Redis的常见用法
Redis
redis是一个key-value存储系统。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
1.操作方式
import redis r = redis.Redis(host='10.211.55.4', port=6379)
r.set('foo', 'Bar')
print r.get('foo')
2.连接池
redis-py使用connection pool来管理对一个redis server的所有连接,避免每次建立、释放连接的开销。默认,每个Redis实例都会维护一个自己的连接池。可以直接建立一个连接池,然后作为参数Redis,这样就可以实现多个Redis实例共享一个连接池
import redis pool = redis.ConnectionPool(host='127.0.0.1', port=6379,decode_response=true, max_connections=10)
# decode_response获取字符串格式的数据
# max_connections同时连接redis的最大连接数,超过最大连接数时会等待
r = redis.Redis(connection_pool=pool)
r.set('foo', 'Bar')
print r.get('foo')
3.操作
String操作,redis中的String在在内存中按照一个name对应一个value来存储

set(name, value, ex=None, px=None, nx=False, xx=False)
在Redis中设置值,默认,不存在则创建,存在则修改
参数:
ex,过期时间(秒)
px,过期时间(毫秒)
nx,如果设置为True,则只有name不存在时,当前set操作才执行
xx,如果设置为True,则只有name存在时,岗前set操作才执行
setnx(name, value)
设置值,只有name不存在时,执行设置操作(添加)
mset(*args, **kwargs)
批量设置值
如:
mset({'k1': 'v1', 'k2': 'v2'})
批量获取值
mget('k1', 'k2')
get(name)
获取值
getset(name, value)
设置新值并获取原来的值
Hash操作,redis中Hash在内存中的存储格式如下图:
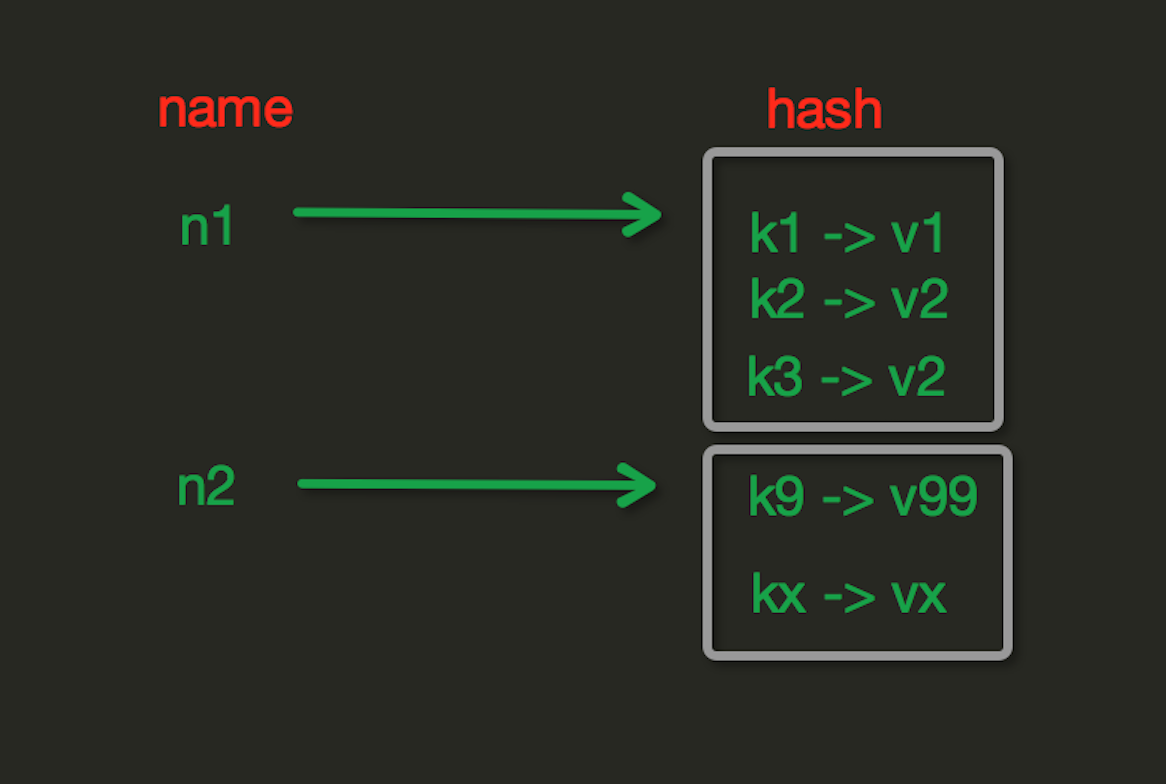
hset(name, key, value)
# name对应的hash中设置一个键值对(不存在,则创建;否则,修改) # 参数:
# name,redis的name
# key,name对应的hash中的key
# value,name对应的hash中的value # 注:
# hsetnx(name, key, value),当name对应的hash中不存在当前key时则创建(相当于添加)
hmset(name, mapping)
# 在name对应的hash中批量设置键值对 # 参数:
# name,redis的name
# mapping,字典,如:{'k1':'v1', 'k2': 'v2'} # 如:
# r.hmset('xx', {'k1':'v1', 'k2': 'v2'})
hget(name,key)
# 在name对应的hash中获取根据key获取value
hmget(name, keys, *args)
# 在name对应的hash中获取多个key的值 # 参数:
# name,reids对应的name
# keys,要获取key集合,如:['k1', 'k2', 'k3']
# *args,要获取的key,如:k1,k2,k3 # 如:
# r.mget('xx', ['k1', 'k2'])
# 或
# print r.hmget('xx', 'k1', 'k2')
hgetall(name)
# 获取name对应hash的所有键值
hexists(name, key)
# 检查name对应的hash是否存在当前传入的key
hdel(name,*keys)
# 将name对应的hash中指定key的键值对删除
hscan(name, cursor=0, match=None, count=None)
# 增量式迭代获取,对于数据大的数据非常有用,hscan可以实现分片的获取数据,并非一次性将数据全部获取完,从而放置内存被撑爆 # 参数:
# name,redis的name
# cursor,游标(基于游标分批取获取数据)
# match,匹配指定key,默认None 表示所有的key
# count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数 # 如:
# 第一次:cursor1, data1 = r.hscan('xx', cursor=0, match=None, count=None)
# 第二次:cursor2, data1 = r.hscan('xx', cursor=cursor1, match=None, count=None)
# ...
# 直到返回值cursor的值为0时,表示数据已经通过分片获取完毕
hscan_iter(name, match=None, count=None)
# 利用yield封装hscan创建生成器,实现分批去redis中获取数据 # 参数:
# match,匹配指定key,默认None 表示所有的key
# count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数 # 如:
# for item in r.hscan_iter('xx'):
# print it
Redis的常见用法的更多相关文章
- Linux中find常见用法
Linux中find常见用法示例 ·find path -option [ -print ] [ -exec -ok command ] {} \; find命令的参数 ...
- php中的curl使用入门教程和常见用法实例
摘要: [目录] php中的curl使用入门教程和常见用法实例 一.curl的优势 二.curl的简单使用步骤 三.错误处理 四.获取curl请求的具体信息 五.使用curl发送post请求 六.文件 ...
- Guava中Predicate的常见用法
Guava中Predicate的常见用法 1. Predicate基本用法 guava提供了许多利用Functions和Predicates来操作Collections的工具,一般在 Iterabl ...
- find常见用法
Linux中find常见用法示例 ·find path -option [ -print ] [ -exec -ok command ] {} \; find命令的参数 ...
- iOS 开发多线程篇—GCD的常见用法
iOS开发多线程篇—GCD的常见用法 一.延迟执行 1.介绍 iOS常见的延时执行有2种方式 (1)调用NSObject的方法 [self performSelector:@selector(run) ...
- iOS开发多线程篇—GCD的常见用法
iOS开发多线程篇—GCD的常见用法 一.延迟执行 1.介绍 iOS常见的延时执行有2种方式 (1)调用NSObject的方法 [self performSelector:@selector(run) ...
- [转]EasyUI——常见用法总结
原文链接: EasyUI——常见用法总结 1. 使用 data-options 来初始化属性. data-options是jQuery Easyui 最近两个版本才加上的一个特殊属性.通过这个属性,我 ...
- NSString常见用法总结
//====================NSStirng 的常见用法==================== -(void)testString { //创建格式化字符串:占位符(由一个%加一个字 ...
- [转]Linux中find常见用法示例
Linux中find常见用法示例[转]·find path -option [ -print ] [ -exec -ok command ] {} \;find命令的参 ...
随机推荐
- Oracle AWRDD报告生成和性能分析
我写的SQL调优专栏:https://blog.csdn.net/u014427391/article/category/8679315 对于局部的,比如某个页面列表sql,我们可以使用Oracle的 ...
- 【Caffe篇】--Caffe从入门到初始及各层介绍
一.前述 Caffe,全称Convolutional Architecture for Fast Feature Embedding.是一种常用的深度学习框架,主要应用在视频.图像处理方面的应用上.c ...
- 深入浅出一下Java的HashMap
在平常的开发当中,HashMap是我最常用的Map类(没有之一),它支持null键和null值,是绝大部分利用键值对存取场景的首选.需要切记的一点是——HashMap不是线程安全的数据结构,所以不要在 ...
- qml demo分析(photosurface-图片涅拉)
阅读qml示例代码已有一小段时间,也陆续的写了一些自己关于qml示例代码的理解,可能由于自己没有大量的qml开发经验,总感觉复杂的ui交互qml处理起来可能会比较棘手,但事实总是会出人意料,今天我们就 ...
- 带着新人简单看看servlet到springmvc
好久都没有写博客了,不是因为自己懒了,而是总感觉自己知道的只是太少了,每次想写博客的时候都不知道怎么下手,不过最近看到一篇博客说的是springmvc,给了我比较大的兴趣,感觉一下子对整个spring ...
- LindDotNetCore~Ocelot实现微服务网关
回到目录 网关在硬件里有自己的定义,而在软件架构里也有自己的解释,它就是所有请求的入口,请求打到网关上,经过处理和加工,再返回给客户端,这个处理过程中当然就是网关的核心,也是Ocelot的核心,我们可 ...
- .NetCore WebAPI采坑之路(持续更新)
1.WebAPI新增日志过滤器or中间件后Action读取到的请求Body为空问题 案例: 自定义了一个中间件,用于记录每次访问webapi的入参,以及引用了Swagger. 先看下面这段代码: pu ...
- 浅析关于java的一些基础问题(上篇)
要想让一个问题变难,最基本有两种方式,即极度细化和高度抽象.对于任何语言的研究,良好的基础至关重要,本篇文章,将从极度细化的角度 来解析一些java中的基础问题,这些问题也是大部分编程人员的软肋或易混 ...
- 【春华秋实】.NET Core之只是多看了你一眼
感官初体验 技术学习是一件系统性的事情,如果拒绝学习,那么自己就会落后以至于被替代..NET也是一样,当开源.跨平台成为主流的时候,如果再故步自封,等待.NET的就是死路一条,幸好.NET Core问 ...
- TensorFlow tutorial
代码示例来自https://github.com/aymericdamien/TensorFlow-Examples tensorflow先定义运算图,在run的时候才会进行真正的运算. run之前需 ...