R语言-时间序列
时间序列:可以用来预测未来的参数,
1.生成时间序列对象
sales <- c(18, 33, 41, 7, 34, 35, 24, 25, 24, 21, 25, 20,
22, 31, 40, 29, 25, 21, 22, 54, 31, 25, 26, 35)
# 1.生成时序对象
tsales <- ts(sales,start = c(2003,1),frequency = 12)
plot(tsales)
# 2.获得对象信息
start(tsales)
end(tsales)
frequency(tsales)
# 3.对相同取子集
tsales.subset <- window(tsales,start=c(2003,5),end=c(2004,6))
tsales.subset
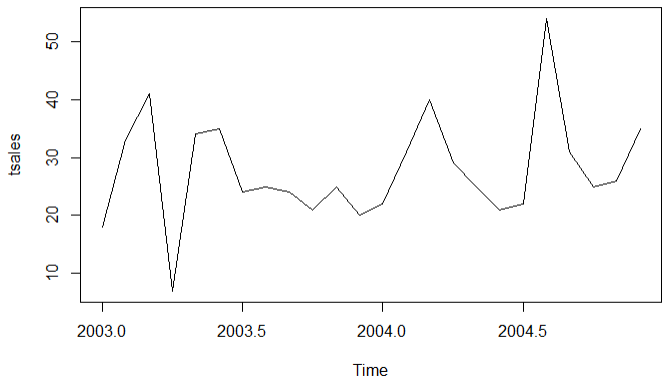
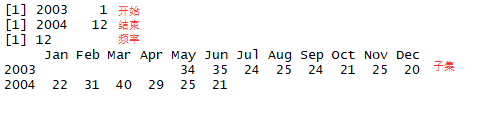
结论:手动生成的时序图
2.简单移动平均
案例:尼罗河流量和年份的关系
library(forecast)
opar <- par(no.readonly = T)
par(mfrow=c(2,2))
ylim <- c(min(Nile),max(Nile))
plot(Nile,main='Raw time series')
plot(ma(Nile,3),main = 'Simple Moving Averages (k=3)',ylim = ylim)
plot(ma(Nile,7),main = 'Simple Moving Averages (k=3)',ylim = ylim)
plot(ma(Nile,15),main = 'Simple Moving Averages (k=3)',ylim = ylim)
par(opar)
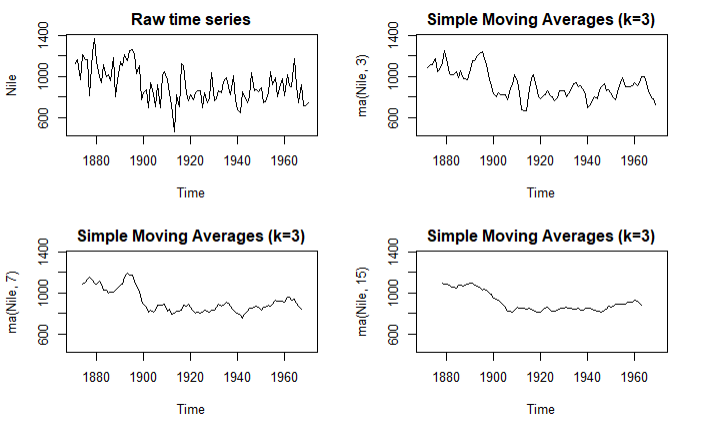
结论:随着K值的增大,图像越来越平滑我们需要找到最能反映规律的K值
3.使用stl做季节性分解
案例:Arirpassengers年份和乘客的关系
# 1.画出时间序列
plot(AirPassengers)
lAirpassengers <- log(AirPassengers)
plot(lAirpassengers,ylab = 'log(Airpassengers)')
# 2.分解时间序列
fit <- stl(lAirpassengers,s.window = 'period')
plot(fit)
fit$time.series
par(mfrow=c(2,1))
# 3.月度图可视化
monthplot(AirPassengers,xlab='',ylab='')
# 4.季度图可视化
seasonplot(AirPassengers,year.labels = T,main = '')
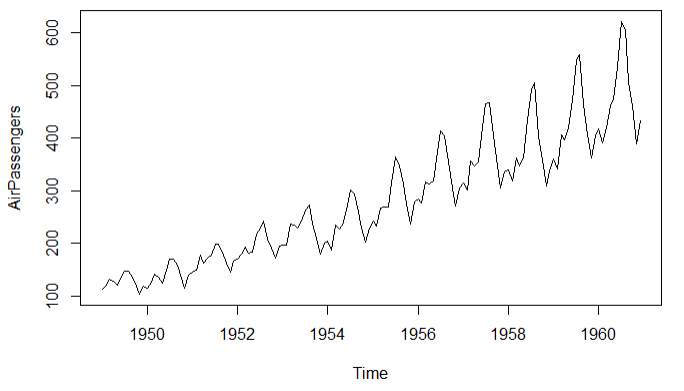
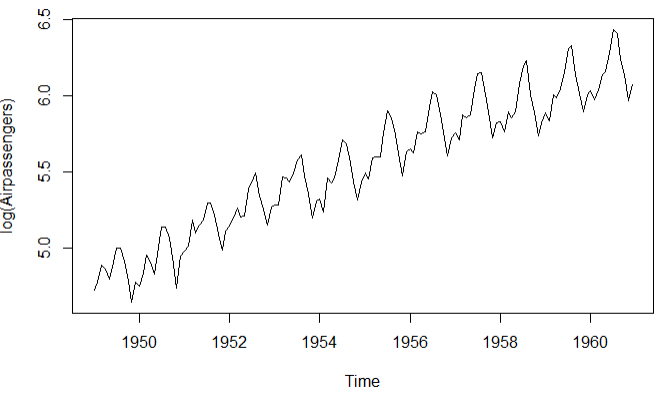
原始图 对数变换
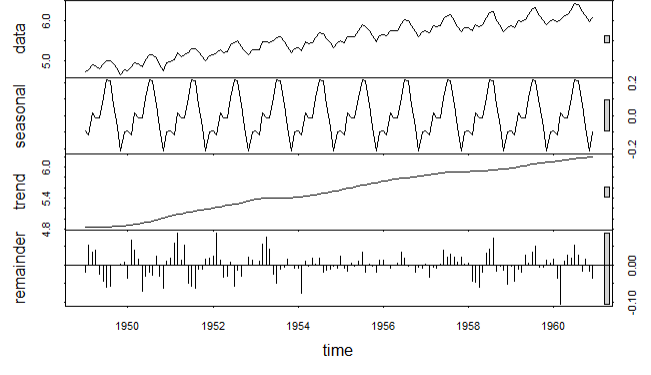

总体趋势图 月度季度图
4.指数预测模型
4.1单指数平滑
案例:预测康涅狄格州的气温变化
# 1.拟合模型
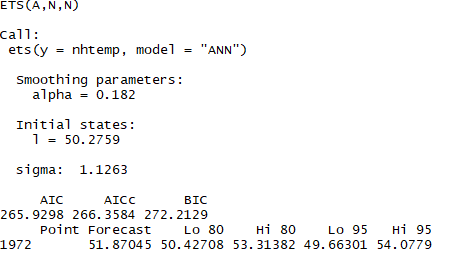
fit2 <- ets(nhtemp,model = 'ANN')
fit2
# 2.向前预测
forecast(fit2,1)
plot(forecast(fit2,1),xlab = 'Year',
ylab = expression(paste("Temperature (",degree*F,")",)),
main="New Haven Annual Mean Temperature")
# 3.得到准确的度量
accuracy(fit2)
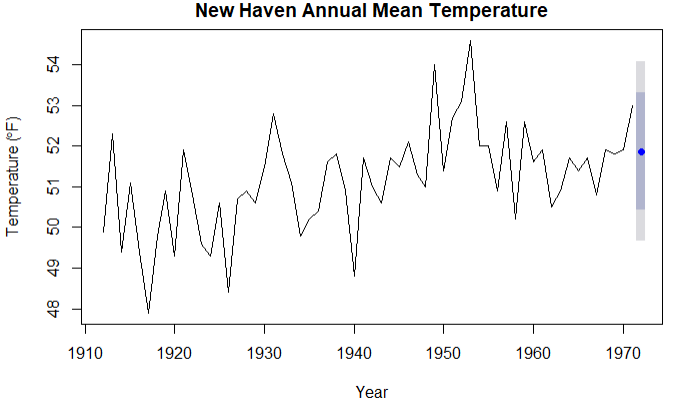
结论:浅灰色是80%的置信区间,深灰色是95%的置信区间
4.2有水平项,斜率和季节项的指数模型
案例:预测5个月的乘客流量
# 1.光滑参数
fit3 <- ets(log(AirPassengers),model = 'AAA')
accuracy(fit3)
# 2.未来值预测
pred <- forecast(fit3,5)
pred
plot(pred,main='Forecast for air Travel',ylab = 'Log(Airpassengers)',xlab = 'Time')
# 3.使用原始尺度预测
pred$mean <- exp(pred$mean)
pred$lower <- exp(pred$lower)
pred$upper <- exp(pred$upper)
p <- cbind(pred$mean,pred$lower,pred$upper)
dimnames(p)[[2]] <- c('mean','Lo 80','Lo 95','Hi 80','Hi 95')
p
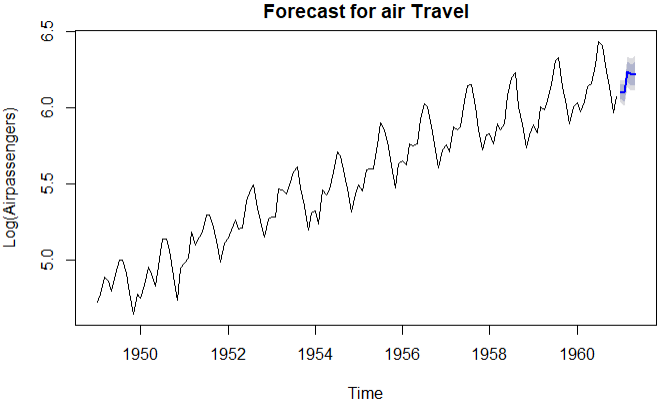

结论:从表格中可知3月份的将会有509200乘客,95%的置信区间是[454900,570000]
4.3ets自动预测
案例:自动预测JohnsonJohnson股票的趋势
fit4 <- ets(JohnsonJohnson)
fit4
plot(forecast(fit4),main='Johnson and Johnson Forecasts',
ylab="Quarterly Earnings (Dollars)", xlab="Time")
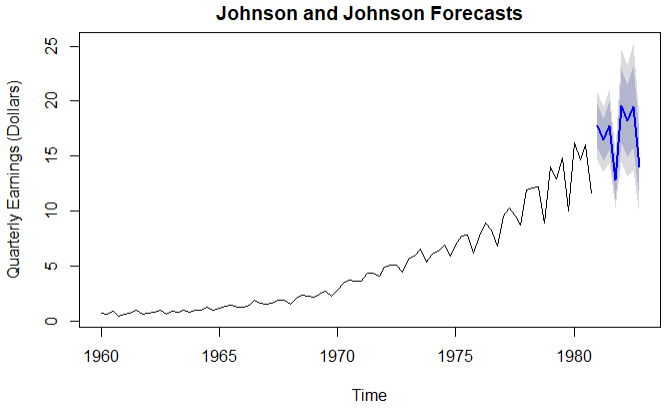
结论:预测值使用蓝色线表示,浅灰色表示80%置信空间,深灰色表示95%置信空间
5.ARIMA预测
步骤:
1.确保时序是平稳的
2.找出合理的模型(选定可能的p值或者q值)
3.拟合模型
4.从统计假设和预测准确性等角度评估模型
5.预测
library(tseries)
plot(Nile)
# 1.原始序列差分一次
ndiffs(Nile) dNile <- diff(Nile)
# 2.差分后的图形
plot(dNile)
adf.test(dNile)
Acf(dNile)
Pacf(dNile)
# 3.拟合模型
fit5 <- arima(Nile,order = c(0,1,1))
fit5
accuracy(fit5)
# 4.评价模型
qqnorm(fit5$residuals)
qqline(fit5$residuals)
Box.test(fit5$residuals,type = 'Ljung-Box')
# 5.预测模型
forecast(fit5,3)
plot(forecast(fit5,3),xlab = 'Year',ylab = 'Annual Flow')

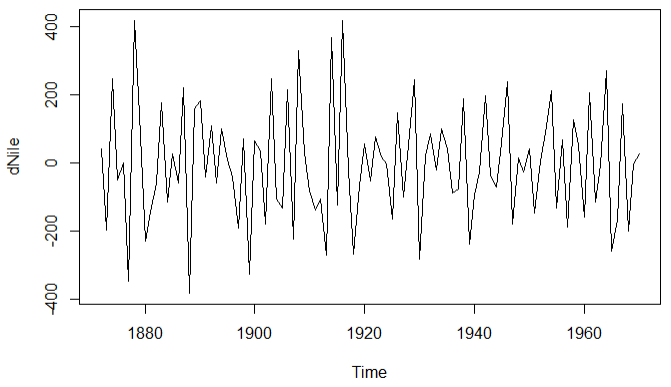
原始图 一次差分图形
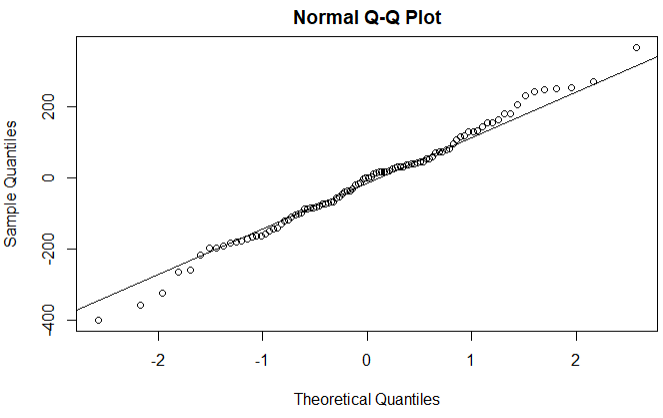
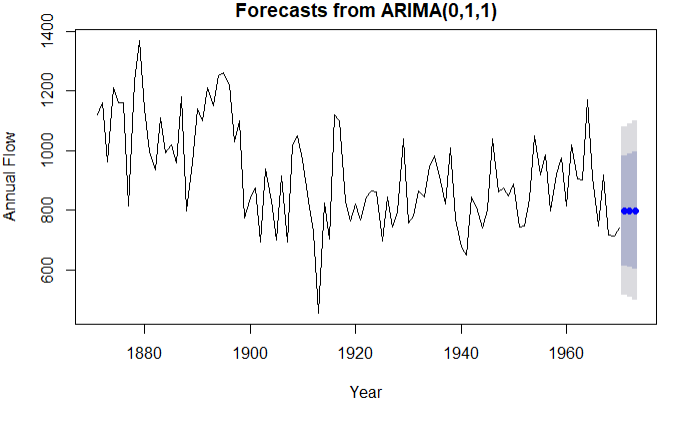
正态Q-Q图(如果满足正态分布,点会落在图中的线上) 使用Arima(0,1,1)模型的预测值
Arima自动预测
案例:预测3个月之后的太阳黑子
fit6 <- auto.arima(sunspots)
fit6
forecast(fit6,3)
accuracy(fit6)
plot(forecast(fit6,3), xlab = "Year",
ylab = "Monthly sunspot numbers")
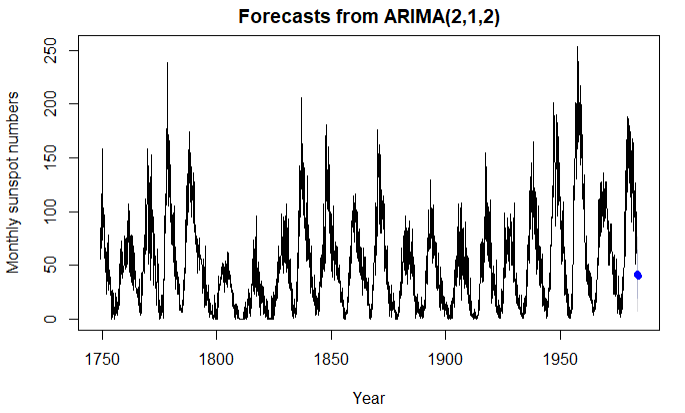
结论:函数自动选定(2,1,2)与其他模型相比,AIC的值最小,预测结果更准确
R语言-时间序列的更多相关文章
- R语言-时间序列图
1.时间序列图 plot()函数 > air<-read.csv("openair.csv") > plot(air$nox~as.Date(air$date,& ...
- 基于R语言的时间序列指数模型
时间序列: (或称动态数列)是指将同一统计指标的数值按其发生的时间先后顺序排列而成的数列.时间序列分析的主要目的是根据已有的历史数据对未来进行预测.(百度百科) 主要考虑的因素: 1.长期趋势(Lon ...
- Rserve详解,R语言客户端RSclient【转】
R语言服务器程序 Rserve详解 http://blog.fens.me/r-rserve-server/ Rserve的R语言客户端RSclient https://blog.csdn.net/u ...
- 【R语言学习】时间序列
时序分析会用到的函数 函数 程序包 用途 ts() stats 生成时序对象 plot() graphics 画出时间序列的折线图 start() stats 返回时间序列的开始时间 end() st ...
- 用R语言的quantreg包进行分位数回归
什么是分位数回归 分位数回归(Quantile Regression)是计量经济学的研究前沿方向之一,它利用解释变量的多个分位数(例如四分位.十分位.百分位等)来得到被解释变量的条件分布的相应的分位数 ...
- R语言学习笔记-机器学习1-3章
在折腾完爬虫还有一些感兴趣的内容后,我最近在看用R语言进行简单机器学习的知识,主要参考了<机器学习-实用案例解析>这本书. 这本书是目前市面少有的,纯粹以R语言为基础讲解的机器学习知识,书 ...
- R入门<三>-R语言实战第4章基本数据管理摘要
入门书籍:R语言实战 进度:1-4章 摘要: 1)实用的包 forecast:用于做时间序列预测的,有auto.arima函数 RODBC:可以用来读取excel文件.但据说R对csv格式适应更加良好 ...
- R语言实战(三)基本图形与基本统计分析
本文对应<R语言实战>第6章:基本图形:第7章:基本统计分析 =============================================================== ...
- 机器学习:异常检测算法Seasonal Hybrid ESD及R语言实现
Twritters的异常检测算法(Anomaly Detection)做的比较好,Seasonal Hybrid ESD算法是先用STL把序列分解,考察残差项.假定这一项符合正态分布,然后就可以用Ge ...
随机推荐
- (纯代码)快速创建wcf rest 服务
因为有一个小工具需要和其它的业务对接数据,所以就试一下看能不能弄一个无需配置快速对接的方法出来,百(以)度(讹)过(传)后(讹),最后还是对照wcf配置对象调试出来了: 1.创建WebHttpBind ...
- centos 如何关闭防火墙?
1 查看防火墙状态: 命令: /etc/init.d/iptables status 如果是开着显示内容类是截图 2 临时关闭防火墙: 命令:/etc/init.d/iptables stop ...
- Java并发系列[2]----AbstractQueuedSynchronizer源码分析之独占模式
在上一篇<Java并发系列[1]----AbstractQueuedSynchronizer源码分析之概要分析>中我们介绍了AbstractQueuedSynchronizer基本的一些概 ...
- echo 0000
一个奇怪的问题,正常状态下如果sql插入失败,则输出0000,代码如下: $stmt=$db->prepare("insert into message(user,title,cont ...
- MySQL相关文档索引
MySQL的新功能5.7 https://dev.mysql.com/doc/refman/5.7/en/mysql-nutshell.html MySQL5.7安装 http://note.youd ...
- 你可能不知道的.Net Core Configuration
目录 执行原理 环境变量 Spring Cloud Config Server 挂卷Volume Config Server vs Volume 执行原理 1. 配置读取顺序:与代码先后顺序一致. p ...
- Node.js调用C#代码
在Node.js的项目中假如我们想去调用已经用C#写的dll库该怎么办呢?在这种情况下Edge.js是一个不错的选择,Edge.js是一款在GitHub上开源的技术,它允许Node.js和.NET c ...
- Python CRM项目六
自定义Django Admin的action 在Django Admin中,可以通过action来自定义一些操作,其中默认的action的功能是选中多条数据来进行删除操作 我们在king_admin中 ...
- arm 异常处理结构
概念:正常的程序执行过程中发生暂时的停止称为异常,如果发现异常情况,将会进行异常处理 作用:快速响应用户的行为,提高cpu的响应能力 异常类型: 异常处理的三个步骤: 1.保护现场: 工作模式保存:C ...
- javascript 利用FileReader和滤镜上传图片预览
FileReader 对象允许Web应用程序异步读取存储在用户计算机上的文件(或原始数据缓冲区)的内容,使用 File或 Blob对象指定要读取的文件或数据. 1.FileReader接口的方法 Fi ...