Scrapy爬虫案例 | 数据存储至MySQL
首先,MySQL创建好数据库和表
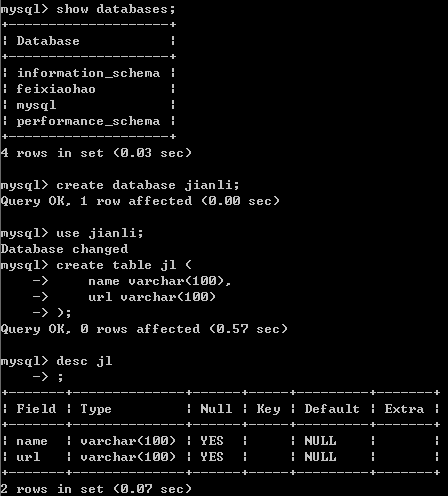
然后编写各个模块
item.py
import scrapy class JianliItem(scrapy.Item):
name = scrapy.Field()
url = scrapy.Field()
pipeline.py
import pymysql #导入数据库的类 class JianliPipeline(object):
conn = None
cursor = None def open_spider(self,spider):
print('开始爬虫')
self.conn = pymysql.Connect(host='127.0.0.1',port=3306,user='root',password='',db='jianli') #链接数据库 def process_item(self, item, spider): #编写向数据库中存储数据的相关代码
self.cursor = self.conn.cursor() #1.链接数据库
sql = 'insert into jl values("%s","%s")'%(item['name'],item['url']) #2.执行sql语句 try: #执行事务
self.cursor.execute(sql)
self.conn.commit() except Exception as e:
print(e)
self.conn.rollback() return item def close_spider(self,spider):
print('爬虫结束')
self.cursor.close()
self.conn.close()
spider
# -*- coding: utf-8 -*-
import scrapy
import re
from lxml import etree
from jianli.items import JianliItem class FxhSpider(scrapy.Spider):
name = 'jl'
# allowed_domains = ['feixiaohao.com']
start_urls = ['http://sc.chinaz.com/jianli/free_{}.html'.format(i) for i in range(3)] def parse(self,response):
tree = etree.HTML(response.text)
a_list = tree.xpath('//div[@id="container"]/div/a') for a in a_list:
item = JianliItem (
name=a.xpath("./img/@alt")[0],
url=a.xpath("./@href")[0]
) yield item
settings.py
#USER_AGENT
headers = {
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"
} # Obey robots.txt rules
ROBOTSTXT_OBEY = False # Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'jianli.pipelines.JianliPipeline': 300,
}
查看存储情况
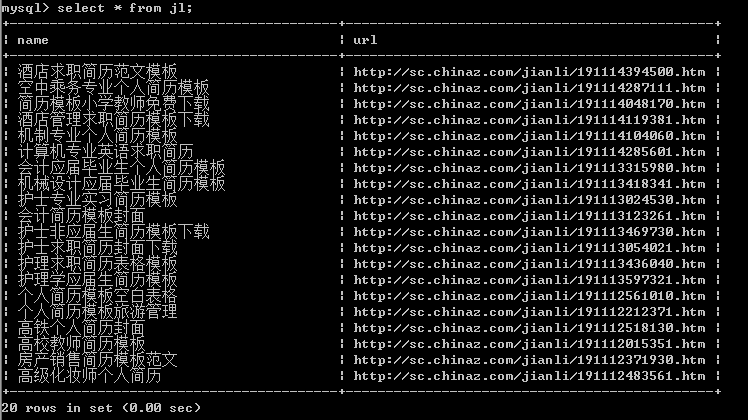
Scrapy爬虫案例 | 数据存储至MySQL的更多相关文章
- Scrapy爬虫案例 | 数据存储至MongoDB
豆瓣电影TOP 250网址 要求: 1.爬取豆瓣top 250电影名字.演员列表.评分和简介 2.设置随机UserAgent和Proxy 3.爬取到的数据保存到MongoDB数据库 items.py ...
- python3下scrapy爬虫(第十卷:scrapy数据存储进mysql)
上一卷中我将爬取的数据文件直接写入文本文件中,现在我将数据存储到mysql中,我依然用的是pymysql,这个很麻烦建表需要在外面建 这次代码只需要改变pipyline就行 来 现在看下结果: 对比发 ...
- 猫眼电影爬取(一):requests+正则,并将数据存储到mysql数据库
前面讲了如何通过pymysql操作数据库,这次写一个爬虫来提取信息,并将数据存储到mysql数据库 1.爬取目标 爬取猫眼电影TOP100榜单 要提取的信息包括:电影排名.电影名称.上映时间.分数 2 ...
- python之scrapy爬取数据保存到mysql数据库
1.创建工程 scrapy startproject tencent 2.创建项目 scrapy genspider mahuateng 3.既然保存到数据库,自然要安装pymsql pip inst ...
- 第四天,同步和异常数据存储到mysql,item loader方法
github对应代码:伯乐在线文章爬取 一. 普通插入方法 1. 连接到我的阿里云,用户名是test1,然后在navicat中新建数据库
- Spring Boot 揭秘与实战(二) 数据存储篇 - MySQL
文章目录 1. 环境依赖 2. 数据源3. 脚本初始化 2.1. 方案一 使用 Spring Boot 默认配置 2.2. 方案二 手动创建 4. 使用JdbcTemplate操作5. 总结 4.1. ...
- 使用MapReduce读取HBase数据存储到MySQL
Mapper读取HBase数据 package MapReduce; import org.apache.hadoop.hbase.Cell; import org.apache.hadoop.hba ...
- 第十节:Web爬虫之数据存储与MySQL8.0数据库安装和数据插入
用解析器解析出数据之后,接下来就是存储数据了,保存的形式可以多种多样,最简单的形式是直接保存为文本文件,如 TXT.JSON.csv 另外,还可以保存到数据库中,如关系型数据库MySQL ,非关系型数 ...
- 爬虫实践——数据存储到Excel中
在进行爬虫实践时,我已经爬取到了我需要的信息,那么最后一个问题就是如何把我所爬到的数据存储到Excel中去,这是我没有学习过的知识. 如何解决这个问题,我选择先百度查找如何解决这个问题. 百度查到的方 ...
随机推荐
- Java学习:数据库连接池技术
本节内容 数据库连接池 Spring JDBC : JDBC Template 数据库连接池 1.概念:其实就是一个容器(集合),存放数据库连接的容器 当系统初始化好后,容器中会申请一些连接对象,当用 ...
- 基于 DNS 动态发现方式部署 Etcd 集群
使用discovery的方式来搭建etcd集群方式有两种:etcd discovery和DNS discovery.在 「基于已有集群动态发现方式部署etcd集群」一文中讲解了etcd discove ...
- ClassPathBeanDefinitionScanner 说明
Spring 工具类 ClassPathBeanDefinitionScanner 组件Bean定义扫描https://blog.csdn.net/andy_zhang2007/article/det ...
- rsyslog详解实战和避坑
目标是要把线上环境的debug日志及集中化收集起来,一方面是方便开发调试:一方面是避免直接到线上环境查看,存在安全隐患. 常用可选方案: rsyslog发送端 + rsyslog接收端: 直接存在接收 ...
- Ubuntu系统下容器化部署gitlab
容器化部署gitlab 获取镜像文件 1. 下载镜像文件 docker pull beginor/gitlab-ce:-ce. 2. 创建GitLab 的配置 (etc) . 日志 (log) .数据 ...
- Spring AOP 复习
Aspect Oriented Programming 通过预编译方式和运行期动态代理实现程序功能的统一维护的一种技术,利用aop可以对业务逻辑的各个部分进行隔离,从而使得业务逻辑各部分之间的耦合度降 ...
- 关于DataX
1. 关于DataX 1.1. 前言 为什么写这篇文章,因为初出茅庐的时候,曾经遇到的一个面试官就是DataX的作者之一,而当时我还偏偏因为业务需求做了个数据库的同步工具,我当时不知道他做过这么专业的 ...
- Ubuntu下映射网络驱动器
Ubuntu下映射网络驱动器https://www.linuxidc.com/Linux/2013-07/86928.htm linux下samba访问路径: smb://192.168.1.111/ ...
- jq 实现切换菜单选中状态
点击导航菜单,切换选中状态 效果: 思路:首先获取选中的URL,再通过正则判断是否相同,相同就加上相应的属性,不相同就去除相应的属性. html代码 <div class="layui ...
- Python学习日记(三十九) Mysql数据库篇 七
Mysql函数 高级函数 1.BIN(N) 返回N的二进制编码 ); 执行结果: 2.BINARY(str) 将字符串str转换为二进制字符串 select BINARY('ASCII'); 执行结果 ...