第一课:Hadoop集群环境搭建
一、 检查列表
1.1、网络访问
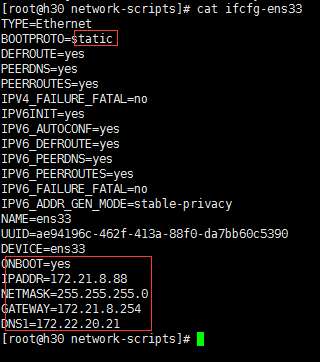
设置电脑IP以及可以访问网络设置:进入etc/sysconfig/network-scripts/,使用命令“ls -all” 查看文件。会看到ifcfg-lo文件然后使用命令修改IP和DNS.
1.2、防火墙
关闭防火墙,我是用的系统是CentOS7,命令如何下:
查看防火墙状态的命令:systemctl status firewalld
关闭防火墙的命令:systemctl stop firewalld
关闭防火墙开机启动:systemctl disable firewalld

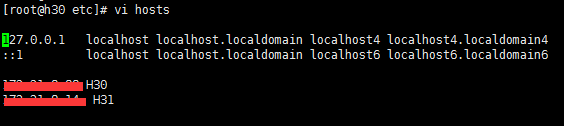
1.3、Hosts
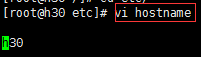
1.3.1 修改hostname,进入etc,然后使用修改命令进行修改
1.3.1 修改host
二、搭建远程连接
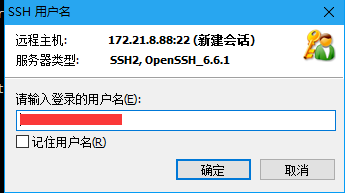
下载xshell和xftp 软件(下载地址:http://www.netsarang.com/download/main.html)

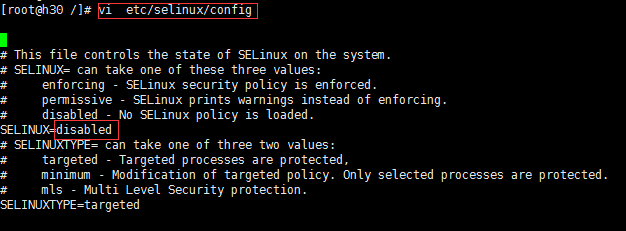
三、修改SELinux
四、安装JDK
4.1 检查java安装情况
检查包命令: rpm -qa|grep java
4.2 新建文件夹
cd /var
mkdir -p www/html
4.3 使用Xftp 4将下载好的jdk上传到H30,也可以点Xshell的xftp链接(http://www.oracle.com/technetwork/java/javase/downloads/index.html)
4.4 安装
cd /var/www/html
rpm -ivh jdk-7u67-linux-x64.rpm
4.5查看版本
java -version
五、SSH 设置
5.1 创建SSH文件夹
进入H30,查看ssh是否安装,如果有,继续,没有安装下。
rpm -qa|grep ssh
创建.ssh目录。查看文件中,第一个字母d表示是目录,后面跟着的是权限,比如创建者,一般的人,大家有兴趣查下Linux的文件权限。
#进入root目录
cd /root
#创建.ssh目录
mkdir .ssh
#设置权限
chmod .ssh
#检查
ls -al
5.2 创建SSH
后面3个回车
ssh-keygen -t rsa
5.3 复制id_rsa.pub 到authorized_keys
cd .ssh
cat id_rsa.pub >> authorized_keys
5.4 修改H31(集群其他服务器一样)配置
cd .ssh ls -al #设置权限
chmod authorized_keys ls -al
5.5 复制authorized_keys到H31
#copy
scp /root/.ssh/authorized_keys root@H31:/root/.ssh/
#login
ssh root@H31
第一课:Hadoop集群环境搭建的更多相关文章
- hadoop集群环境搭建准备工作
一定要注意hadoop和linux系统的位数一定要相同,就是说如果hadoop是32位的,linux系统也一定要安装32位的. 准备工作: 1 首先在VMware中建立6台虚拟机(配置默认即可).这是 ...
- hadoop集群环境搭建之zookeeper集群的安装部署
关于hadoop集群搭建有一些准备工作要做,具体请参照hadoop集群环境搭建准备工作 (我成功的按照这个步骤部署成功了,经实际验证,该方法可行) 一.安装zookeeper 1 将zookeeper ...
- hadoop集群环境搭建之安装配置hadoop集群
在安装hadoop集群之前,需要先进行zookeeper的安装,请参照hadoop集群环境搭建之zookeeper集群的安装部署 1 将hadoop安装包解压到 /itcast/ (如果没有这个目录 ...
- Hadoop集群环境搭建步骤说明
Hadoop集群环境搭建是很多学习hadoop学习者或者是使用者都必然要面对的一个问题,网上关于hadoop集群环境搭建的博文教程也蛮多的.对于玩hadoop的高手来说肯定没有什么问题,甚至可以说事“ ...
- 大数据 -- Hadoop集群环境搭建
首先我们来认识一下HDFS, HDFS(Hadoop Distributed File System )Hadoop分布式文件系统.它其实是将一个大文件分成若干块保存在不同服务器的多个节点中.通过联网 ...
- Spark集群环境搭建——Hadoop集群环境搭建
Spark其实是Hadoop生态圈的一部分,需要用到Hadoop的HDFS.YARN等组件. 为了方便我们的使用,Spark官方已经为我们将Hadoop与scala组件集成到spark里的安装包,解压 ...
- 简单Hadoop集群环境搭建
最近大数据课程需要我们熟悉分布式环境,每组分配了四台服务器,正好熟悉一下hadoop相关的操作. 注:以下带有(master)字样为只需在master机器进行,(ALL)则表示需要在所有master和 ...
- Hadoop集群环境搭建(一)
1集群简介 HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起 HDFS集群: 负责海量数据的存储,集群中的角色主要有 NameNode / DataN ...
- Java+大数据开发——Hadoop集群环境搭建(一)
1集群简介 HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起 HDFS集群: 负责海量数据的存储,集群中的角色主要有 NameNode / DataN ...
- Hadoop(4)-Hadoop集群环境搭建
准备工作 开启全部三台虚拟机,确保hadoop100的机器已经配置完成 分发脚本 操作hadoop100 新建一个xsync的脚本文件,将下面的脚本复制进去 vim xsync #这个脚本使用的是rs ...
随机推荐
- 关于会话、进程、请求的几个常用SQL
1.检查自己的SID SELECT sid FROM v$session WHERE sid = (SELECT sid FROM v$mystat WHERE rownum = 1); 2. 几个I ...
- H5学习之旅-H5的样式(5)
样式的引入方式 外部样式表 link rel = "stylesheet" type = "text/css" href = "mystyle.css ...
- C语言所有作业练习题
2015.08.11 1.计算十进制 42 转换为二进制.八进制.十六进制分别对应的值 2.计算二进制 11010110 对应的十进制值 3.计算八进制 075 对应的十进制值 4.计算十六进制 0x ...
- Mahout系列之----kmeans 聚类
Kmeans是最经典的聚类算法之一,它的优美简单.快速高效被广泛使用. Kmeans算法描述 输入:簇的数目k:包含n个对象的数据集D. 输出:k个簇的集合. 方法: 从D中任意选择k个对象作为初始簇 ...
- Leetcode_34_Search for a Range
本文是在学习中的总结,欢迎转载但请注明出处:http://blog.csdn.net/pistolove/article/details/44021767 Given a sorted array o ...
- SpriteBuilder中如何平均拉伸精灵帧动画的距离
首先要在Timeline中选中所有的精灵帧,可以通过如下2种的任意一种办法达成: 1按下Shift键的同时鼠标单击它们 2鼠标在Timeline空白区拖拽直到拉出的矩形包围住所有精灵帧方块后放开鼠标. ...
- android Titlebar一行代码实现沉浸式效果
github地址 一个简单易用的导航栏TitleBar,可以轻松实现IOS导航栏的各种效果 整个代码全部集中在TitleBar.java中,所有控件都动态生成,动态布局.不需要引用任何资源文件,拷贝 ...
- Android中处理大图片时图片压缩
1.BitmapFactory.Options中的属性 在进行图片压缩时,是通过设置BitmapFactory.Options的一些值来改变图片的属性的,下面我们来看看BitmapFactory.Op ...
- kettle控件 add a checksum
This step calculates checksums for one or more fields in the input stream and adds this to the outpu ...
- Treemap 有序的hashmap。用于排序
TreeMap:有固定顺序的hashmap.在需要排序的Map时候才用TreeMap. Map.在数组中我们是通过数组下标来对其内容索引的,键值对. HashMap HashMap 用哈希码快速定位一 ...