Spark通过修改DataFrame的schema给表字段添加注释(转载)
转载自:https://www.jianshu.com/p/e4c90dc08935
1、需求背景
通过Spark将关系型数据库(以Oracle为例)的表同步的Hive表,要求用Spark建表,有字段注释的也要加上注释。Spark建表,有两种方法:
- 用Spark Sql,在程序里组建表语句,然后用Spark.sql("建表语句")建表,这种方法麻烦的地方在于你要读取Oracle表的详细的表结构信息,且要进行Oracle和Hive的字段类型进行一一对应
- 用DataFrame 的saveAsTable方法,这种方法如果对应的数据库里没有表,则Spark会根据DataFrame的schema自动建表,比较简单,不用考虑字段类型匹配转化问题,但是这种方法有一个问题,Spark读取Oracle的表为DataFrame时,并不能将表字段的注释读进来,所以就有了如标题所示的需求。(一开始以为DataFrame不能加注释,经过研究,发现是可以的!)
2、如何查看DataFrame是否有注释
前面讲到DataFrame里没有Oracle的注释信息,但是如果数据源为Hive的话,是可以将注释获取到的。
2.1 新建Hive测试表(带注释)
create table `test` (
`id` string comment 'ID',
`Name` string comment '名字'
)
comment '测试';

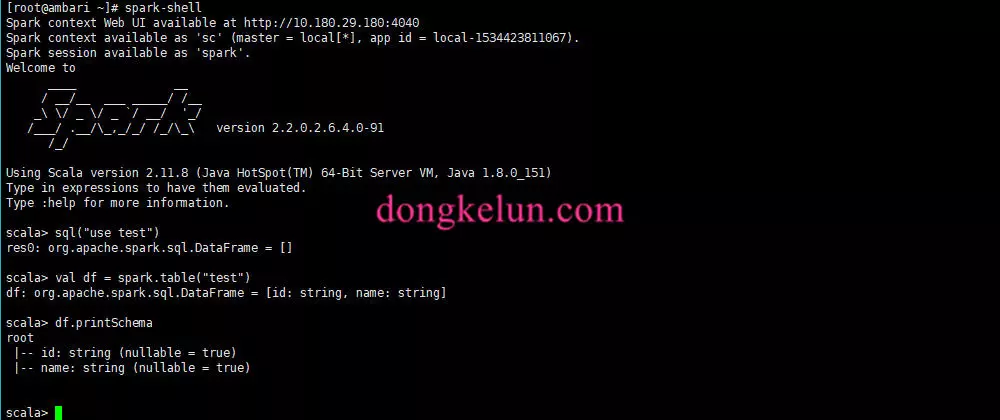
2.2 Spark读取hive表并打印注释(在spark-shell里执行)
首先看一下df.printSchema里并没有注释信息
sql("use test")
val df = spark.table("test")
df.printSchema
root
|-- id: string (nullable = true)
|-- name: string (nullable = true)
用下面这行代码便可以打印注释信息:
df.schema.foreach(s=>println(s.name,s.metadata))
(id,{"comment":"ID","HIVE_TYPE_STRING":"string"})
(name,{"comment":"名字","HIVE_TYPE_STRING":"string"})

3、读取Oracle表并打印DataFrmae的元数据信息
3.1 新建Oracle测试表(带注释)
CREATE TABLE ORA_TEST (
ID VARCHAR2(),
NAME VARCHAR2()
);
COMMENT ON COLUMN ORA_TEST.ID IS 'ID';
COMMENT ON COLUMN ORA_TEST.NAME IS '名字';
COMMENT ON TABLE ORA_TEST IS '测试';
- 注:上面的注释语句和建表语句需要分开执行,或者也可以在数据库工具执行脚本,比如我用的DBeaver用快捷键Alt+x即可。当然也可以在工具的界面直接建表均可。

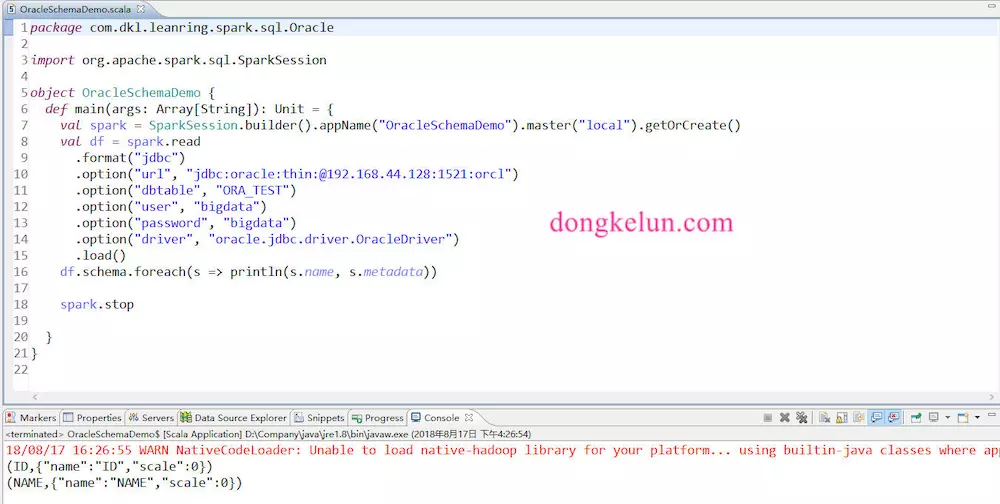
3.2 读取Oracle表,并打印元数据
代码:
package com.dkl.leanring.spark.sql.Oracle
import org.apache.spark.sql.SparkSession
object OracleSchemaDemo {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("OracleSchemaDemo").master("local").getOrCreate()
val df = spark.read
.format("jdbc")
.option("url", "jdbc:oracle:thin:@192.168.44.128:1521:orcl")
.option("dbtable", "ORA_TEST")
.option("user", "bigdata")
.option("password", "bigdata")
.option("driver", "oracle.jdbc.driver.OracleDriver")
.load()
df.schema.foreach(s => println(s.name, s.metadata))
spark.stop
}
}
(ID,{"name":"ID","scale":})
(NAME,{"name":"NAME","scale":})
注:Spark2.3.0和Spark2.2.1的元数据不太一样,上面的结果是Spark2.2.1(也是我写博客测试用的),项目中用的Spark2.3.0,2.3.0的元数据是空的,如下
(ID,{})
(NAME,{})
可见并没有注释信息
3.3 给DataFrame添加注释
import org.apache.spark.sql.types._
val commentMap = Map("ID" -> "ID", "NAME" -> "名字") val schema = df.schema.map(s => {
s.withComment(commentMap(s.name))
}) //根据添加了注释的schema,新建DataFrame
val new_df = spark.createDataFrame(df.rdd, StructType(schema)).repartition() new_df.schema.foreach(s => println(s.name, s.metadata))
(ID,{"comment":"ID","name":"ID","scale":})
(NAME,{"comment":"名字","name":"NAME","scale":})

4、 测试写到Hive表有没有注释
需将前面代码中的spark改为支持hive,即加上enableHiveSupport()
spark.sql("use test")
new_df.write.mode("overwrite").saveAsTable("ORA_TEST")
然后在hive里看一下,是否有注释

可以看到,成功的把注释也保存到里hive里
5、附录
附上在Eclipse运行的完整代码
package com.dkl.leanring.spark.sql.Oracle import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.types._ object OracleSchemaDemo {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("OracleSchemaDemo").master("local").enableHiveSupport().getOrCreate()
val df = spark.read
.format("jdbc")
.option("url", "jdbc:oracle:thin:@192.168.44.128:1521:orcl")
.option("dbtable", "ORA_TEST")
.option("user", "bigdata")
.option("password", "bigdata")
.option("driver", "oracle.jdbc.driver.OracleDriver")
.load()
df.schema.foreach(s => println(s.name, s.metadata)) val commentMap = Map("ID" -> "ID", "NAME" -> "名字") val schema = df.schema.map(s => {
s.withComment(commentMap(s.name))
}) //根据添加了注释的schema,新建DataFrame
val new_df = spark.createDataFrame(df.rdd, StructType(schema)).repartition() new_df.schema.foreach(s => println(s.name, s.metadata)) spark.sql("use test")
//保存到hive
new_df.write.mode("overwrite").saveAsTable("ORA_TEST") spark.stop }
}
Spark通过修改DataFrame的schema给表字段添加注释(转载)的更多相关文章
- mysql 数据库 表字段添加表情兼容
项目中的几个需要支持Emoji表情符号,手机自带的表情,其实添加也很简单: 1 修改数据库 配置my.cnf init-connect='SET NAMES utf8mb4' ...
- oracle 表字段添加 修改 删除语法
修改列名 alter table 表明 rename column rename 老列名 to 新列名添加 字段alter table 表名 add(字段名 类型):删除字段alter table 表 ...
- PowerDesigner15.1给自定义架构表字段添加MS_Description出错
原因:系统函数sp_addextendedproperty 的第3个参数(用户名) 应该是Schema.但PD在生成的时候却是’user’ 解决方法 在PDM时.DataBase >> E ...
- Maven插件mybatis-generator,如何让生成的PO类的field上有对应表字段的注释
前言 去年刚入职的时候,我就发现,po类(和数据库表对应的类)上,一片都是光秃秃的,什么注释都没有,类上没注释,field上也没注释. 在以前的项目中,其实我们都是有生成注释的,比如,对于下面这个表: ...
- @MySQL为表字段添加索引
删除索引~ DROP INDEX `idx_dict_type` ON `article` 1.添加PRIMARY KEY(主键索引): ALTER TABLE `table_name` ADD PR ...
- Mysql如何为表字段添加索引???
1.添加PRIMARY KEY(主键索引): ALTER TABLE `table_name` ADD PRIMARY KEY ( `column` ) 2.添加UNIQUE(唯一索引) : ALTE ...
- Mysql优化-为表字段添加索引
1.添加PRIMARY KEY(主键索引): ALTER TABLE `table_name` ADD PRIMARY KEY ( `column` ) 2.添加UNIQUE(唯一索引) : ALTE ...
- ORACLE修改表字段顺序
1.若'GYZL_BZPWL_TB' 为要修改的表名,注意表名一定要大写!此句可以获取表的id.select object_id from all_objects where object_name= ...
- oracle查看表名称和表字段注释
--查询该表字段的注释select * from user_col_comments where Table_Name like '%SMS%' --查询类似表select * from user_t ...
随机推荐
- 过采样中用到的SMOTE算法
平时很多分类问题都会面对样本不均衡的问题,很多算法在这种情况下分类效果都不够理想.类不平衡(class-imbalance)是指在训练分类器中所使用的训练集的类别分布不均.比如说一个二分类问题,100 ...
- 32位JVM和64位JVM的最大堆内存分别是多数?32位和64位的JVM,int类型变量的长度是多数?
理论上说上 32 位的 JVM 堆内存可以到达 2^32,即 4GB,但实际上会比这个小很多.不同操作系统之间不同,如 Windows 系统大约 1.5 GB,Solaris 大约 3GB.64 位 ...
- nginx配置文件服务器 linux
一,安装nginx服务器 点击打开链接 二,配置nginx服务器 ##测试配置文件 sudo /usr/sbin/nginx -t ##修改配置文件 ##1. 在nginx文件 ...
- eclipse 安装反编译工具
jd-gui是我最喜欢使用的java反编译工具.它是一款用c++开发的轻量级的java反编译工具,无须安装即可以使用,你甚至都不需要安装jre环境就可以实现反编译:支持最新的jdk,目前是jdk 1. ...
- commons-dbutils 字段名称转换,支持驼峰字段名
你能遇到的问题,只要是普遍存在的,大家都会遇到,那么,就一定有现成的解决方案. 在阅读 commons-dbutils 的文档时, BeanHandler 的第二个参数可以达到这个目的.只需传入一个实 ...
- Linux 命令 ipcs/ipcrm
ipcs 1. 命令格式 ipcs [resource-option] [output-format] ipcs [resource-option] -i id 2. 命令功能 提供IPC设备的信息 ...
- 一个 Object.assign 的误解
mozilla中对 Object.assign 的解释如下地址: mozilla 其中有说到 注意, Object.assign 会跳过那些值为 null 或 undefined 的源对象. 一直以为 ...
- GoCN每日新闻(2019-09-27)
1. Golang新版本发布:Go 1.13.1和Go 1.12.10https://golang.org/dl/ 2. 如何在Golang中使用Websockets:最佳工具和步骤指南 https: ...
- Hadoop 压缩
压缩的好处 文件压缩的好处:减少文件存储锁需要的磁盘空间,加速数据在网络和磁盘上的传输. 常见的压缩格式 压缩格式 工具 算法 文件扩展名 是否可以切分 DELATE 无 DEFLATE .d ...
- VsCode插件与Node.js交互通信
首先关于VsCode插件通信,如果不明白的可以参考我的这篇博客VsCode插件开发之插件初步通信 如果需要详细例子的话,可以参考VsCode插件开发 现在又有一个新的需求是,VsCode插件可以通过j ...