Ames房价预测特征工程
最近学人工智能,讲到了Kaggle上的一个竞赛任务,Ames房价预测。本文将描述一下数据预处理和特征工程所进行的操作,具体代码Click Me。
原始数据集共有特征81个,数值型特征38个,非数值型特征43个。有很多缺失值。
1、离群点检测
以GrLivArea(地上面积)和SalePrice(房价)为自变量和因变量,得到如下散点图:
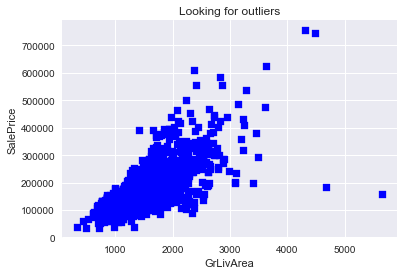
从上图中可以看出有2个极端的离群点在图的右下角(面积很大,但价格很低)。该数据集的提供者建议移除面积大于4000 square feet的数据点(这样就去掉了4个点)。
当然也可以使用其他特征作为自变量,来绘制散点图,检查是否存在离群点。
2、缺失值处理
缺失值处理方法有:删除、统计填充、统一填充、预测填充、具体分析。(可参考这里)
2.1、具体分析,填充缺失值
首先,在Kaggle提供的数据描述中,有说明部分缺省值意味着什么,例如:
BsmtQual: Evaluates the height of the basement
Ex Excellent (100+ inches)
Gd Good (90-99 inches)
TA Typical (80-89 inches)
Fa Fair (70-79 inches)
Po Poor (<70 inches
NA No Basement
也就是说,如果“地下室质量”的值缺失,说明没有地下室。因此,如果BsmtQual值缺失,我们设置为一种新的取值:No(非数值型特征)。如果BsmtFullBath(地下室完整浴室的数量)的值确实,直接设置为0(数值型特征)。
其次,就要对特征进行具体分析了。比如,CentralAir(是否有中央空调)缺失,倾向于没有(如果有的话,房东一般都会写出来吧)。
2.2、其它缺失值填充
上一步未能填充的缺失值,这一步进行统一处理。数值型特征使用中位数填充,非数值型特征将缺失设置为一种新的类型。
3、数值型数据和非数值型数据的转换
有些特征,虽然取值是数值型的,但这些数值是分类的意思,作为数值进行统计分析没有意义,例如:
MSSubClass: Identifies the type of dwelling involved in the sale.
20 1-STORY 1946 & NEWER ALL STYLES
30 1-STORY 1945 & OLDER
40 1-STORY W/FINISHED ATTIC ALL AGES
45 1-1/2 STORY - UNFINISHED ALL AGES
50 1-1/2 STORY FINISHED ALL AGES
60 2-STORY 1946 & NEWER
70 2-STORY 1945 & OLDER
75 2-1/2 STORY ALL AGES
80 SPLIT OR MULTI-LEVEL
85 SPLIT FOYER
90 DUPLEX - ALL STYLES AND AGES
120 1-STORY PUD (Planned Unit Development) - 1946 & NEWER
150 1-1/2 STORY PUD - ALL AGES
160 2-STORY PUD - 1946 & NEWER
180 PUD - MULTILEVEL - INCL SPLIT LEV/FOYER
190 2 FAMILY CONVERSION - ALL STYLES AND AGES
这一特征是房屋风格。虽然取值是数值型的,但这些数值是对风格的分类,应该转换为非数值型的特征。
还有一些特征虽然在类别型的,但存在明显的数值等级,例如:
Alley: Type of alley access to property
Grvl Gravel
Pave Paved
NA No alley access
这一特征是指通向房屋的道路类型。Grvl是碎石路,Paved是水泥路,NA是不通道路。显然,Grvl、Pave、NA这三者存在的关系,分别设置为0、1、2。
4、创建新的特征
4.1、简化已有特征
例如:
OverallQual: Rates the overall material and finish of the house
10 Very Excellent
9 Excellent
8 Very Good
7 Good
6 Above Average
5 Average
4 Below Average
3 Fair
2 Poor
1 Very Poor
该特征是房屋的使用材料和完成品级,从最好到最差,设置了10的档次。我们相应的设置一个简化的SimplOverallQual,将数据的1、2、3映射为1(低品级),4、5、6映射为2(中等水平),7、8、9、10映射为3(高品级)。
4.2、联合已有特征
例如,设置一个新的特征PoolScore(游泳池得分),取值为PoolArea(游泳池面积)和PoolQC(游泳池质量)的乘积。
4.3、现有重要特征(top 10)的多项式
通过计算协方差,找到10个跟房价关联性最强的特征,我们得到了AllSF,AllFlrsSF,GrLivArea,OverallQual,GarageCars,TotalBsmtSF,GarageArea,TotalBath,ExterQual,1stFlrSF这是个特征。
对于top10的每一个特征,都设置三个新的特征,分别是该特征的平方、立方、平方根。
5、数值型特征的数据标准化
数值型特征填充了缺失值之后,我们使用sklearn模块里面的StandardScaler()函数,进行标准化。处理后的数据期望为0,方差为1。
6、非数值型特征处理
对非数值型特征进行one hot编码。
7、遇到的问题
7.1、不要添加与某个属性线性相关的属性。
例如,YearBuilt这个属性,表示的是房屋建造年费。我尝试添加一个房龄属性HouseAge = 2017 - YearBuilt。添加之后,模型的正确率反而下降了。无正则项的线性回归,校验集正确率出现了大幅下滑,LinearRegression.score是个很大的负数,说明模型特别差劲;岭回归校验集正确率出现了小幅下滑。
实际上根本没有必要添加HouseAge。我们看一下HouseAge和YearBuilt标准化之后(使用StandardScaler,转化后均值为0,标准差为1),分别为Std_HouseAge和Std_YearBuilt。由方差与均值的计算规则可知,Std_HouseAge = -Std_YearBuilt。
Ames房价预测特征工程的更多相关文章
- Kaggle竞赛 —— 房价预测 (House Prices)
完整代码见kaggle kernel 或 Github 比赛页面:https://www.kaggle.com/c/house-prices-advanced-regression-technique ...
- 谷歌大规模机器学习:模型训练、特征工程和算法选择 (32PPT下载)
本文转自:http://mp.weixin.qq.com/s/Xe3g2OSkE3BpIC2wdt5J-A 谷歌大规模机器学习:模型训练.特征工程和算法选择 (32PPT下载) 2017-01-26 ...
- 波士顿房价预测 - 最简单入门机器学习 - Jupyter
机器学习入门项目分享 - 波士顿房价预测 该分享源于Udacity机器学习进阶中的一个mini作业项目,用于入门非常合适,刨除了繁琐的部分,保留了最关键.基本的步骤,能够对机器学习基本流程有一个最清晰 ...
- 机器学习实战二:波士顿房价预测 Boston Housing
波士顿房价预测 Boston housing 这是一个波士顿房价预测的一个实战,上一次的Titantic是生存预测,其实本质上是一个分类问题,就是根据数据分为1或为0,这次的波士顿房价预测更像是预测一 ...
- 什么是机器学习的特征工程?【数据集特征抽取(字典,文本TF-Idf)、特征预处理(标准化,归一化)、特征降维(低方差,相关系数,PCA)】
2.特征工程 2.1 数据集 2.1.1 可用数据集 Kaggle网址:https://www.kaggle.com/datasets UCI数据集网址: http://archive.ics.uci ...
- 使用sklearn做单机特征工程
目录 1 特征工程是什么?2 数据预处理 2.1 无量纲化 2.1.1 标准化 2.1.2 区间缩放法 2.1.3 标准化与归一化的区别 2.2 对定量特征二值化 2.3 对定性特征哑编码 2.4 缺 ...
- 【转】使用sklearn做单机特征工程
这里是原文 说明:这是我用Markdown编辑的第一篇随笔 目录 1 特征工程是什么? 2 数据预处理 2.1 无量纲化 2.1.1 标准化 2.1.2 区间缩放法 2.1.3 无量纲化与正则化的区别 ...
- 转载:使用sklearn做单机特征工程
目录 1 特征工程是什么?2 数据预处理 2.1 无量纲化 2.1.1 标准化 2.1.2 区间缩放法 2.1.3 标准化与归一化的区别 2.2 对定量特征二值化 2.3 对定性特征哑编码 2.4 缺 ...
- 使用sklearn进行数据挖掘-房价预测(4)—数据预处理
在使用机器算法之前,我们先把数据做下预处理,先把特征和标签拆分出来 housing = strat_train_set.drop("median_house_value",axis ...
随机推荐
- OpenCV 金字塔图像缩放
// image_pyramid.cpp : 定义控制台应用程序的入口点. // #include "stdafx.h" #include <string> #incl ...
- 一步操作关闭iOS状态栏(电池栏)
状态栏某时也蛮碍眼的: 将其关闭很简单:打开项目的info.plist文件,添加新的属性为NO的一行 View controller-based status bar appearance : 最后结 ...
- Socket层实现系列 — listen()的实现
本文主要分析listen()的内核实现,包括它的系统调用.Socket层实现.半连接队列,以及监听哈希表. 内核版本:3.6 Author:zhangskd @ csdn blog 应用层 int l ...
- CAS实现单点登录--错误记录
遇到的错误: 生成证书: 1. 命令:keytool -genkey -alias smalllove -keyalg RSA -keystore C:/keys/smallkey 错误:ja ...
- Android开发技巧——高亮的用户操作指南
Android开发技巧--高亮的用户操作指南 2015-12-15补记: 发现使用PopupWindow进行遮罩层的显示,在华为P7上会有问题.具体表现为:画出来的高亮部分会偏下.原因为:通过view ...
- objective-c中@autoreleasepool的用法
objc中关于自动释放池,有两种语法,一种old-fashioned是: NSAutoreleasePool *pool = [[NSAutoreleasePool alloc] init]; //d ...
- 我如何踏上IT路
第一次开技术博客,第一篇博文就聊聊自己是如何走上IT这条路的.一直听人说"搞IT的"颇含贬低色彩,也有IT前辈奉劝不要轻易踏上这条路,但最终我这个本是化学化工专业的门外汉还是义无反 ...
- ORACLE数据库部分面试题目
1. 解释冷备份和热备份的不同点以及各自的优点 解答:热备份针对归档模式的数据库,在数据库仍旧处于工作状态时进行备份.而冷备份指在数据库关闭后,进行备份,适用于所有模式的数据库.热备份的优点在于当备份 ...
- java并发包分析之———Deque和LinkedBlockingDeque
一.双向队列Deque Queue除了前面介绍的实现外,还有一种双向的Queue实现Deque.这种队列允许在队列头和尾部进行入队出队操作,因此在功能上比Queue显然要更复杂.下图描述的是Deq ...
- python22期第一天(课程总结)
1.Python介绍: python是一门高级编程语言,涉及领域比较广泛,社区活跃,由一个核心开发团队在维护,相对其他语言,易于学习,可移植性强,可扩展性强,易于维护,有大量的标准库可供使用. 2.P ...