Scrapy爬虫案例 | 数据存储至MySQL
首先,MySQL创建好数据库和表
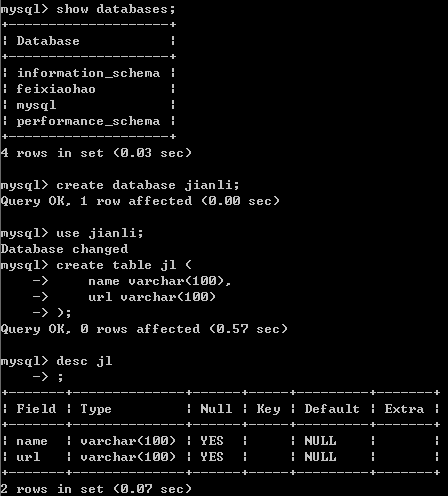
然后编写各个模块
item.py
import scrapy class JianliItem(scrapy.Item):
name = scrapy.Field()
url = scrapy.Field()
pipeline.py
import pymysql #导入数据库的类 class JianliPipeline(object):
conn = None
cursor = None def open_spider(self,spider):
print('开始爬虫')
self.conn = pymysql.Connect(host='127.0.0.1',port=3306,user='root',password='',db='jianli') #链接数据库 def process_item(self, item, spider): #编写向数据库中存储数据的相关代码
self.cursor = self.conn.cursor() #1.链接数据库
sql = 'insert into jl values("%s","%s")'%(item['name'],item['url']) #2.执行sql语句 try: #执行事务
self.cursor.execute(sql)
self.conn.commit() except Exception as e:
print(e)
self.conn.rollback() return item def close_spider(self,spider):
print('爬虫结束')
self.cursor.close()
self.conn.close()
spider
# -*- coding: utf-8 -*-
import scrapy
import re
from lxml import etree
from jianli.items import JianliItem class FxhSpider(scrapy.Spider):
name = 'jl'
# allowed_domains = ['feixiaohao.com']
start_urls = ['http://sc.chinaz.com/jianli/free_{}.html'.format(i) for i in range(3)] def parse(self,response):
tree = etree.HTML(response.text)
a_list = tree.xpath('//div[@id="container"]/div/a') for a in a_list:
item = JianliItem (
name=a.xpath("./img/@alt")[0],
url=a.xpath("./@href")[0]
) yield item
settings.py
#USER_AGENT
headers = {
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"
} # Obey robots.txt rules
ROBOTSTXT_OBEY = False # Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'jianli.pipelines.JianliPipeline': 300,
}
查看存储情况
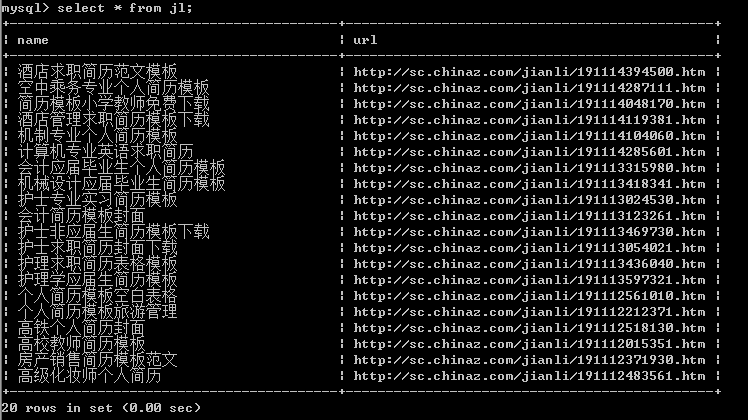
Scrapy爬虫案例 | 数据存储至MySQL的更多相关文章
- Scrapy爬虫案例 | 数据存储至MongoDB
豆瓣电影TOP 250网址 要求: 1.爬取豆瓣top 250电影名字.演员列表.评分和简介 2.设置随机UserAgent和Proxy 3.爬取到的数据保存到MongoDB数据库 items.py ...
- python3下scrapy爬虫(第十卷:scrapy数据存储进mysql)
上一卷中我将爬取的数据文件直接写入文本文件中,现在我将数据存储到mysql中,我依然用的是pymysql,这个很麻烦建表需要在外面建 这次代码只需要改变pipyline就行 来 现在看下结果: 对比发 ...
- 猫眼电影爬取(一):requests+正则,并将数据存储到mysql数据库
前面讲了如何通过pymysql操作数据库,这次写一个爬虫来提取信息,并将数据存储到mysql数据库 1.爬取目标 爬取猫眼电影TOP100榜单 要提取的信息包括:电影排名.电影名称.上映时间.分数 2 ...
- python之scrapy爬取数据保存到mysql数据库
1.创建工程 scrapy startproject tencent 2.创建项目 scrapy genspider mahuateng 3.既然保存到数据库,自然要安装pymsql pip inst ...
- 第四天,同步和异常数据存储到mysql,item loader方法
github对应代码:伯乐在线文章爬取 一. 普通插入方法 1. 连接到我的阿里云,用户名是test1,然后在navicat中新建数据库
- Spring Boot 揭秘与实战(二) 数据存储篇 - MySQL
文章目录 1. 环境依赖 2. 数据源3. 脚本初始化 2.1. 方案一 使用 Spring Boot 默认配置 2.2. 方案二 手动创建 4. 使用JdbcTemplate操作5. 总结 4.1. ...
- 使用MapReduce读取HBase数据存储到MySQL
Mapper读取HBase数据 package MapReduce; import org.apache.hadoop.hbase.Cell; import org.apache.hadoop.hba ...
- 第十节:Web爬虫之数据存储与MySQL8.0数据库安装和数据插入
用解析器解析出数据之后,接下来就是存储数据了,保存的形式可以多种多样,最简单的形式是直接保存为文本文件,如 TXT.JSON.csv 另外,还可以保存到数据库中,如关系型数据库MySQL ,非关系型数 ...
- 爬虫实践——数据存储到Excel中
在进行爬虫实践时,我已经爬取到了我需要的信息,那么最后一个问题就是如何把我所爬到的数据存储到Excel中去,这是我没有学习过的知识. 如何解决这个问题,我选择先百度查找如何解决这个问题. 百度查到的方 ...
随机推荐
- Maven安装及配置(Linux系统)
环境说明:Linux环境,CentOS 7版本. 第一步:下载Maven,地址:http://maven.apache.org/download.cgi 我这里下载的是[apache-maven-3. ...
- git在使用push指令的时候产生的错误
一.问题我们在使用git指令的时候往往会出现如下错误. $ git push -u origin master To https://github.com/pzq7025/ss-fly.git ! [ ...
- 【在 Nervos CKB 上做开发】Nervos CKB 脚本编程简介[4]:在 CKB 上实现 WebAssembly
作者:Xuejie 原文链接:https://xuejie.space/2019_10_09_introduction_to_ckb_script_programming_wasm_on_ckb/ N ...
- 部署elasticsearch(三节点)集群+filebeat+kibana
用途 ▷ 通过各个beat实时收集日志.传输至elasticsearch集群 ▷ 通过kibana展示日志 实验架构 名称:IP地址:CPU:内存 kibana&cerebro:192.168 ...
- 立个铁矿石的flag,从7月初开始,铁矿石的库存,可能要进入累库存阶段了.
从发货量倒推出的到货量,用来评估未来的到货量 推测的到港量与实际北方6港到港量的关系 通过月度到港量,估计出北方6港对全国到港量的正确性. 悲观的库存预期 乐观的库存预期 大概率的情况吧
- springboot WebMvcConfigurer配置静态资源和解决跨域
前言 虽然现在都流行前后端分离部署,但有时候还是需要把前端文件跟后端文件一起打包发布,这就涉及到了springboot的静态资源访问的问题.不单只是静态资源打包,比如使用本地某个目录作为文件存储,也可 ...
- 关于springMVC中的路径问题
相对路径中,我们最后想要的到的是绝对路径,而绝对路径=参照路径+相对路径: 相对路径往往都知道,只需要区分参照路径即可:对于前台和后台,参照路径不太相同: 什么是前台,后台路径: 前台路径: 出现在 ...
- 玩转zynq7010+ FPGA点亮三色灯
前期主要以开发Z-TURN的PL部分为主,以期望了解该芯片的逻辑架构和系统总线,以及所有外设,后面在开始PS部分的开发,闲话少说,先看整个7z010的系统框图,所有开发目前基于ISE14.6来设置, ...
- Vue -- 项目报错整理(2):IE报错 - ‘SyntaxError:strict 模式下不允许一个属性有多个定义‘ ,基于vue element-ui页面跳转坑的解决
- 你能想象未来的MES系统是什么样吗?
“智能制造”热潮席卷神州大地,在工业4.0热潮,以及国家大力推进中国制造2025的背景下,建设智能工厂,推进智能制造已成为制造企业共同的目标.作为承上启下的车间级综合信息系统,MES系统得到了制造企业 ...