利用Tengine在树莓派上跑深度学习网络
树莓派是国内比较流行的一款卡片式计算机,但是受限于其硬件配置,用树莓派玩深度学习似乎有些艰难。最近OPENAI为嵌入式设备推出了一款AI框架Tengine,其对于配置的要求相比传统框架降低了很多,我尝试着在树莓派上进行了搭建并成功运行了Mobilenet-SSD。
Tengine简介
- Tengine 是OPEN AI LAB 为嵌入式设备开发的一个轻量级、高性能并且模块化的引擎。
- Tengine在嵌入式设备上支持CPU,GPU,DLA/NPU,DSP异构计算的计算框架,实现异构计算的调度器,基于ARM平台的高效的计算库实现,针对特定硬件平台的性能优化,动态规划计算图的内存使用,提供对于网络远端AI计算能力的访问支持,支持多级别并行,整个系统模块可拆卸,基于事件驱动的计算模型,吸取已有AI计算框架的优点,设计全新的计算图表示。
编译安装开源版Tengine
安装相关工具
sudo apt-get install git cmake
安装支持库
sudo apt-get install libprotobuf-dev protobuf-compiler libboost-all-dev libgoogle-glog-dev libopencv-dev libopenblas-dev
- protobuf 是一种轻便高效的数据存储格式,这是caffe各种配置文件所使用的数据格式
- boost 是一个c++的扩展程序库,稍后Tengine的编译依赖于该库
- google-glog 是一个google提供的日志系统的程序库
- opencv 是一个开源的计算机视觉库
- openblas 是一个开源的基础线性代数子程序库
下载&编译
以下的所有步骤建议在pi用户下完成(而非root),不然可能报错。
1.从github上下载最新的开源版Tengine源码
git clone https://github.com/OAID/Tengine.git
2.切换工作目录到Tengine
cd Tengine
3.准备好配置文件
Tengine目录下提供了配置模板 makefile.config.example 文件
cp makefile.config.example makefile.config
4.修改配置文件 makefile.config
由于开源版的Tengine不支持针对armv7的优化,所以需要用openblas替代实现;
将 CONFIG_ARCH_ARM64=y 这一行注释掉(行首加井号 #)以关闭ARM64架构的优化实现;
解除 CONFIG_ARCH_ARM32=y 这一行解除注释(删除行首的井号 #)以开启BLAS计算库的实现方式
CONFIG_ARCH_BLAS=y 这一行不需要解除注释
5.编译并安装
make -j4
make install
这里的 -j4 表示开启四个线程进行编译
测试
1.下载mobilenet-ssd模型并放置在 Tengine/models 目录下
两个文件:MobileNetSSD_deploy.caffemodel 和 MobileNetSSD_deploy.prototxt
下载链接(提取码为57vb):https://pan.baidu.com/s/1LXZ8vOdyOo50IXS0CUPp8g
如果是测试YOLOv2则下载
yolo-voc.prototxtyolo-voc.caffemodel
2.将工作目录切换到mobilenet-ssd示例程序的目录下
cd ~/Tengine/examples/mobilenet_ssd
3.编译示例程序
cmake -DTENGINE_DIR=/home/pi/Tengine .
make
这里 -DTENGINE_DIR用于为cmake指定环境变量TENGINE_DIR,该变量可以在CMakeLists.txt文件中找到
4.运行示例程序
./MSSD
指定参数:
./MSSD -p mssd.prototxt -m mssd.caffemodel -i img.jpg
等待良久后,出现例程的运行结果:

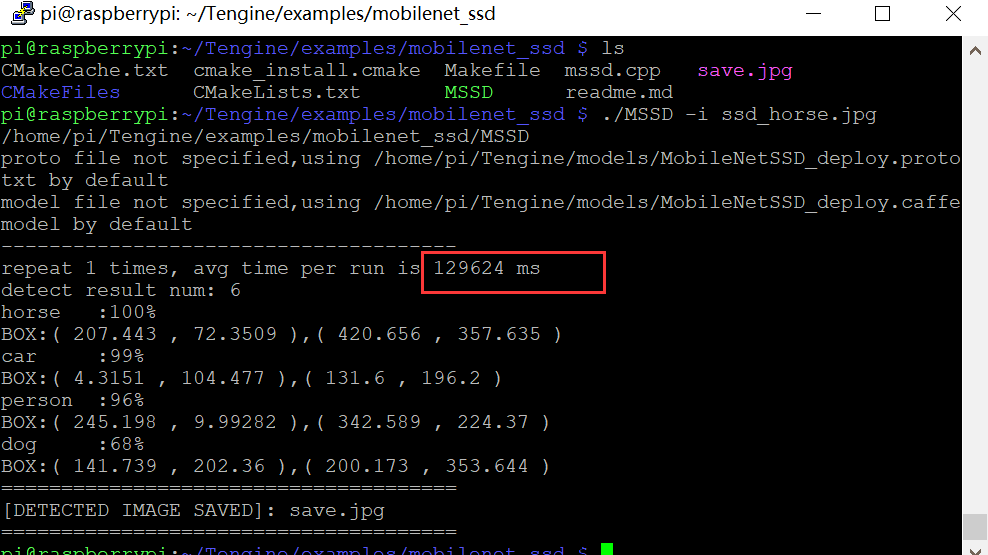
可以看到例程运行耗时2分钟,考虑到例程仅识别了一张图片一次,算法运行速度很不理想。
对比在RK3399上的表现,除了树莓派的硬件配置较低外(我用的树莓派3B),所使用的计算库的不同也是重要的原因,BLAS的库计算性能要差于Tengine提供的官方库。
参考链接:
1. https://blog.csdn.net/qq_33287871/article/details/99686969
2. https://songrbb.github.io/2018/08/17/利用Tengine在树莓派上跑深度学习网络/?tdsourcetag=s_pctim_aiomsg
3. https://github.com/OAID/Tengine/tree/master/examples/mobilenet_ssd
利用Tengine在树莓派上跑深度学习网络的更多相关文章
- 用TVM在硬件平台上部署深度学习工作负载的端到端 IR 堆栈
用TVM在硬件平台上部署深度学习工作负载的端到端 IR 堆栈 深度学习已变得无处不在,不可或缺.这场革命的一部分是由可扩展的深度学习系统推动的,如滕索弗洛.MXNet.咖啡和皮托奇.大多数现有系统针对 ...
- 从零开始在ubuntu上配置深度学习开发环境
从零开始在ubuntu上配置深度学习开发环境 昨天一不小心把原来配置好的台式机的开发环境破坏了,调了半天没有调回来,索性就重装一次ubuntu系统.这篇文章主要记录一个简单的.‘傻瓜式’教程. 一.U ...
- github上热门深度学习项目
github上热门深度学习项目 项目名 Stars 描述 TensorFlow 29622 使用数据流图进行可扩展机器学习的计算. Caffe 11799 Caffe:深度学习的快速开放框架. [Ne ...
- <深度学习优化策略-3> 深度学习网络加速器Weight Normalization_WN
前面我们学习过深度学习中用于加速网络训练.提升网络泛化能力的两种策略:Batch Normalization(Batch Normalization)和Layer Normalization(LN). ...
- 如何免费使用GPU跑深度学习代码
从事深度学习的研究者都知道,深度学习代码需要设计海量的数据,需要很大很大很大(重要的事情说三遍)的计算量,以至于CPU算不过来,需要通过GPU帮忙,但这必不意味着CPU的性能没GPU强,CPU是那种综 ...
- 点云上的深度学习及其在三维场景理解中的应用(PPT内容整理PointNet)
这篇博客主要是整理了PointNet提出者祁芮中台介绍PointNet.PointNet++.Frustum PointNets的PPT内容,内容包括如何将点云进行深度学习,如何设计新型的网络架构 ...
- 训练深度学习网络时候,出现Nan是什么原因,怎么才能避免?——我自己是因为data有nan的坏数据,clear下解决
from:https://www.zhihu.com/question/49346370 Harick 梯度爆炸了吧. 我的解决办法一般以下几条:1.数据归一化(减均值,除方差,或者加入n ...
- 【神经网络与深度学习】chainer边运行边定义的方法使构建深度学习网络变的灵活简单
Chainer是一个专门为高效研究和开发深度学习算法而设计的开源框架. 这篇博文会通过一些例子简要地介绍一下Chainer,同时把它与其他一些框架做比较,比如Caffe.Theano.Torch和Te ...
- 如何可视化深度学习网络中Attention层
前言 在训练深度学习模型时,常想一窥网络结构中的attention层权重分布,观察序列输入的哪些词或者词组合是网络比较care的.在小论文中主要研究了关于词性POS对输入序列的注意力机制.同时对比实验 ...
随机推荐
- 【2019.7.25 NOIP模拟赛 T3】树(tree)(dfs序列上开线段树)
没有换根操作 考虑如果没有换根操作,我们该怎么做. 我们可以求出原树的\(dfs\)序列,然后开线段树维护. 对于修改操作,我们可以倍增求\(LCA\),然后在线段树上修改子树内的值. 对于询问操作, ...
- 关于 Noip的考纲
关于 \(\text{Noip}\) 的考纲 先放一张图 : 此图包含了 \(\text{Noip}\) 自开始到结束 的所有真题的考察知识点 算法分类标准主要来自于 \(\text{Luogu}\) ...
- 算法八字符串转换正数(atoi)
请你来实现一个 atoi 函数,使其能将字符串转换成整数. 首先,该函数会根据需要丢弃无用的开头空格字符,直到寻找到第一个非空格的字符为止. 当我们寻找到的第一个非空字符为正或者负号时,则将该符号与之 ...
- JavaScript forEach() 方法
JavaScript forEach() 方法 JavaScript Array 对象 实例 列出数组的每个元素: <button onclick="numbers.forEach( ...
- Docker学习4-学会如何让容器开机自启服务
前言 小龙亲测重启服务器后 docker 容器没跑起来,相信有不少小伙伴在用docker部署容器的时候也发现每次开机服务就没有自启了,需要手动去执行把容器服务开启起来,但有没有可以让它开机自启呢?显然 ...
- Eureka服务注册中心错误:com.sun.jersey.api.client.ClientHandlerException: java.net.ConnectException: Connection refused: connect
报错信息 14:43:45.484 [main] INFO com.netflix.discovery.DiscoveryClient - Getting all instance registry ...
- 连接树莓派中的MySQL服务器
今天用笔记本连接树莓派的 MySQL ,结果连接不上.就直接连接到树莓派上进行操作.其实以前也知道远程访问 MySQL 需要进行配置,可以直接 mysql.user 表,也可以直接使用授权的 SQL ...
- javascript 写一个 map方法
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- AJAX发送异步请求教程详解
AJAX 一.AJAX简介 什么是 AJAX ? AJAX = 异步 JavaScript 和 XML. AJAX 是一种用于创建快速动态网页的技术. 通过在后台与服务器进行少量数据交换,AJAX 可 ...
- Elasticsearch PUT 插入数据
{ "error": { "root_cause": [ { "type": "illegal_argument_exceptio ...