第八篇:支持向量机 (Support Vector Machine)
前言
本文讲解如何使用R语言中e1071包中的SVM函数进行分类操作,并以一个关于鸢尾花分类的实例演示具体分类步骤。
分析总体流程
1. 载入并了解数据集;
2. 对数据集进行训练并生成模型;
3. 在此模型之上调用测试数据集进行分类测试;
4. 查看分类结果;
5. 进行各种参数的调试并重复2-4直至分类的结果让人满意为止。
参数调整策略
综合来说,主要有以下四个方面需要调整:
1. 选择合适的核函数;
2. 调整误分点容忍度参数cost;
3. 调整各核函数的参数;
4. 调整各样本的权重。
其中,对于特征比较多的情况一般用非线性核,比如高斯核。高斯核的特点是参数多,需要不断调试参数才能理想的效果。而线性核没什么参数可设置,一般适用于特征比较少的情况。
关于各核函数的参数,则一般是通过试探法来确定。最好可以将不同样本权重模型,不同核函数参数下的分类准确率做成一张可视化报表,以便于方案确定。
关于3的选择,一般可以通过MDS的可视化图,看有哪几个分类是纠缠不清的,然后就加大这两个分类的样本权重。
鸢尾花分类分析 - 使用支持向量机(SVM)
1. 安装SVM分析所需包:e1071
2. 载入并了解数据集:

可以看出,这个数据集比较理想化,避免了繁琐的数据预处理过程,非常适合作为案例讲解。
3. 建立SVM模型:

这个模型变量相当于是训练库,下面查看该模型的信息:
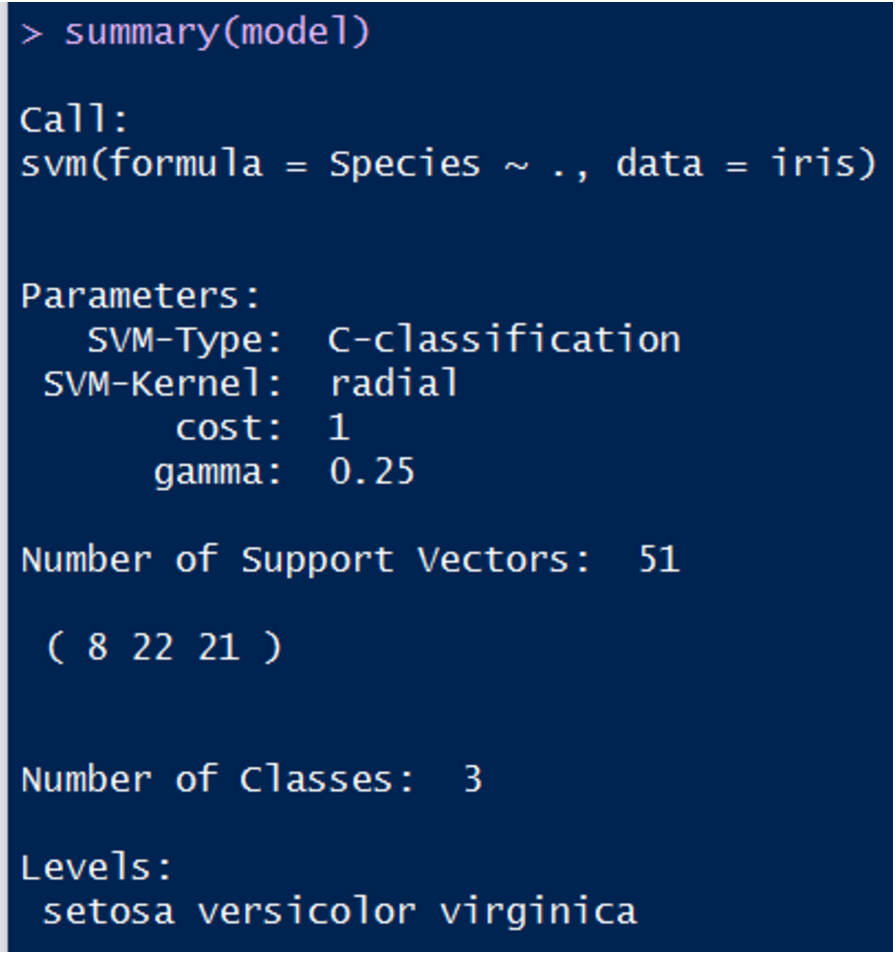
其中,SVM类型是C-classification,核函数是高斯核,cost是误分点容忍度参数,gamma是核函数参数。他们的具体含义请参考函数手册。
4. 利用该模型进行预测

5. 查看预测效果:
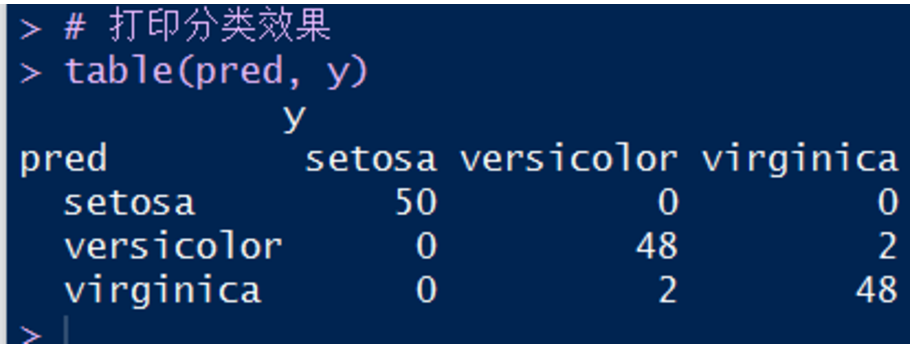
可见,有两个类型似乎混淆了。那怎么办?还有,如果变量多,我如何观察出哪几个变量纠缠不清呢?下面先来解决这个问题。
6. 使用MDS技术查看各变量分类情况
MDS技术可以根据所有样本之间的距离,根据各个变量之间距离不变的设定,将维度降低到两维。一般来说,它是用来分析整体分类的一个态势的:
plot(cmdscale(dist(iris[,-5])), col = c("blue", "green", "orange")[as.integer(iris[,5])], pch = c("o", "+")[1:150 %in% model$index+1])
legend(2, -0.7, c("setosa", "versicolor", "virginica"), col = c("blue", "green", "orange"), lty = 1)
显示效果如下:
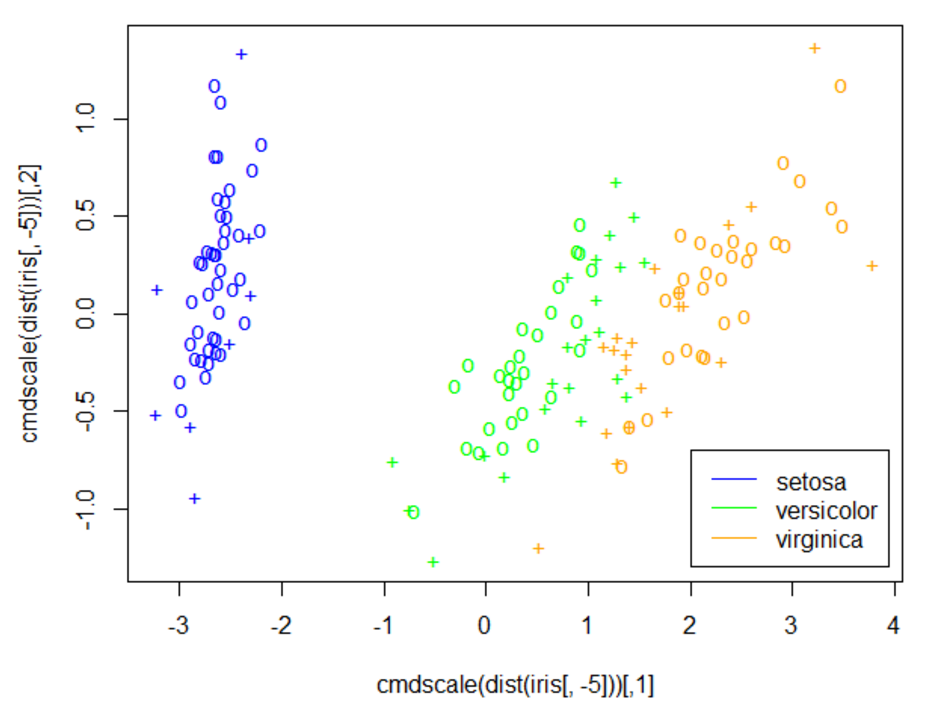
显然,后两个分类有点混淆。
7. 调整各样本权重系数:
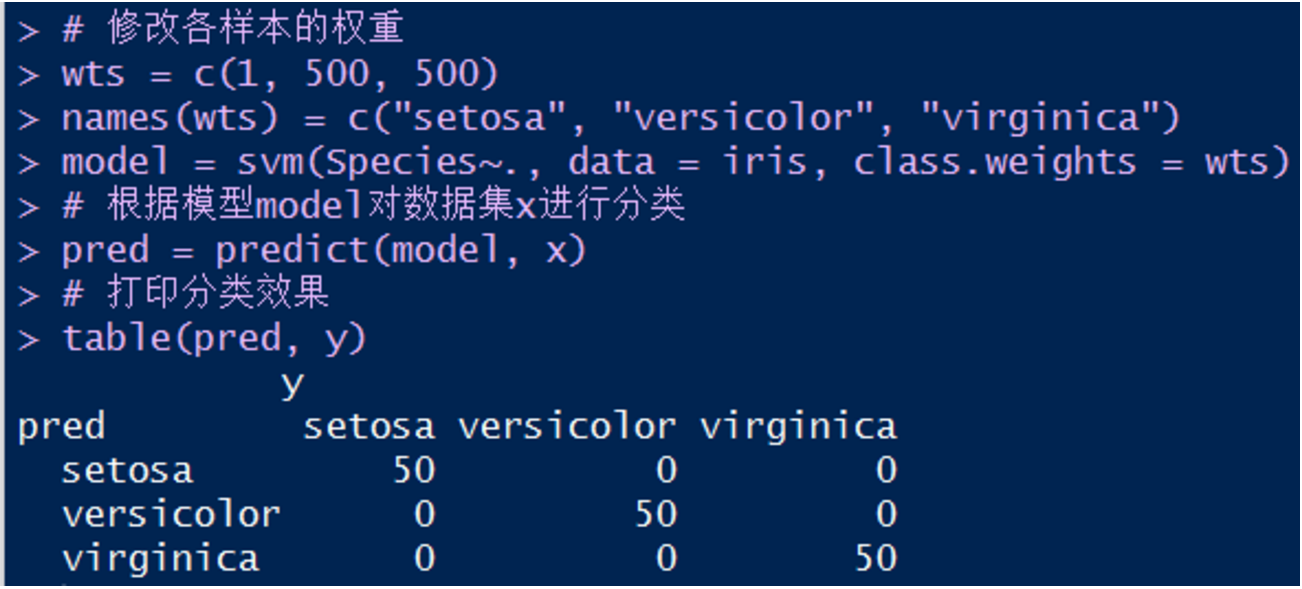
由上图可知,这样的模型产生了更好的分类效果。
小结
1. 本例中的场景比较简单,故未做复杂的参数调整。在实际项目中往往需要对方方面面都进行调整。
2. 虽然SVM在做了标准化后效果更好,但是不用手动标准化。因为SVM函数会自动进行标准化。
3. 对于维度比较少的情况,直接用线性核就好了。
4. SVM是综合指标最好的分类器,但是有它的局限之处,那就是容易过拟合。因此降维工作一定要做好。
第八篇:支持向量机 (Support Vector Machine)的更多相关文章
- 支持向量机 support vector machine
SVM(support Vector machine) (1) SVM(Support Vector Machine)是从瓦普尼克(Vapnik)的统计学习理论发展而来的,主要针对小样本数据进行学习. ...
- 支持向量机(Support Vector Machine)-----SVM之SMO算法(转)
此文转自两篇博文 有修改 序列最小优化算法(英语:Sequential minimal optimization, SMO)是一种用于解决支持向量机训练过程中所产生优化问题的算法.SMO由微软研究院的 ...
- 机器学习(八)--------支持向量机 (Support Vector Machines)
与逻辑回归和神经网络相比,支持向量机或者简称 SVM,更为强大. 人们有时将支持向量机看作是大间距分类器. 这是我的支持向量机模型代价函数 这样将得到一个更好的决策边界 理解支持向量机模型的做法,即努 ...
- 支持向量机(Support Vector Machine,SVM)
SVM: 1. 线性与非线性 核函数: 2. 与神经网络关系 置信区间结构: 3. 训练方法: 4.SVM light,LS-SVM: 5. VC维 u-SVC 与 c-SVC 区别? 除参数不同外, ...
- 支持向量机SVM(Support Vector Machine)
支持向量机(Support Vector Machine)是一种监督式的机器学习方法(supervised machine learning),一般用于二类问题(binary classificati ...
- 6. support vector machine
1. 了解SVM 1. Logistic regression 与SVM超平面 给定一些数据点,它们分别属于两个不同的类,现在要找到一个线性分类器把这些数据分成两类.如果用x表示数据点,用y表示类别( ...
- 斯坦福第十二课:支持向量机(Support Vector Machines)
12.1 优化目标 12.2 大边界的直观理解 12.3 数学背后的大边界分类(可选) 12.4 核函数 1 12.5 核函数 2 12.6 使用支持向量机 12.1 优化目标 到目前为 ...
- 机器学习课程-第7周-支持向量机(Support Vector Machines)
1. 优化目标 在监督学习中,许多学习算法的性能都非常类似,因此,重要的不是你该选择使用学习算法A还是学习算法B,而更重要的是,应用这些算法时,所创建的大量数据在应用这些算法时,表现情况通常依赖于你的 ...
- 5. support vector machine
1. 了解SVM 1. Logistic regression回顾 Logistic regression目的是从特征中学习出一个0/1二分类模型,而这个模型是将特性的线性组合作为自变量,由于自变量的 ...
随机推荐
- 使用 RxJS 实现一个简易的仿 Elm 架构应用
使用 RxJS 实现一个简易的仿 Elm 架构应用 标签(空格分隔): 前端 什么是 Elm 架构 Elm 架构是一种使用 Elm 语言编写 Web 前端应用的简单架构,在代码模块化.代码重用以及测试 ...
- WPF字典集合类ObservableDictionary
WPF最核心的技术优势之一就是数据绑定.数据绑定,可以通过对数据的操作来更新界面. 数据绑定最经常用到的是ObservableCollection<T> 和 Dictionary<T ...
- linux下LAMP环境的搭配
之前电脑上换了ubuntu16.04,本地需要重新配置,但是忘得一干二净,所以重新配置了一下,并再此记录一下. 安装apache: sudo apt-get install apache2 重启apa ...
- PyCharm安装及使用
搭建环境 1.win10_X64,其他Win版本也可以. 2.PyCharm版本:Professional-2016.2.3. 搭建准备 1.到PyCharm官网下载PyCharm安装包. Dow ...
- filezilla server客户端FTP连接不上解决
windows服务器上安装Filezilla server后,本地客户端连接不上.解决办法: 1.在防火墙把filezilla的 Filazilla server interface.exe 和Fil ...
- 使用js dom和jquery分别实现简单增删改
<html><head> <meta http-equiv="Content-Type" content="text/html; chars ...
- Java中简单Http请求
1. 概述 在这篇快速教程中,我们将使用Java内置类HttpUrlConnection来实现一个Http请求. 2. HttpUrlConnection HttpUrlConnection类允许我们 ...
- Linux 每日命令行
uptime 用于查看系统的负载信息. 它依次显示 当前系统时间.系统已运行时间.启用终端数量及平均负载值等信息.平均负载指的是系统在最近1分钟.5分钟.15分钟内的压力情况:负载值越低越好,尽量不要 ...
- hadoopmaster主机上传文件出错: put: File /a.txt._COPYING_ could only be replicated to 0 nodes instead of minReplication (=1). There are 3 datanode(s) running and 3 node(s) are excluded in this operation.
刚开始装好hadoop的时候,namenode机上传文件没有错误,今天打开时突然不能上传文件,报错 put: File /a.txt._COPYING_ could only be replicate ...
- Windows Sublime Text 配置Linux子系统(WSL)下的 gcc/g++ 编译环境
0. 简介(若已了解背景可以跳过此部分) Windows 10 Build 14316以上版本中加入了"Windows系统的Linux子系统"(Windows Subsystem ...