SubQuery优化
https://zhuanlan.zhihu.com/p/60380557
子查询,分两种情况,
对于在From中的,称为‘derived table’,这种场景比较简单
对于在select,where中的,scalar表达式,这是主要要考虑的对象,因为这种情况cross了relational和scalar的处理

子查询,最关键的区分,是关联子查询(Correlated Subquery)和非关联子查询(Non-correlated Subquery)
关联子查询,子查询的执行,子查询参数,依赖于外层父查询输出的属性
非关联子查询,子查询的执行,不依赖于外层父查询的任何属性值,这样子查询具有独立性,可独自求解
非关联子查询的优化非常简单,因为可以独立求解,那就先求出并物化,带入父查询join即可
所以子查询优化的核心就是,去关联,de-correlate
从子查询返回的数据分类,
标量(Scalar-valued)子查询: 输出就是一个标量
存在性检测(Existential Test)子查询:特指 EXISTS 的子查询,返回一个布尔值
集合比较(Quantified Comparision)子查询:特指 IN、SOME、ANY 的查询,返回一个布尔值或Null,可能返回null


先看几篇基础的论文,
Microsoft的论文,
Parameterized Queries and Nesting Equivalencies - C Galindo-Legaria
Orthogonal Optimization of Subqueries and Aggregation - C Galindo-Legaria, M Joshi
Execution Strategies for SQL Subqueries - Mostafa Elhemali
Parameterized Queries and Nesting Equivalencies
这篇论文核心,是提出Apply算子,并且如何通过各种规则,把Apply算子转换为普通的join
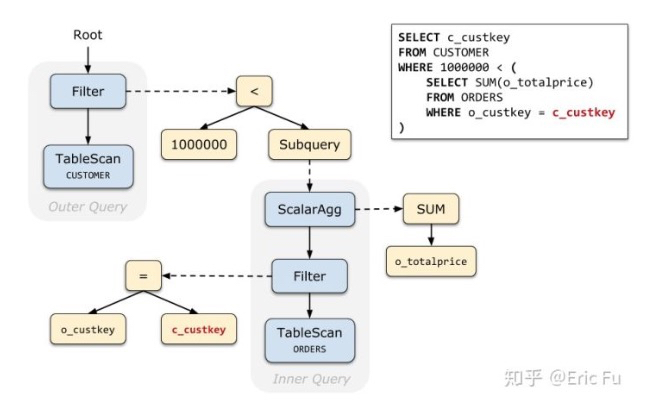
例子中一个,标量子查询的例子,
对于关联子查询,语义其实就是,对于outer表的每一行数据,都执行一遍子查询,这个非常类似,function programming里面的Apply算子
所以这里就是是用Apply算子来,描述这种关联性
Apply算子的定义,
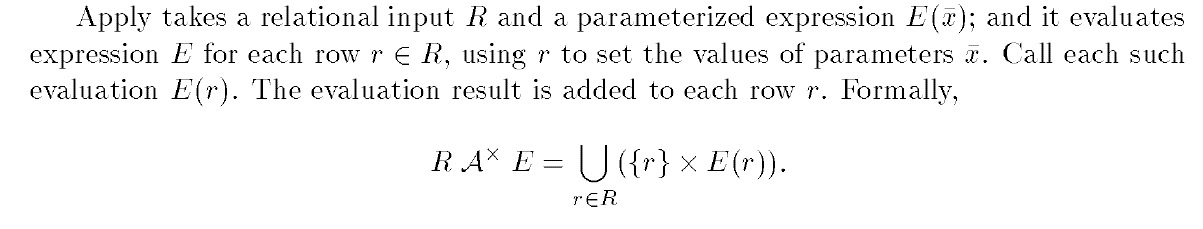
对于关系表R,其中每个r,带入E,因为E是个参数化expression,把结果求并集
这里其实对于R是要求Distinct,因为R中的r可能会重复,所以一般会加上一个算子去重
中间的A❌就代表apply算子,这里和普通join一样,根据对于E返回的Empty的处理,分为,

看上面的例子,用Apply算子的结果,
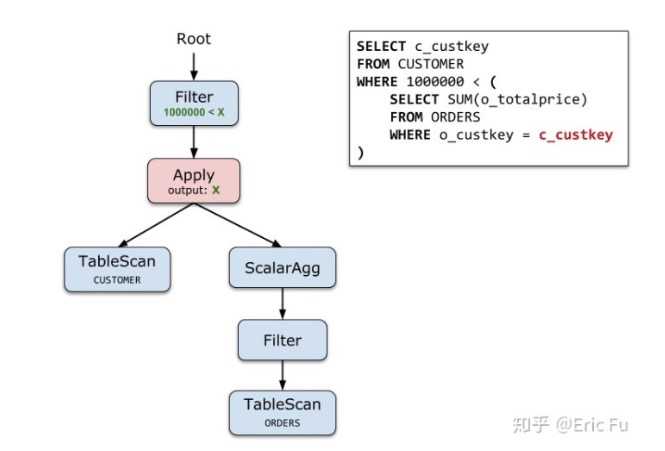
如果outer表足够小,并且有比较好的indexes的情况下,Correlatied执行效率也很好的
但是大多数一般情况下,Apply执行明显效率很低,所以要基于Apply算子去进行优化,Apply算子是个中间状态,比原来的形式更加容易使用关系代数优化
Apply的优化就,SubQuery unnesting或correlation removel,就是把Apply算子转换为regular join的过程,
下面看个最直接的例子,

Orthogonal Optimization of Subqueries and Aggregation
先看个例子,
标量,关联子查询的例子
最直接的方法,直接Correlated execution,不一定低效,如果Outer表很小,并且有适当的索引

80年代,提出过一些优化的方案,
比如,先Outerjoin,再aggregate的方案

或者,先Aggregate,再Join

但是这些方案,不是系统的方法论,不同的情况下,需要分析并使用不同的方法,
本文的方式是,把这些方法分解成,orthogonal, reusable primitives,用的时候可以组合起来,用cost-estimation的方式,评估到底使用哪些primitives
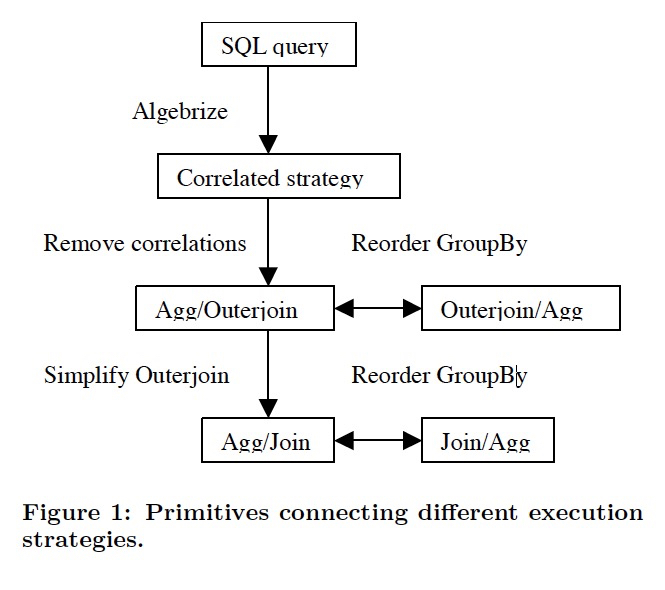
可以看出,分为图中的几步,下面分别解释一下各个步骤,
Algebrize
用Apply算子来抽象和替换parameterized execution of subexpressions
Apply算子的好处在于,去除relation和scalar节点间的mutual recursion
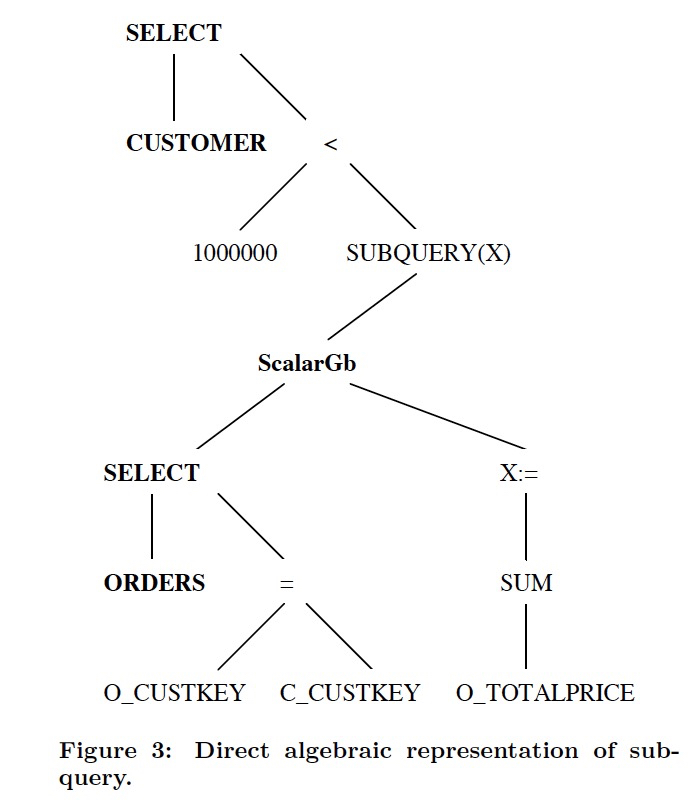
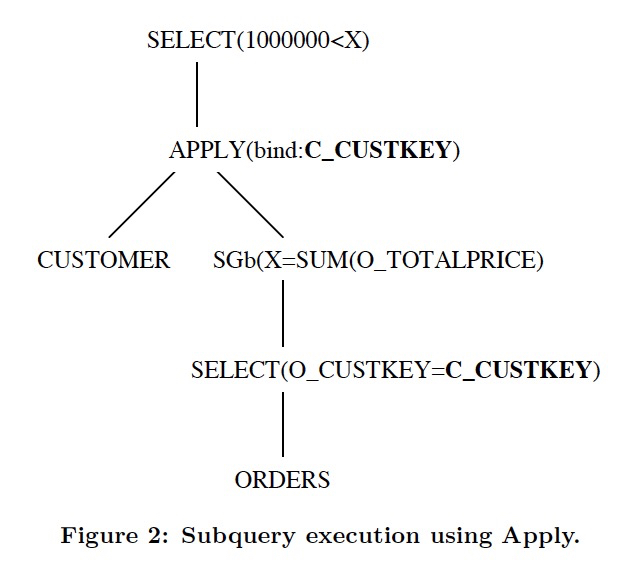
例子,左图,查询中有,scalar表达式,scalar表达式中又有子查询,所以执行的时候,需要反复在查询计划执行器和表达式执行器之间不断切换,效率很低,而且隔着scalar表达式,没法用关系代数进行优化或reorder
所以用Apply算子变换到右图,把子查询从scalar表达式中remove掉,放到关系代数树中
这里用标量子查询为例,但是其他的子查询也是一样的
这步只是对过程做了抽象,但实际上并没有改变执行计划
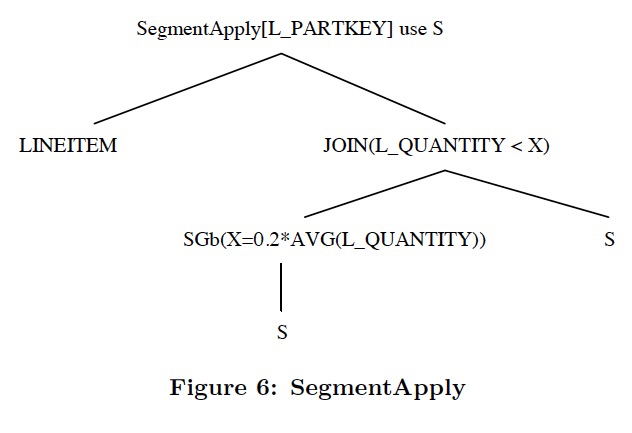
这里还提到一种,SegmentApply算子

可以认为是batch版本的Apply算子
因为我们可以用column A对R进行分组,对于每一组,table-valued,去调用E
a就是Distinct(A)
Remove Correlation
也就是remove apply
做法, 不断下推Apply,直到不关联了,转化为regular join
The process consists of pushing down Apply in the operator tree, towards the leaves, until the right child of Apply is no longer parameterized off the left child.
可以使用的转换rules,

(1) (2),左右不相干的情况下,apply可以直接转化成join
后面所有rules的目的,就是要转换成满足 (1) (2)
这里,(8)(9),比较难理解
首先,先看两个概念,

Vector Aggregation,GroupBY聚合,group by A,aggregate with Function F
关键,表为空的时候,返回也是empty
Scalar Aggregation,全局聚合,不指定A,aggregate with Function F
关键,总会有一行返回值,不会为empty;并且返回值和Aggregate函数相关,如果是sum,返回null,如果是count,返回0
(8)中,columns(R)表示join key,把group by提到外面后,需要先按照join key做group by
(8)和(9)的差别就是,(9)是Scalar Aggregation,所以返回值对于empty会出现null,所以F’需要特殊处理,用非null的column
再者Scalar Aggre提到外面后变成Vector Aggre (group by join key)
下面看个例子,仍然是上面的SQL

首先,为什么是Scalar Aggre,因为这里Group by join key,对于Apply算子,group by每次只apply到一个customer,所以是Scalar Aggre
用(9),把Scalar Aggre提出来,变成Vector Aggre
提出GroupBY后,剩下的可以直接应用(2)消除Apply
最后,由于最终的aggre结果需要非null,所以可以简化成inner join
Reorder Groupby
Groupby可以和其他算子进行交换,比如filter,join等
GroupBy的Reorder是否会降低cost,这个需要cost model去判断,比如先GroupBY,后Join,还是先Join,后GroupBy
GroupBy和Filter Reorder
条件,if and only if all the columns used in the filter are functionally determined by the grouping columns in the input relation
过滤的columns,由GroupBy columns决定
GroupBy和Join Reorder
GroupBy pushdown 条件,

GroupBy Pullup的条件,

Segmented Execution
以TPCH-17为例,
完成去关联后的计划如下,

这个计划的问题是,我们其实不用对所有Lineitem的rows都做这样的聚合过滤,其实只是需要对过滤后的PartKey对应的lineitem做

所以这里的方法是,把LineItem按照partkey进行group,每个group叫做Segment,然后对Segment执行子查询
叫做SegmentApply,
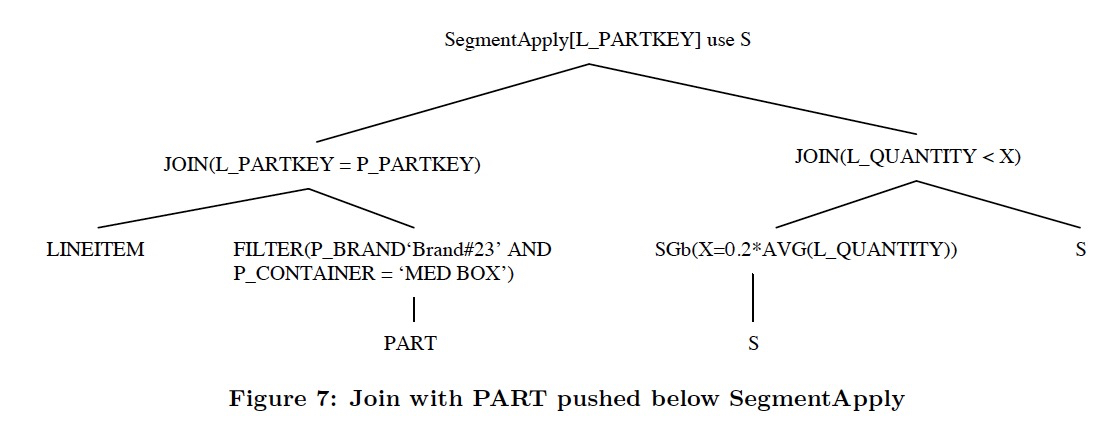
对于SegmentApply,下面要做的是,按照Part的条件过滤Segments,也就是要把外部的条件Push down到SegmentApply里面,
push down的条件是,segment的完整性,join的条件以segment为条件进行过滤,而不会过滤掉部分row


完成pushdown的结果如下,在SegmentApply之前,先会对LineItem做join进行过滤掉不需要的segment
SubQuery优化的更多相关文章
- 【MySQL】优化—工欲善其事,必先利其器之EXPLAIN
接触MySQL已经有一段时间了,了解如何优化它也迫在眉睫了,话说工欲善其事,必先利其器.最近我就打算了解下几个优化MySQL中经常用到的工具.今天就简单介绍下EXPLAIN. 环境准备 Explain ...
- MySQL优化—工欲善其事,必先利其器之EXPLAIN(转)
最近慢慢接触MySQL,了解如何优化它也迫在眉睫了,话说工欲善其事,必先利其器.最近我就打算了解下几个优化MySQL中经常用到的工具.今天就简单介绍下EXPLAIN. 内容导航 id select_t ...
- MySQL优化—工欲善其事,必先利其器之EXPLAIN
最近慢慢接触MySQL,了解如何优化它也迫在眉睫了,话说工欲善其事,必先利其器.最近我就打算了解下几个优化MySQL中经常用到的工具.今天就简单介绍下EXPLAIN. 内容导航 id select_t ...
- MySQL使用现状分析与优化
前言 再紧张的裁员氛围,也不该影响你学习的心态.不要本末倒置,技术永远不会落后,只要你还在学习的道路上,没有后退. 数据库架构 目前生产环境RDS是多区可用架构.数据库实例发生计划内或计划外的中断时, ...
- mysql之explain
⊙ 使用EXPLAIN语法检查查询执行计划 ◎ 查看索引的使用情况 ◎ 查看行扫描情况 ⊙ 避免使用SELECT * ◎ 这会导致表的全扫描 ◎ 网络带宽会被浪费 话说工欲善其 ...
- [慢查优化]慎用MySQL子查询,尤其是看到DEPENDENT SUBQUERY标记时
案例梳理时间:2013-9-25 写在前面的话: 在慢查优化1和2里都反复强调过 explain 的重要性,但有时候肉眼看不出 explain 结果如何指导优化,这时候还需要有一些其他基础知识的佐助, ...
- 深入理解MySql子查询IN的执行和优化
IN为什么慢? 在应用程序中使用子查询后,SQL语句的查询性能变得非常糟糕.例如: SELECT driver_id FROM driver where driver_id in (SELECT dr ...
- 我的MYSQL学习心得(十六) 优化
我的MYSQL学习心得(十六) 优化 我的MYSQL学习心得(一) 简单语法 我的MYSQL学习心得(二) 数据类型宽度 我的MYSQL学习心得(三) 查看字段长度 我的MYSQL学习心得(四) 数据 ...
- Mysql性能优化一
下一篇:Mysql性能优化二 mysql的性能优化无法一蹴而就,必须一步一步慢慢来,从各个方面进行优化,最终性能就会有大的提升. Mysql数据库的优化技术 对mysql优化是一个综合性的技术,主要包 ...
随机推荐
- PHP Lumen Laravel 解决validate方法自定义message无效的问题
/** * 由于 \Laravel\Lumen\Routing\ProvidesConvenienceMethods::validate 在验证不通过时, * 抛出 \Illuminate\Valid ...
- Kubectl Rollout 回滚及Autoscale自动扩容
Kubectl Rollout 回滚及Autoscale自动扩容 Kubernetes 中采用ReplicaSet(简称RS)来管理Pod.如果当前集群中的Pod实例数少于目标值,RS 会拉起新的Po ...
- linux档案和目录管理(后续)
资料来自鸟哥的linux私房菜 四:档案和目录的预设权限和隐藏权限 umask:预设权限,相比与chomd的4,2,1权限,档案满分为666,目录满分为777,umask可以预设消除部分权限,比如一个 ...
- Response响应相关
response是响应的对象 response.text # 返回的是字节,数据的原内容response.content # 返回的是字符串,默认是utf-8解码 import reques ...
- Python面向对象三要素-继承(Inheritance)
Python面向对象三要素-继承(Inheritance) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.继承概述 1>.基本概念 前面我们学习了Python的面向对象三 ...
- python read PDF for chinese
import sys import importlib importlib.reload(sys) from pdfminer.pdfparser import PDFParser,PDFDocume ...
- 动态管理upsteam---nginx_http_dyups_module
nginx_http_dyups_module nginx_http_dyups_module是第三方开源软件,它提供API动态修改upstream的配置,并且支持Nginx的ip_hash.kee ...
- POI不同浏览器导出名称处理
/** * * @Title: encodeFileName * @Description: 导出文件转换文件名称编码 * @param @param fileNames * @param @para ...
- 基于源代码为树莓派设备构建 TensorFlow
本指南为运行 Raspbian 9.0 操作系统的 Raspberry Pi 嵌入式设备构建 TensorFlow.虽然这些说明可能也适用于其他系列的 Raspberry Pi 设备,但它仅针对此文中 ...
- 关于git clone远程仓库账户密码错误的问题
这两天刚使用coding和git,但是在我第一次克隆coding上的项目的时候,提示输入账户和密码,当时我不知道这个账户和密码是指的哪个,就随便输入了,然后提示错误,,,,,, 之后每次克隆的时候都提 ...