【Python3爬虫】使用异步协程编写爬虫
一、基本概念
进程:进程是一个具有独立功能的程序关于某个数据集合的一次运行活动。进程是操作系统动态执行的基本单元。
线程:一个进程中包含若干线程,当然至少有一个线程,线程可以利用进程所拥有的资源。线程是独立运行和独立调度的基本单元。
协程:协程是一种用户态的轻量级线程。协程无需线程上下文切换的开销,也无需原子操作锁定及同步的开销。
同步:不同程序单元为了完成某个任务,在执行过程中需靠某种通信方式以协调一致,称这些程序单元是同步执行的。
异步:为完成某个任务,不同程序单元之间过程中无需通信协调,也能完成任务的方式,不相关的程序单元之间可以是异步的。
多进程:多进程就是利用 CPU 的多核优势,在同一时间并行地执行多个任务。多进程模式优点就是稳定性高,因为一个子进程崩溃了,不会影响主进程和其他子进程,但是操作系统能同时运行的进程数是有限的。
多线程:多线程模式通常比多进程快一点,但是也快不到哪去,而且,多线程模式致命的缺点就是任何一个线程挂掉都可能直接造成整个进程崩溃,因为所有线程共享进程的内存。
二、异步协程
Python 中使用协程最常用的库莫过于 asyncio,然后我们还需要了解一些概念:
event_loop:事件循环,相当于一个无限循环,我们可以把一些函数注册到这个事件循环上,当满足条件发生的时候,就会调用对应的处理方法。
coroutine:协程对象类型,我们可以将协程对象注册到事件循环中,它会被事件循环调用。我们可以使用 async 关键字来定义一个方法,这个方法在调用时不会立即被执行,而是返回一个协程对象。
task:任务,它是对协程对象的进一步封装,包含了任务的各个状态,比如 running、finished 等。
另外我们还需要了解两个关键字:async(定义一个协程),await(用来挂起阻塞方法的执行)。下面是一个示例:
import asyncio async def show(num):
print("Number is {}".format(num)) cor = show(1)
print("Coroutine: ", cor)
print("After execute...")
task = asyncio.ensure_future(cor)
print("Task: ", task)
loop = asyncio.get_event_loop()
loop.run_until_complete(cor)
print("Task: ", task)
print("After loop...")
运行结果如下:
Coroutine: <coroutine object show at 0x0000000012ED91A8>
After execute...
Task: <Task pending coro=<show() running at E:/Python/1.py:4>>
Number is 1
Task: <Task finished coro=<show() done, defined at E:/Python/1.py:4> result=None>
After loop...
这里首先使用async定义了一个show方法,传入一个数字然后打印出来,我们调用了这个方法,但是这个方法并没有执行,而是返回了一个Coroutine协程对象。然后我们使用了asyncio的ensure_future()方法,该方法会返回一个task对象,此时task的状态是pending。然后我们使用 get_event_loop() 方法创建了一个事件循环 loop,并调用了run_until_complete() 方法将协程注册到事件循环loop中,然后启动。最后我们才看到了show() 方法打印了输出结果,此时task的状态已经是finished了。
再来看一个例子:
import time
import asyncio async def show(num):
print("Number is {}".format(num))
await asyncio.sleep(1) # 必须加await实现协程 这里asyncio.sleep(1)是一个子协程
# time.sleep(1) # time.sleep()不能与await搭配使用 start = time.time()
tasks = [asyncio.ensure_future(show(i)) for i in [1, 2, 3, 4, 5]] loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks))
end = time.time()
print("Cost time: ", end - start)
这里我们有多个任务组成了一个列表tasks,然后我们将tasks添加到事件循环中,等到执行完毕了打印出所花费的时间。当我们使用await asyncio.sleep(1)的时候,结果如下:
Number is 1
Number is 2
Number is 3
Number is 4
Number is 5
Cost time: 1.0040574073791504
使用time,sleep(1)的时候结果如下:
Number is 1
Number is 2
Number is 3
Number is 4
Number is 5
Cost time: 5.001286029815674
结果很明显了,前者所花费的时间更少,原因在于await会将asyncio.sleep(1)这个协程暂时挂起阻塞,第一个任务(show(1))运行到这里的时候就会挂起,然后执行下一个任务(show(2)),以此类推,等到所有的任务都执行完毕,再执行asyncio.sleep(1),所以最后花费的时间就是一秒多一点了。
三、编写爬虫
1、aiohttp
要利用协程来写网络爬虫,还需要使用一个第三方库--aiohttp,aiohttp是一个支持异步请求的库,利用它和 asyncio配合我们可以非常方便地实现异步请求操作。没有安装的可以使用pip install aiohttp进行安装,其官方文档的链接是:https://aiohttp.readthedocs.io/en/stable/,需要注意的是aiohttp支持的python版本是3.5.3+,如果运行出错的话建议先检查下你的python版本。先来看看官网上给出的例子吧:
import aiohttp
import asyncio async def fetch(session, url):
async with session.get(url) as response:
return await response.text() async def main():
async with aiohttp.ClientSession() as session:
html = await fetch(session, 'http://python.org')
print(html) loop = asyncio.get_event_loop()
loop.run_until_complete(main())
首先是导入我们需要的模块,然后定义了一个fetch方法,传入的参数是一个session和一个url,然后使用session的get()方法去请求这个链接,并返回结果。在main方法中,首先引用了aiohttp里的ClientSession类,建立 了一个session对象,然后将这个session和一个链接传入到fetch方法中,最后将fetch方法返回的结果打印出来。
2、具体步骤
这次写的爬虫实现了对崔庆才的个人博客上的文章基本信息的爬取,包括标题、链接、浏览的数目、评论的数目以及喜欢的人数,最后分别将浏览数、评论数以及喜欢数排前十的文章统计出来并绘制出图表。
首先进入崔庆才个人博客,可以看到一页有二十篇文章,把页面下拉,就会出现更多的文章,显然这是动态加载的,于是我们打开开发者工具,继续下拉页面,然后在XHR选项中看到了我们需要的内容:

不停地下拉页面,会发现最后数字会定格在35,也就是说总共有35页,每页的链接都形如https://cuiqingcai.com/page/2,这样的话我们爬取的话就简单多了。基本思路是将所有链接组成一个列表,然后利用aiohttp去请求网页并返回结果,然后我们再对结果进行解析,对于解析得到的结果,保存在MongoDB数据库中。然后再对数据进行一下简单的分析,并绘制图表,结果如下:

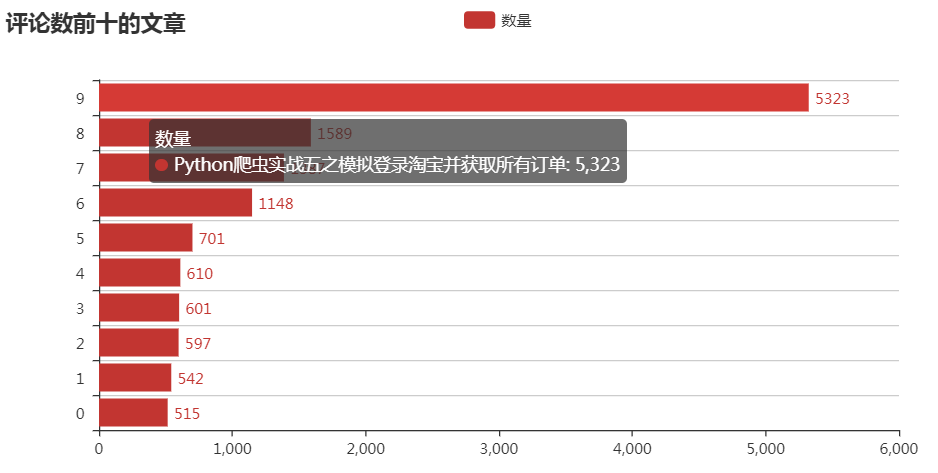
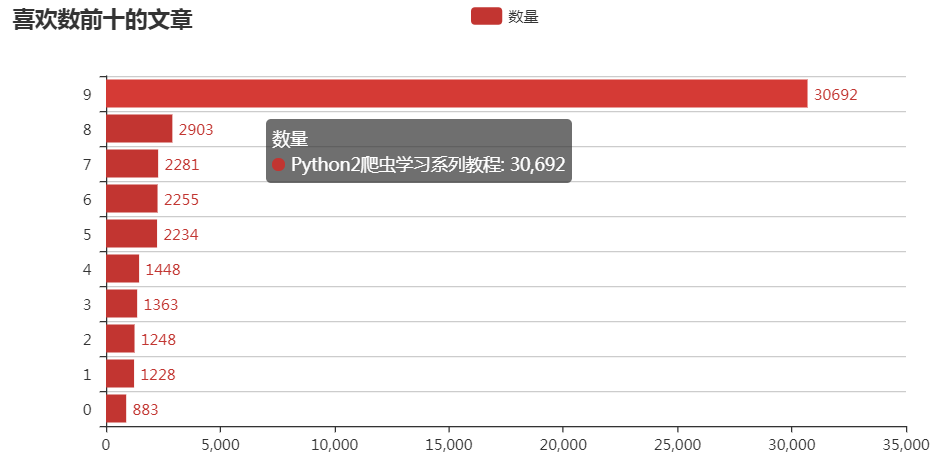
完整代码已上传到GitHub!
【Python3爬虫】使用异步协程编写爬虫的更多相关文章
- python爬虫---单线程+多任务的异步协程,selenium爬虫模块的使用
python爬虫---单线程+多任务的异步协程,selenium爬虫模块的使用 一丶单线程+多任务的异步协程 特殊函数 # 如果一个函数的定义被async修饰后,则该函数就是一个特殊的函数 async ...
- Python爬虫进阶 | 异步协程
一.背景 之前爬虫使用的是requests+多线程/多进程,后来随着前几天的深入了解,才发现,对于爬虫来说,真正的瓶颈并不是CPU的处理速度,而是对于网页抓取时候的往返时间,因为如果采用request ...
- python爬虫--多任务异步协程, 快点,在快点......
多任务异步协程asyncio 特殊函数: - 就是async关键字修饰的一个函数的定义 - 特殊之处: - 特殊函数被调用后会返回一个协程对象 - 特殊函数调用后内部的程序语句没有被立即执行 - 协程 ...
- 小爬爬4.协程基本用法&&多任务异步协程爬虫示例(大数据量)
1.测试学习 (2)单线程: from time import sleep import time def request(url): print('正在请求:',url) sleep() print ...
- 爬虫必知必会(4)_异步协程-selenium_模拟登陆
一.单线程+多任务异步协程(推荐) 协程:对象.可以把协程当做是一个特殊的函数.如果一个函数的定义被async关键字所修饰.该特殊的函数被调用后函数内部的程序语句不会被立即执行,而是会返回一个协程对象 ...
- 协程实现爬虫的例子主要优势在于充分利用IO时间去请求其他的url
# 分别使用urlopen和requests两个模块进行演示 # import requests # 需要安装的 # from urllib.request import urlopen # # ur ...
- 异步协程asyncio+aiohttp
aiohttp中文文档 1. 前言 在执行一些 IO 密集型任务的时候,程序常常会因为等待 IO 而阻塞.比如在网络爬虫中,如果我们使用 requests 库来进行请求的话,如果网站响应速度过慢,程序 ...
- asyncio模块实现单线程-多任务的异步协程
本篇介绍基于asyncio模块,实现单线程-多任务的异步协程 基本概念 协程函数 协程函数: 定义形式为 async def 的函数; aysnc 在Python3.5+版本新增了aysnc和awai ...
- Python中异步协程的使用方法介绍
1. 前言 在执行一些 IO 密集型任务的时候,程序常常会因为等待 IO 而阻塞.比如在网络爬虫中,如果我们使用 requests 库来进行请求的话,如果网站响应速度过慢,程序一直在等待网站响应,最后 ...
随机推荐
- 用Axure进行原型设计
用Axure进行原型设计 看这个视频 http://www.iqiyi.com/playlist409963402.html
- 斜率优化入门学习+总结 Apio2011特别行动队&Apio2014序列分割&HZOI2008玩具装箱&ZJOI2007仓库建设&小P的牧场&防御准备&Sdoi2016征途
斜率优化: 额...这是篇7个题的题解... 首先说说斜率优化是个啥,额... f[i]=min(f[j]+xxxx(i,j)) ; 1<=j<i (O(n^2)暴力)这样一个式子,首 ...
- JSON 数据重复 出现$ref
JSONArray 类型 如果我们往里面add数据的时候 如果数据相同,那么就会被替换成 $ref: 也就是被简化了 因为数据一样所直接 指向上一条数据 循环引用:当一个对象包含另一个对象时, ...
- 【源码安装】Heartbeat3.0.9
1.概述1.1 关于Heartbeat1.2 本篇博客实践环境2. 部署基础环境2.1 通过YUM安装依赖环境2.2 创建Heartbeat用户和组3. 编译安装3.1下载源码包3.2 编译安装3.2 ...
- 【毕业】-《伯恩茅斯大学毕业证书》BU一模一样原件
☞伯恩茅斯大学毕业证书[微/Q:2544033233◆WeChat:CC6669834]UC毕业证书/联系人Alice[查看点击百度快照查看][留信网学历认证&博士&硕士&海归 ...
- Java Applet 与Servlet之间的通信
1 Applet对Servlet的访问及参数传递的实现 2.1.1创建URL对象 在JAVA程序中,可以利用如下的形式创建URL对象 URL servletURL = new URL( "h ...
- Ubuntu 18 安装chrome
1.下载chrome文件 32位使用如下命令 wget https://dl.google.com/linux/direct/google-chrome-stable_current_i386.deb ...
- 基于SDRAM的视频图像采集系统
本文是在前面设计好的简易SDRAM控制器的基础上完善,逐步实现使用SDRAM存储视频流数据,实现视频图像采集系统,CMOS使用的是OV7725. SDRAM控制器的完善 1. 修改SDRAM的时钟到1 ...
- SpringBoot进阶教程(三十)整合Redis之Sentinel哨兵模式
Redis-Sentinel是官方推荐的高可用解决方案,当redis在做master-slave的高可用方案时,假如master宕机了,redis本身(以及其很多客户端)都没有实现自动进行主备切换,而 ...
- 一线互联网企业常见的14个Java面试题,Java面试题集大全等你拿,颤抖吧程序员!
本文由尚学堂学员们根据自己参加过的面试回忆.总结而成,一线互联网企业常见的14个Java面试题,包括各大互联网企业.创业小公司,互联网企业.传统软件公司.对于刚毕业和想要跳槽的宝宝们,再适用不过啦,赶 ...