目标检测算法之R-CNN和SPPNet原理
一、R-CNN的原理
R-CNN的全称是Region-CNN,它可以说是第一个将深度学习应用到目标检测上的算法。后面将要学习的Fast R-CNN、Faster R-CNN全部都是建立在R-CNN基础上的。
传统的目标检测方法大多以图像识别为基础。一般可以在图片上使用穷举法选出所有物体可能出现的区域框,对这些区域框提取特征并使用图像识别方法分类,得到所有分类成功的区域后,通过非极大值抑制(Non-maximum suppression,NMS)输出结果。
R-CNN遵循传统目标检测的思路,同样采用提取框、对每个框提取特征、图像分类、非极大值抑制四个步骤进行目标检测。只不过在提取特征这一步,将传统的特征(如SIFT、HOG特征等)换成了深度卷积网络提取的特征。R-CNN的整体算法框架如图所示。

对于原始图像,首先使用Selective Search搜寻可能存在物体的区域。Selective Search可以从图像中启发式地搜索出可能包含物体的区域。相比穷举而言,Selective Search可以减少一部分计算量。下一步,将取出的可能含有物体的区域送入CNN网络中提取特征。CNN通常是接受一个固定大小的图像,而取出的区域大小却各有不同。对此,R-CNN的做法是将区域缩放到统一大小,再使用CNN提取特征。提取出特征后使用SVM分类,最后通过非极大值抑制输出结果。
R-CNN的训练可以分为下面四步:
(1)在数据集上训练CNN。R-CNN论文中使用的CNN网络是AlexNet,数据集为ImageNet。
(2)在目标检测的数据集上,对训练好的CNN做微调。
(3)用Selective Search搜索候选区域,统一使用微调后的CNN对这些区域提取特征,并将提取到的特征存储起来。
(4)使用存储起来的特征,训练SVM分类器。
尽管R-CNN的识别框架与传统方法区别不是很大,但是得益于CNN优异的特征提取能力,R-CNN的效果还是比传统方法好很多。如在VOC 2007数据集上,传统方法的最高的平均精确度 mAP(mean Average Precision)为40%左右,而R-CNN的mAP达到了58.5%!
R-CNN的缺点是计算量太大。在一张图片中,通过Selective Search得到的有效区域往往在1000个以上,这意味着要重复计算1000多次神经网络,非常耗时。另外,在训练阶段,还需要把所有特征保存起来,再通过SVM进行训练,这也是非常耗时且麻烦的。后面将要学习的Fast R-CNN和Faster R-CNN在一定程度上改进了R-CNN计算量大的特点,不仅速度变快不少,识别准确率也得到了提高。
二、SPPNet的原理
在学习R-CNN的改进版Fast R-CNN之前,作为前置知识,有必要学习SPPNet的原理。SPPNet的英文全称是 Spatial Pyramid Pooling Convolutional Networks,翻译成中文是“空间金字塔池化卷积网络”。听起来十分高深,实际上原理并不难,简单来讲,SPPNet主要做了一件事情:将CNN的输入从固定尺寸改进为任意尺寸。例如,在普通的CNN结构中,输入图像的尺寸往往是固定的(如224x224像素),输出可以看做是一个固定维数的向量。SPPNet在普通的CNN结构中加入了ROI池化层(ROI Pooling,ROI是Region of Interest的简写,指的是在“特征图上的框”),使得网络的输入图像可以是任意尺寸的,输出则不变,同样是一个固定维数的向量。
ROI池化层一般跟在卷积层后面,它的输入是任意大小的卷积,输出是固定维数的向量,如下图所示。
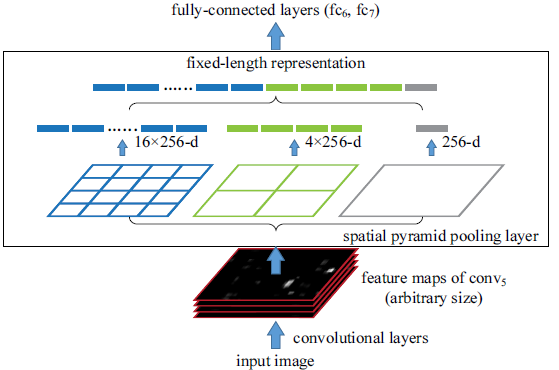
为了说清楚为什么ROI池化层能够把任意大小的卷积特征转换为固定长度的向量,不妨设卷积层输出的宽度为w,高度为h,通道为c。不管输入的图像尺寸是多少,卷积层的通道数都不会变,也就是说c是一个常数。而w、h会随着输入图像尺寸的变化而变化,可以看作是两个变量。以上图中的ROI池化层为例,它首先把卷积层划分为4x4的网格,每个网格的宽是w/4、高是h/4、通道数为c。当不能整除时,需要取整。
接着,对每个网格中的每个通道,都取出其最大值,换句话说,就是对每个网格内的特征做最大值池化(Max Pooling,关于池化可以联系到卷积神经网络中的池化操作)。这个4x4的网格最终就形成了16c维的特征。接着,再把网格划分成2x2的网格,用同样的方法提取特征,提取的特征的长度为4c。再把网络划分为1x1的网格,提取的特征的长度就是c,最后的1x1的划分实际是取出卷积中每个通道的最大值。最后,将得到的特征拼接起来,得到的特征是16c+4c+1c=21c维的特征。很显然,这个输出特征的长度与w、h两个值是无关的,因此ROI池化层可以把任意宽度、高度的卷积特征转换为固定长度的向量
应该怎么把ROI池化层用到目标检测中来呢?其实,可以这样考虑该问题:网络的输入是一张图像,中间经过若干卷积形成了卷积特征,这个卷积特征实际上和原始图像在位置上是有一定对应关系的。如下图所示。

在上图中,原始图像中有一辆汽车,它使得卷积特征在同样位置产生了激活。因此,原始图像中的候选框,实际上也可以对应到卷积特征中相同位置的框。由于候选框的大小千变万化,对应到卷积特征的区域形状也各有不用,但是不用担心,利用ROI池化层可以把卷积特征中的不同形状的区域对应到同样长度的向量特征。综合上述步骤,就可以将原始图像中的不同长宽的区域都对应到一个固定长度的向量特征,这就完成了各个区域的特征提取工作。
在R-CNN中,对于原始图像的各种候选区域框,必须把框中的图像缩放到统一大小,再对每一张缩放后的图片提取特征。使用ROI池化层后,就可以先对图像进行一遍卷积计算,得到整个图像的卷积特征;接着,对于原始图像中的各种候选框,只需要在卷积特征中找到对应的位置框,再使用ROI池化层对位置框中的卷积提取特征,就可以完成特征提取工作。
R-CNN和SPPNet的不同点在于,R-CNN要对每个区域计算卷积,而SPPNet只需要计算一次,因此SPPNet的效率比R-CNN高得多。
R-CNN和SPPNet的相同点在于,它们都遵循着提取候选框、提取特征、分类这几个步骤。在提取特征后,它们都使用了SVM进行分类。
目标检测算法之R-CNN和SPPNet原理的更多相关文章
- (三)目标检测算法之SPPNet
今天准备再更新一篇博客,加油呀~~~ 系列博客链接: (一)目标检测概述 https://www.cnblogs.com/kongweisi/p/10894415.html (二)目标检测算法之R-C ...
- 深度学习笔记之目标检测算法系列(包括RCNN、Fast RCNN、Faster RCNN和SSD)
不多说,直接上干货! 本文一系列目标检测算法:RCNN, Fast RCNN, Faster RCNN代表当下目标检测的前沿水平,在github都给出了基于Caffe的源码. • RCNN RCN ...
- 第二十九节,目标检测算法之R-CNN算法详解
Girshick, Ross, et al. “Rich feature hierarchies for accurate object detection and semantic segmenta ...
- 目标检测算法的总结(R-CNN、Fast R-CNN、Faster R-CNN、YOLO、SSD、FNP、ALEXnet、RetianNet、VGG Net-16)
目标检测解决的是计算机视觉任务的基本问题:即What objects are where?图像中有什么目标,在哪里?这意味着,我们不仅要用算法判断图片中是不是要检测的目标, 还要在图片中标记出它的位置 ...
- (五)目标检测算法之Faster R-CNN
系列博客链接: (一)目标检测概述 https://www.cnblogs.com/kongweisi/p/10894415.html (二)目标检测算法之R-CNN https://www.cnbl ...
- (四)目标检测算法之Fast R-CNN
系列博客链接: (一)目标检测概述 https://www.cnblogs.com/kongweisi/p/10894415.html (二)目标检测算法之R-CNN https://www.cnbl ...
- 目标检测算法YOLO算法介绍
YOLO算法(You Only Look Once) 比如你输入图像是100x100,然后在图像上放一个网络,为了方便讲述,此处使用3x3网格,实际实现时会用更精细的网格(如19x19).基本思想是, ...
- FAIR开源Detectron:整合全部顶尖目标检测算法
昨天,Facebook AI 研究院(FAIR)开源了 Detectron,业内最佳水平的目标检测平台. 昨天,Facebook AI 研究院(FAIR)开源了 Detectron,业内最佳水平的目标 ...
- AI SSD目标检测算法
Single Shot multibox Detector,简称SSD,是一种目标检测算法. Single Shot意味着SSD属于one stage方法,multibox表示多框预测. CNN 多尺 ...
- 目标检测算法之R-CNN算法详解
R-CNN全称为Region-CNN,它可以说是第一个成功地将深度学习应用到目标检测上的算法.后面提到的Fast R-CNN.Faster R-CNN全部都是建立在R-CNN的基础上的. 传统目标检测 ...
随机推荐
- 学习shiro第三天
今天比较晚,所以只看了shiro的认证策略Authentication Strategy,下面讲讲shiro的三种认证策略. 1.AtLeastOneSuccessfulStrategy:这个是shi ...
- AD读取Excel新建客户邮箱的测试环境部署有感
现有AD的账户操作所有服务几乎用WebApi方式,此 方法是便于搭建和部署,做到了前后端的分离 ,其中验证Exchange邮箱转发模块时发现foxmail的exchange本地邮箱配置极其简单,以此记 ...
- SVG撑满页面
当viewBox属性固定,默认修改svg标签的宽高,svg都会按比例缩放 我们现在不想按比例缩放,需要svg撑满整个画面 这里只需为svg标签添加一个关键属性:preserveAspectRatio ...
- CTF挑战赛丨网络内生安全试验场第一季答题赛火热开启
前期回顾:挑战世界级“人机大战”,更有万元奖金等你来拿 网络内生安全试验场自上线以来,受到了业内的极大重视与关注. 自9月2日报名通道开启后,报名量更是持续高升,上百名精英白帽踊跃报名. 至此,网络内 ...
- Spring事务部分知识点整理
目录 1.数据库事务基础概念 2.Spring中注解事务的使用 3.Spring事务使用注意场景 1.数据库事务基础概念 数据库事务是对数据库一次一系列的操作组成的单元,可以包含增删改查或者只有单 ...
- bat延迟执行脚本,利用choice实现定时执行功能
choice是选择语句,具体语法另外再讲.今天利用它来实现定时执行功能.废话少说直接上代码: 示例一: @echo off for %%a in (我 是 一 个 中 国 人) do ping -n ...
- nginx Linux内核参数的优化
默认的Linux内核参数考虑的是最通用的场景,这明显不符合用于支持高并发访问的Web服务器的定义,所以需要修改Linux内核参数,使得Nginx可以拥有更高的性能. 这里针对最通用的.使Nginx支持 ...
- Jenkins + Pipeline + Git + Maven (十)
一.准备环境介绍 192.168.5.71 # gitlab 仓库IP 192.168.5.72 # 开发环境,用于提交代码等 192.168.5.73 # tomcat 部署solo服务站点 192 ...
- 团队——Alpha2版本发布
这个作业属于哪个课程 课程链接 这个作业要求在哪里 作业要求的链接 团队名称 杨荣模杰和他的佶祥虎 这个作业的目标 发布并说明产品Alpha2版本 一.团队成员的学号姓名列表 学号 姓名 201731 ...
- 八种排序算法原理及Java实现
原文链接:http://ju.outofmemory.cn/entry/372908