我眼中的Adaboost
步骤:
def buildStump(dataArr,classLabels,D):
1。循环取出数据集中的一个特征(一列)输入 (for:)
2。循环调整阀值threshVal (for:)
3,。分成两个子树
左边:特征值xi<=threshVal 为-1,否则为1
获得预测结果1
右边:特征值xi>threshVal 为-1,否则为-1
获得预测结果2
4。分别把预测结果同真实标签比较,获得一个向量(对的为零,错误为1)
5。和权重向量D相乘,获得一个值(权重错误值,用来计算alpha),评判分类器的好坏。
5。获得最低的错误率结果保存起来
返回:单层决策树(弱分类器),最小错误,预测的标签
循环结束后,每一个特征都对应一个阀值,而这个阀值,可以最大准确度地分割特征
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------
以上的过程就实现一个分类器,接下来通过训练,来获取一定数量较好的弱分类器
def buildStump(dataArr,classLabels,D):
1。 初始化权重D(它与上述过程中的权重D是同一个,它的作用是增加错误分类的权重,降低正确分类的权重)
2。 迭代过程(for:迭代次数)
3。 buildStump(dataArr,classLabels,D):(调用上面的过程,创建一个弱分类器)
4。 计算alpha(Adaboost为每一个弱分类器都分配一个权重alpha,这些alpha值都是基于每一个弱分类器的错误率进行计算)
5。 保存alpha到决策树集合(弱分类器)中,同时也保存这个分类器
6。 更新权重向量D
7。 和真实的标签相比计算错误分类的个数
8。 计算错误率
9。 直到错误率为零则退出循环
返回:弱分类器的集合
这个过程结束,就获得一个弱分类器的集合,整体来说分类的效果越来越好
---------------------------------------------------------------------------------------------------------------------------------------------------------
调用训练好的模型进行分类
传入要分类的数据datToClass,传入弱分类器集合classifierArr(也就是训练好的模型)
def adaClassify(datToClass,classifierArr):
(for:弱分类器的个数)
1。使用弱分类器i预测结果标签labeli
2。乘以它的这个弱分类器的权重alpha
3。累加每一个弱分类器的这个结果(其实就是一个投票过程)
4。获得结果
用一个图表示就是这样的
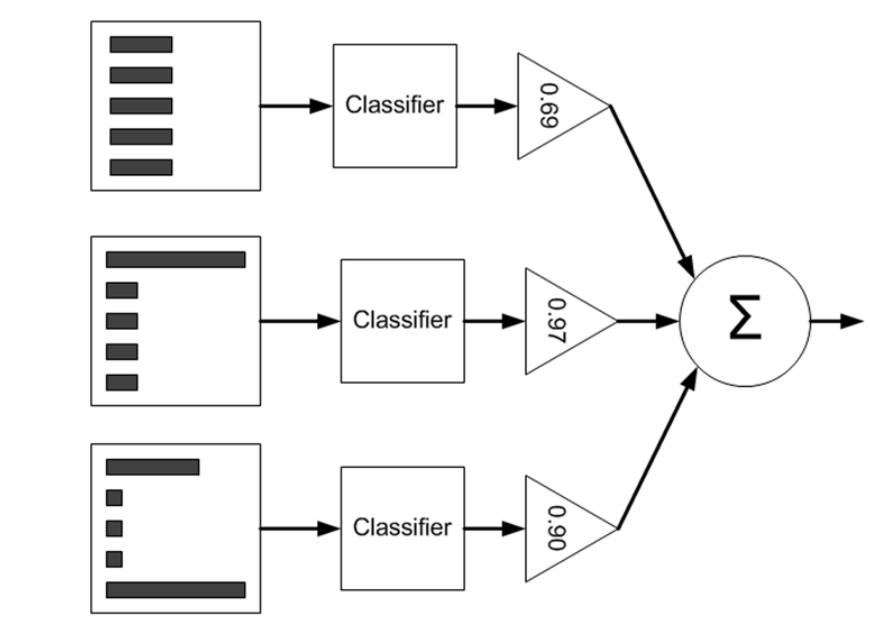
为了更好的了解分类器的性能,我们通过画出ROC曲线,来更好的了解。
什么是ROC :https://www.cnblogs.com/zhxuxu/p/9911660.html
接下来是机器学习实战中的代码(详细注释),代码和上面的流程搭配看,希望对你有帮助。
#coding=utf-8
from numpy import * def loadSimpData():
datMat = matrix([[1.0,2.1],
[ 2. , 1.1],
[ 1.3, 1. ],
[ 1. , 1. ],
[ 2. , 1. ]])
classLabels = [1.0, 1.0, -1.0, -1.0, 1.0]
return datMat,classLabels def loadDataSet(fileName):
numFeat = len(open(fileName).readline().split('\t'))
dataMat = [];labelMat = []
fr = open(fileName)
for line in fr.readlines():
lineArr = []
curLine = line.strip().split('\t')
for i in range(numFeat - 1):
lineArr.append(float(curLine[i]))
dataMat.append(lineArr)
labelMat.append(float(curLine[-1]))
return dataMat,labelMat def stumpClassify(dataMatrix,dimen,threshVal,threshIneg):
#初始化数据类别都为+1
#分左右子树
#与阀值比较,左子树小于阀值为-1,大于阀值为1。右侧大于阀值为-1,小于阀值为1。
#这两种分法,最后取错误率最低的分法
retArray = ones((shape(dataMatrix)[0],1))
if threshIneg =='lt':
retArray[dataMatrix[:,dimen] <= threshVal] = -1.0
else:
retArray[dataMatrix[:,dimen] > threshVal] = -1.0
return retArray def buildStump(dataArr,classLabels,D):
dataMatrix = mat(dataArr); labelMat = mat(classLabels).T
m,n = shape(dataMatrix)
numSteps = 10.0; bestStump = {}; bestClasEst = mat(zeros((m,1)))
minError = inf
#循环取样本的第i个特征
for i in range(n):
#求出每一列的最大最小值
rangeMin = dataMatrix[:,i].min(); rangeMax = dataMatrix[:,i].max();
#步长
stepSize = (rangeMax-rangeMin)/numSteps
#这一个循环用来调整阀值
for j in range(-1,int(numSteps)+1):
for inequal in ['lt', 'gt']:
#计算阀值
threshVal = (rangeMin + float(j) * stepSize)
#计算预测标签
predictedVals = stumpClassify(dataMatrix,i,threshVal,inequal)
#错误矩阵,用来记录预测错误的样本
errArr = mat(ones((m,1)))
#实际标签与预测标签相等的为0
errArr[predictedVals == labelMat] = 0
#权重向量D乘错误矩阵,预测正确的权重为零,权重就无需更改
weightedError = D.T*errArr
#与最小错误比较
#print ("split: dim %d, thresh %.2f, thresh ineqal: %s, the weighted error is %.3f" % (i, threshVal, inequal, weightedError))
if weightedError < minError:
#更新最小错误
minError = weightedError
bestClasEst = predictedVals.copy()
bestStump['dim'] = i
bestStump['thresh'] = threshVal
bestStump['ineq'] = inequal print ("bestsplit: dim %d, thresh %.2f, thresh ineqal: %s, the weighted error is %.3f" % (bestStump['dim'], bestStump['thresh'], bestStump['ineq'], minError))
#返回的是bestStump中保存的单层决策树(就是选择出了两类中能使错误率降到最低的特征)
#最小错误率,最好的类别预测
return bestStump,minError,bestClasEst def adaBoostTrainDS(dataArr,classLabels,numIt=40):
weakClassArr = []
m = shape(dataArr)[0]
#D是一个概率分布向量,其和要等于1,因此要除以m
#权重的初始化可以是一样的随着迭代次数增加
#增加错误分类的权重,降低错误分类的权重
D = mat(ones((m,1))/m)
aggClassEst = mat(zeros((m,1)))
for i in range(numIt):
#创建一个弱学习器(树根)
bestStump,error,classEst = buildStump(dataArr,classLabels,D)
print ("D:",D.T)
#Adaboost为每一个弱分类器都分配一个权重alpha
#这些alpha值都是基于每一个弱分类器的错误率进行计算
#计算公式alpha = 1/2ln(1-c/c)
#c是错误率c=错误分类的样本个数/所有样本总数
#为了防止分母为零,增加1e-16
alpha = float(0.5*log((1.0-error)/max(error,1e-16)))
#存到树根中
bestStump['alpha'] = alpha
weakClassArr.append(bestStump)
print ("classEst: ",classEst.T)
#更新权重向量D
#正确分类的expon为负(权重影响小)
#错误分类的expon为正(权重影响大)
#这里正确标签和预测样本标签相乘,标签一样为正,不一样为负
expon = multiply(-1*alpha*mat(classLabels).T,classEst)
D = multiply(D,exp(expon))
D = D/D.sum() aggClassEst += alpha*classEst
#sign if a>0 return 1,if a<0 return -1,if a==0 return 0
#计算错误分类的个数
aggErrors = multiply(sign(aggClassEst) != mat(classLabels).T,ones((m,1)))
#错误率
errorRate = aggErrors.sum()/m
print ("total error: ",errorRate)
if errorRate == 0.0: break
#返回每一次迭代获得的最好结果的分类器
#弱分类器参数集合,和每一个弱分类器对应的alpha(权重)
return weakClassArr,aggClassEst def adaClassify(datToClass,classifierArr):
dataMatrix = mat(datToClass)
m = shape(dataMatrix)[0]
aggClassEst = mat(zeros((m,1)))
#classifierArr是最优分类器的集合
for i in range(len(classifierArr)):
#调用训练好的分类器参数
classEst = stumpClassify(dataMatrix, classifierArr[i]['dim'],\
classifierArr[i]['thresh'],\
classifierArr[i]['ineq'])
#这些分类器使用投票的方式,获得最终的预测结果
aggClassEst += classifierArr[i]['alpha']*classEst
print (aggClassEst)
return sign(aggClassEst) #ROC曲线的绘制及AUC计算函数
def plotROC(predStrengths, classLabels):
import matplotlib.pyplot as plt
cur = (1.0,1.0)
#AUC的值
ySum = 0.0
#计算分类为正的个数
numPosClas = sum(array(classLabels)==1.0)
yStep = 1/float(numPosClas); xStep = 1/float(len(classLabels)-numPosClas)
#predStrengths是投票预测结果(非整数),argsort()从大到小排序,返回下标
#也就是预测结果接近于1(分类为正)的排在前面
sortedIndicies = predStrengths.argsort()
#print('predStrengths',predStrengths)
#print('classLabels',classLabels)
fig = plt.figure()
fig.clf()
ax = plt.subplot(111)
#classLabels是真实结果,通过比较,为正类,移动y轴,否则移动x轴
for index in sortedIndicies.tolist()[0]:
if classLabels[index] == 1.0:
delX = 0; delY = yStep;
else:
delX = xStep; delY = 0;
ySum += cur[1]
ax.plot([cur[0],cur[0]-delX],[cur[1],cur[1]-delY], c='b')
cur = (cur[0]-delX,cur[1]-delY)
ax.plot([0,1],[0,1],'b--')
plt.xlabel('False positive rate'); plt.ylabel('True positive rate')
plt.title('ROC curve for AdaBoost horse colic detection system')
ax.axis([0,1,0,1])
plt.show() def test():
datMat,classLabels = loadSimpData()
#D = mat(ones((5,1))/5)
#buildStump(datMat,classLabels,D)
#以上就构成了一个弱分类器
#接下来训练出多个弱分类器,构成Adaboost算法
classifierArray = adaBoostTrainDS(datMat,classLabels,numIt=9)
print(classifierArray)
#接下来进行测试 #实例对马疝病数据集分类使用Adaboost
def app():
datArr,labelArr = loadDataSet('horseColicTraining2.txt')
classifierArray = adaBoostTrainDS(datArr,labelArr,10) testArr,testLabelArr = loadDataSet('horseColicTest2.txt')
prediction10 = adaClassify(testArr,classifierArray)
errArr = mat(ones((67,1)))
errArr[prediction10!=mat(testLabelArr).T].sum()
#画ROC曲线图
def plotROCtest():
datArr,labelArr = loadDataSet('horseColicTraining2.txt')
classifierArray,aggClassEst = adaBoostTrainDS(datArr,labelArr,10)
plotROC(aggClassEst.T, labelArr)
测试代码时,可以分别运行
def test()
def app()
def plotROCtest() 实现具体的功能
我眼中的Adaboost的更多相关文章
- boosting、adaboost
1.boosting Boosting方法是一种用来提高弱分类算法准确度的方法,这种方法通过构造一个预测函数系列,然后以一定的方式将他们组合成一个预测函数.他是一种框架算法,主要是通过对样本集的操作获 ...
- Adaboost提升算法从原理到实践
1.基本思想: 综合某些专家的判断,往往要比一个专家单独的判断要好.在"强可学习"和"弱科学习"的概念上来说就是我们通过对多个弱可学习的算法进行"组合 ...
- scikit-learn Adaboost类库使用小结
在集成学习之Adaboost算法原理小结中,我们对Adaboost的算法原理做了一个总结.这里我们就从实用的角度对scikit-learn中Adaboost类库的使用做一个小结,重点对调参的注意事项做 ...
- 集成学习之Adaboost算法原理小结
在集成学习原理小结中,我们讲到了集成学习按照个体学习器之间是否存在依赖关系可以分为两类,第一个是个体学习器之间存在强依赖关系,另一类是个体学习器之间不存在强依赖关系.前者的代表算法就是是boostin ...
- 【十大经典数据挖掘算法】AdaBoost
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 1. 集成学习 集成学习(ensem ...
- 机器学习——AdaBoost元算法
当做重要决定时,我们可能会考虑吸取多个专家而不只是一个人的意见.机器学习处理问题也是这样,这就是元算法(meta-algorithm)背后的思路. 元算法是对其他算法进行组合的一种方式,其中最流行的一 ...
- Adaboost\GBDT\GBRT\组合算法
Adaboost\GBDT\GBRT\组合算法(龙心尘老师上课笔记) 一.Bagging (并行bootstrap)& Boosting(串行) 随机森林实际上是bagging的思路,而GBD ...
- 程序员眼中的 SQL Server-执行计划教会我如何创建索引?
先说点废话 以前有 DBA 在身边的时候,从来不曾考虑过数据库性能的问题,但是,当一个应用程序从头到脚都由自己完成,而且数据库面对的是接近百万的数据,看着一个页面加载速度像乌龟一样,自己心里真是有种挫 ...
- AdaBoost算法分析与实现
AdaBoost(自适应boosting,adaptive boosting)算法 算法优缺点: 优点:泛化错误率低,易编码,可用在绝大部分分类器上,无参数调整 缺点:对离群点敏感 适用数据类型:数值 ...
随机推荐
- Web后端 JAVA实现验证码生成与验证功能
首先,写一个验证码生成帮助类,用来绘制随机字母: <span style="font-size:14px;">import java.awt.Color; impor ...
- CSS重要知识概述——Java Web从入门到精通第2章
一.CSS简单规则 CSS样式表包含3部分内容:选择符.属性和属性值 其中选择符包括基本的3种选择器: 1.标记选择器,如<a></a>标签等: 2.类别选择器,用class属 ...
- 47.Odoo产品分析 (五) – 定制板块(2) – 为业务自定义odoo(2)
查看Odoo产品分析系列--目录 Odoo产品分析 (五) – 定制板块(2) – 为业务自定义odoo(1) 4 添加自定义字段 定制odoo的最普通的原因就是指定到公司的附加信息.如果您正在运行一 ...
- (办公)mybatis工作中常见的问题(不定时更新)
1.mybatis的like查询的方式. <if test="shopName != null and shopName != ''"> <bind name=& ...
- 【English】十三、英语中的连词有哪些,都有什么作用
一.什么是连词 参考:https://m.hujiang.com/en_cixing/yylc/ 连词是一种虚词,用于连接单词.短语.从句或句子,在句子中不单独用作句子成分. 连词按其性质可分为并列连 ...
- Java三大特性
Java 三大特性,算是Java独特的表现,提到Java 的三大特性, 我们都会想到封装, 继承和多态 这是我们Java 最重要的特性. 封装(Encapsulation) : 封装:是指隐藏对象的属 ...
- 'Attempt to create two animations for cell' iOS
我是在对一个UITableView 一起进行 reloadRows和reloadSections 的操作的时候 出现的
- 使用git提交代码到github,每次都要输入用户名和密码的解决方法
自从使用git提交代码到github后,发现自己使用git的功力增长了不少,但也遇到不少问题.比如,使用git提交代码到github的时候,经常要求输入用户名和密码,类似这种: 网上有这么一种解决方法 ...
- linux 软链接的创建、删除和更新
大家都知道,有的时候,我们为了省下空间,都会使用链接的方式来进行引用操作.同样的,在系统级别也有.在Windows系列中,我们称其为快捷方式,在Linux中我们称其为链接(基本上都差不多了,其中可能有 ...
- [题解] P2513 [HAOI2009]逆序对数列
动态规划,卡常数 题目地址 设\(F[X][Y]\)代表长度为\(X\)的序列,存在\(Y\)组逆序对的方案数量. 考虑\(F[X][i]\)向\(F[X+1][i]\)转移: 把数字\(X+1\)添 ...