Keras 入门实例
使用Keras构建神经网络的基本工作流程主要可以分为 4个部分。(而这个用法和思路,很像是在使用Scikit-learn中的机器学习方法)
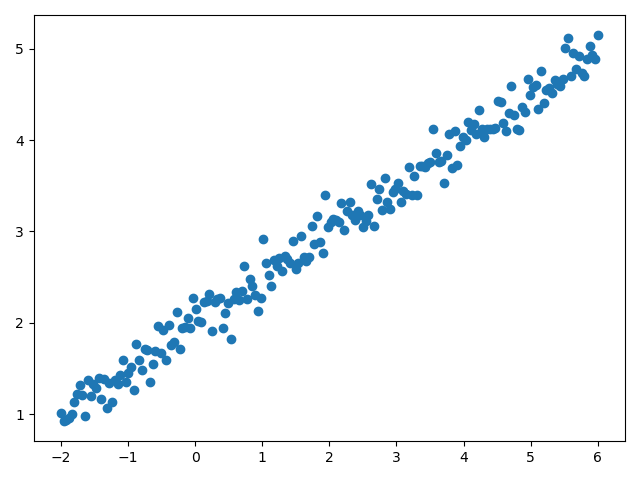
# # 首先 人为地造一组由 y=0.5x+2 加上一些噪声而生成的数据,数据量一共有200个,其中160作为train set ,后40作为test set
import numpy as np
import matplotlib.pyplot as plt X = np.linspace(-2,6,200)
np.random.shuffle(X)
Y = 0.5 * X +2+0.15*np.random.randn(200,) # plot data
plt.scatter(X,Y)
plt.show() X_train, Y_train = X[:160], Y[:160] #train first 160 data points
X_test, Y_test = X[160:], Y[160:] # test remaining 40 data points
绘制出的数据的分布情况如下:
from keras.models import Sequential
from keras.layers import Dense
(1)Sequential是Keras中构建NN最常用的一种Model(也是最简单的一种),一个Sequential的Model 就是 a linear stack of layers,也就是说,你只要按顺序(使用add()方法)一层一层地顺序地添加神经网络层就可以了。
model = Sequential()
model.add(Dense(output_dim = 1, input_dim = 1))
model.compile(loss='mse', optimizer='sgd')
from keras.optimizers import SGD
model.compile(loss='mse', optimizer=SGD(lr=0.01, momentum=0.9, nesterov=True))
model.fit(X_train, Y_train, epochs=100, batch_size=64)
model.train_on_batch(x_batch, y_batch) # 运行一批样品的单次梯度更新。
print('Training -----------')
for step in range(100):
cost = model.train_on_batch(X_train, Y_train)
if step % 20 == 0:
print('train cost: ', cost)

cost = model.evaluate(X_test, Y_test, batch_size=40)
具体来说针对上面这个例子则有:
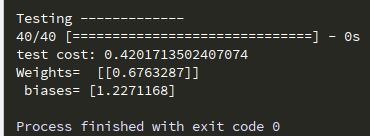
print('\nTesting -------------')
loss_and_metrics =model.evaluate(X_test,Y_test,batch_size=40)
print('test cost:',loss_and_metrics)
W,b = model.layers[0].get_weights()
print('Weights= ',W, '\n biases=',b)
那么对一些新的数据进行预测的话,可以使用 predict,而且它的使用也与Scikit-learn中的用法及其相似, 最终我们预测test set 中的每个的点,并绘制预测的模型。
Y_pred =model.predict(X_test)
plt.scatter(X_test,Y_test)
plt.plot(X_test,Y_test)
plt.show()

5、最后附上完整的代码文件:
import numpy as np
import theano.tensor as T
import keras
from keras import backend as K
from keras import initializations
# from keras import initializers ###### In Keras 2.0, initializations was renamed (mirror) as initializers.
from keras.models import Sequential, Model, load_model, save_model
from keras.layers.core import Dense, Lambda, Activation
from keras.layers import Embedding, Input, Dense, merge, Reshape, Merge, Flatten
from keras.optimizers import Adagrad, Adam, SGD, RMSprop
from keras.regularizers import l2
from Dataset import Dataset
from evaluate import evaluate_model
from time import time
import multiprocessing as mp
import sys
import math
import argparse print(keras.__version__) # 使用的默认的Backend:TensorFlow #修改 # # 首先 人为地造一组由 y=0.5x+2 加上一些噪声而生成的数据,数据量一共有200个,其中160作为train set ,后40作为test set
import numpy as np
import matplotlib.pyplot as plt X = np.linspace(-2,6,200)
np.random.shuffle(X)
Y = 0.5 * X +2+0.15*np.random.randn(200,) # # plot data
# plt.scatter(X,Y)
# plt.show() X_train, Y_train = X[:160], Y[:160] #train first 160 data points
X_test, Y_test = X[160:], Y[160:] # test remaining 40 data points # 第一步,即 Model Definition:
from keras.models import Sequential
from keras.layers import Dense model = Sequential()
model.add(Dense(output_dim=1, input_dim=1)) # 第二步,即Model compilation:
model.compile(loss='mse',optimizer='sgd') # 第三步,即 Training:
# model.fit(X_train,Y_train,epochs=100,batch_size=64) # epochs=100会报错是怎么回事
# 或者:
print('Training ----------------')
for step in range(100):
cost = model.train_on_batch(X_train,Y_train)
if step %20 ==0:
print('train cost: ',cost) # 第四步:Evaluation and Prediction的部分
# cost=model.evaluate(X_test,Y_test,batch_size=40)
# 具体来说针对我们现在这个例子则有:
print('\nTesting -------------')
loss_and_metrics =model.evaluate(X_test,Y_test,batch_size=40)
print('test cost:',loss_and_metrics)
W,b = model.layers[0].get_weights()
print('Weights= ',W, '\n biases=',b) # 那么对一些新的数据进行预测的话,可以使用 predict,而且它的使用也与Scikit-learn中的用法及其相似,
# 最终我们预测test set 中的每个的点,并绘制预测的模型。
Y_pred =model.predict(X_test)
plt.scatter(X_test,Y_test)
plt.plot(X_test,Y_test)
plt.show()
【Reference】
1、https://blog.csdn.net/baimafujinji/article/details/78384792
Keras 入门实例的更多相关文章
- React 入门实例教程(转载)
本人转载自: React 入门实例教程
- struts入门实例
入门实例 1 .下载struts-2.3.16.3-all .不摆了.看哈就会下载了. 2 . 解压 后 找到 apps 文件夹. 3. 打开后将 struts2-blank.war ...
- Vue.js2.0从入门到放弃---入门实例
最近,vue.js越来越火.在这样的大浪潮下,我也开始进入vue的学习行列中,在网上也搜了很多教程,按着教程来做,也总会出现这样那样的问题(坑啊,由于网上那些教程都是Vue.js 1.x版本的,现在用 ...
- wxPython中文教程入门实例
这篇文章主要为大家分享下python编程中有关wxPython的中文教程,分享一些wxPython入门实例,有需要的朋友参考下 wxPython中文教程入门实例 wx.Window 是一个基类 ...
- Omnet++ 4.0 入门实例教程
http://blog.sina.com.cn/s/blog_8a2bb17d01018npf.html 在网上找到的一个讲解omnet++的实例, 是4.0下面实现的. 我在4.2上试了试,可以用. ...
- Spring中IoC的入门实例
Spring中IoC的入门实例 Spring的模块化是很强的,各个功能模块都是独立的,我们可以选择的使用.这一章先从Spring的IoC开始.所谓IoC就是一个用XML来定义生成对象的模式,我们看看如 ...
- Node.js入门实例程序
在使用Node.js创建实际“Hello, World!”应用程序之前,让我们看看Node.js的应用程序的部分.Node.js应用程序由以下三个重要组成部分: 导入需要模块: 我们使用require ...
- Java AIO 入门实例(转)
Java7 AIO入门实例,首先是服务端实现: 服务端代码 SimpleServer: public class SimpleServer { public SimpleServer(int port ...
- Akka入门实例
Akka入门实例 Akka 是一个用 Scala 编写的库,用于简化编写容错的.高可伸缩性的 Java 和 Scala 的 Actor 模型应用. Actor模型并非什么新鲜事物,它由Carl Hew ...
随机推荐
- .net 调用 Python脚本中的代码
使用工具:IronPython 工具介绍:是一种在 .NET 及 Mono上的 Python 实现,是一个开源的项目,基于微软的 DLR 引擎.(个人理解就是在 .net上面运行Python代码) 使 ...
- C# 文件监听类 FileSystemWatcher 属性
属性: Path——这个属性告诉FileSystemWatcher它需要监控哪条路径.例如,如果我们将这个属性设为“C:Temp”,对象就监控那个目录发生的所有改变.IncludeSubDirecto ...
- 获取PostgreSQL数据库中得JSON值
在PostgreSQL数据库中有一列为JSON,要获取JSON中得数据可以用下面sql: select orderno as OrderNo ,amount as Amount ,ordertime ...
- C#使用Redis实现网站统计访问数或点赞数功能!
1.安装.net操作Redis需要的NuGet包: 这里推荐使用:StackExchange.Redis,在程序包管理器控制台输入命令install-package stackexchange.red ...
- 模板模式创建一个poi导出功能
之前的导出都很乱,直接写在代码中,等到下回还使用导出功能时又不知如何下手,今天用模板模式重写了一个导出功能,方便以后使用: package com.sf.addrCheck.util.export.p ...
- because its MIME type ('text/html') is not a supported stylesheet MIME type, and strict MIME checkin
1 前言 浏览器报错误(chrome和firefox都会):because its MIME type ('text/html') is not a supported stylesheet MIME ...
- 写给自己的 SOA 和 RPC 理解
1.SOA SOA(Service-Oriented Architecture)面向服务架构,将应用程序不同功能单元(称为服务)进行拆分,并通过这些服务之间定义良好的接口和契约联系起来. SOA 不是 ...
- 移动端调试神器vconsole,手机端网页的调试工具Eruda
移动端调试神器vconsole,手机端网页的调试工具Eruda 移动端中使用 vConsole调试 移动端调试工具vconsole安装Git地址:https://github.com/WechatFE ...
- nginx之旅(第三篇):代理、正向代理、反向代理、代理的原理、nginx反向代理场景、nginx反向代理配置、nginx反向代理语法
一.代理服务与反向代理 什么是代理服务 代理-代理办理(代理理财.代理收货.代理购物等等). 一般情况下,如果没有特别说明,代理技术默认说的是正向代理技术.关于正向代理的概念如下: 正向代理(forw ...
- ELK+Logback进行业务日志分析查看
第1章 Elasticsearch安装部署 1.1 下载软件包并创建工作目录 程序下载地址:https://artifacts.elastic.co/downloads/elasticsearch/e ...