unsafe.class.getDeclaredField("theUnsafe");
// 暴力反射
theUnsafe.setAccessible(true);
return (Unsafe) theUnsafe.get(null);
}
}
图解说明
参考
https://space.bilibili.com/488677881
☆ConcurrentHashMap实现原理及源码分析☆:https://www.cnblogs.com/chengxiao/p/6842045.html
☆关于jdk1.8中ConcurrentHashMap的方方面面☆:https://blog.csdn.net/tp7309/article/details/76532366
https://mp.weixin.qq.com/s/q1r9Pno6ANUzZ9wMzA-JSg
http://www.apgblogs.com/hashmap-hashtable-concurrenthashmap/
Java:ConcurrentHashMap类小记-1(概述)的更多相关文章
- Java:ConcurrentHashMap类小记-2(JDK7)
Java:ConcurrentHashMap类小记-2(JDK7) 对 Java 中的 ConcurrentHashMap类,做一个微不足道的小小小小记,分三篇博客: Java:ConcurrentH ...
- Java:ConcurrentHashMap类小记-3(JDK8)
Java:ConcurrentHashMap类小记-3(JDK8) 结构说明 // 所有数据都存在table中, 只有当第一次插入时才会被加载,扩容时总是以2的倍数进行 transient volat ...
- Java:AQS 小记-1(概述)
Java:AQS 小记-1(概述) 概述 全称是 Abstract Queued Synchronizer(抽象队列同步器),是阻塞式锁和相关的同步器工具的框架,这个类在 java.util.conc ...
- Java——IO类 字符流概述
body, table{font-family: 微软雅黑} table{border-collapse: collapse; border: solid gray; border-width: 2p ...
- Java:TreeMap类小记
Java:TreeMap类小记 对 Java 中的 TreeMap类,做一个微不足道的小小小小记 概述 前言:之前已经小小分析了一波 HashMap类.HashTable类.ConcurrentHas ...
- Java:HashMap类小记
Java:HashMap类小记 对 Java 中的 HashMap类,做一个微不足道的小小小小记 概述 HashMap:存储数据采用的哈希表结构,元素的存取顺序不能保证一致.由于要保证键的唯一.不重复 ...
- Java:HashTable类小记
Java:HashTable类小记 对 Java 中的 HashTable类,做一个微不足道的小小小小记 概述 public class Hashtable<K,V> extends Di ...
- Java:LinkedHashMap类小记
Java:LinkedHashMap类小记 对 Java 中的 LinkedHashMap类,做一个微不足道的小小小小记 概述 public class LinkedHashMap<K,V> ...
- Java:LinkedList类小记
Java:LinkedList类小记 对 Java 中的 LinkedList类,做一个微不足道的小小小小记 概述 java.util.LinkedList 集合数据存储的结构是循环双向链表结构.方便 ...
随机推荐
- docker&flask快速构建服务接口(二)
系列其他内容 docker快速创建轻量级的可移植的容器✓ docker&flask快速构建服务接口✓ docker&uwsgi高性能WSGI服务器生产部署必备 docker&g ...
- 【转载】linux 工作队列上睡眠的认识--不要在默认共享队列上睡眠
最近项目组做xen底层,我已经被完爆无数遍了,关键在于对内核.驱动这块不熟悉,导致分析xen代码非常吃力.于是准备细细的将 几本 linux 书籍慢慢啃啃. 正好看到LINUX内核设计与实现,对于内核 ...
- Python程序调用摄像头实现人脸识别
使用简单代码实现摄像头进行在线人脸识别 import cv2 import sys import logging as log import datetime as dt from time impo ...
- 超详细:command not found:scrapy解决办法(Mac下给zsh添加scrapy环境变量)
背景:本来打算用scrapy 创一个爬虫项目,但是无论如何都显示zsh: command not found: scrapy,看了很多篇blog才解决了问题,决定记录一下. 主要参考的blog: ht ...
- Docker系列(16)- 容器数据卷
什么是容器数据卷 docker的理念回顾 将应用和环境打包成一个镜像 数据?如果数据都在容器中,那么我们容器删除,数据就会丢失!新增一个需求:数据可以持久化 MySQL,容器删了等于删库跑路!新增一个 ...
- P7597 「EZEC-8」猜树 加强版
#include<bits/stdc++.h>using namespace std;#define rg register#define inf 0x3f3f3f3f#define ll ...
- 手把手教你 Docker搭建nacos单机版
Docker搭建nacos单机版步骤 一.使用 docker pull nacos/nacos-server 拉取nacos镜像 我这里没有指定版本所以是拉取latest,你也可以使用 docker ...
- T183637-变异距离(2021 CoE III C)【单调栈】
正题 题目链接:https://www.luogu.com.cn/problem/T183637 题目大意 给出\(n\)个二元组\((x_i,y_i)\),求最大的 \[|x_i-x_j|\time ...
- SpringMVC的数据输出
使用 @Controller public class OutputController { @RequestMapping("/handle01") public String ...
- FTP和TFTP
文件传输协议 FTP概述: 文件传输协议FTP(File Transfer Protocol)[RFC 959]是互联网上使用最广泛的文件传输协议, FTP提供交互式的访问,允许用户知指明文件类型与格 ...