[LeetCode] 882. Reachable Nodes In Subdivided Graph 细分图中的可到达结点
Starting with an undirected graph (the "original graph") with nodes from `0` to `N-1`, subdivisions are made to some of the edges.
The graph is given as follows: edges[k] is a list of integer pairs (i, j, n) such that (i, j) is an edge of the original graph,
and n is the total number of new nodes on that edge.
Then, the edge (i, j) is deleted from the original graph, n new nodes (x_1, x_2, ..., x_n) are added to the original graph,
and n+1 new edges (i, x_1), (x_1, x_2), (x_2, x_3), ..., (x_{n-1}, x_n), (x_n, j) are added to the original graph.
Now, you start at node 0 from the original graph, and in each move, you travel along one edge.
Return how many nodes you can reach in at most Mmoves.
Example 1:
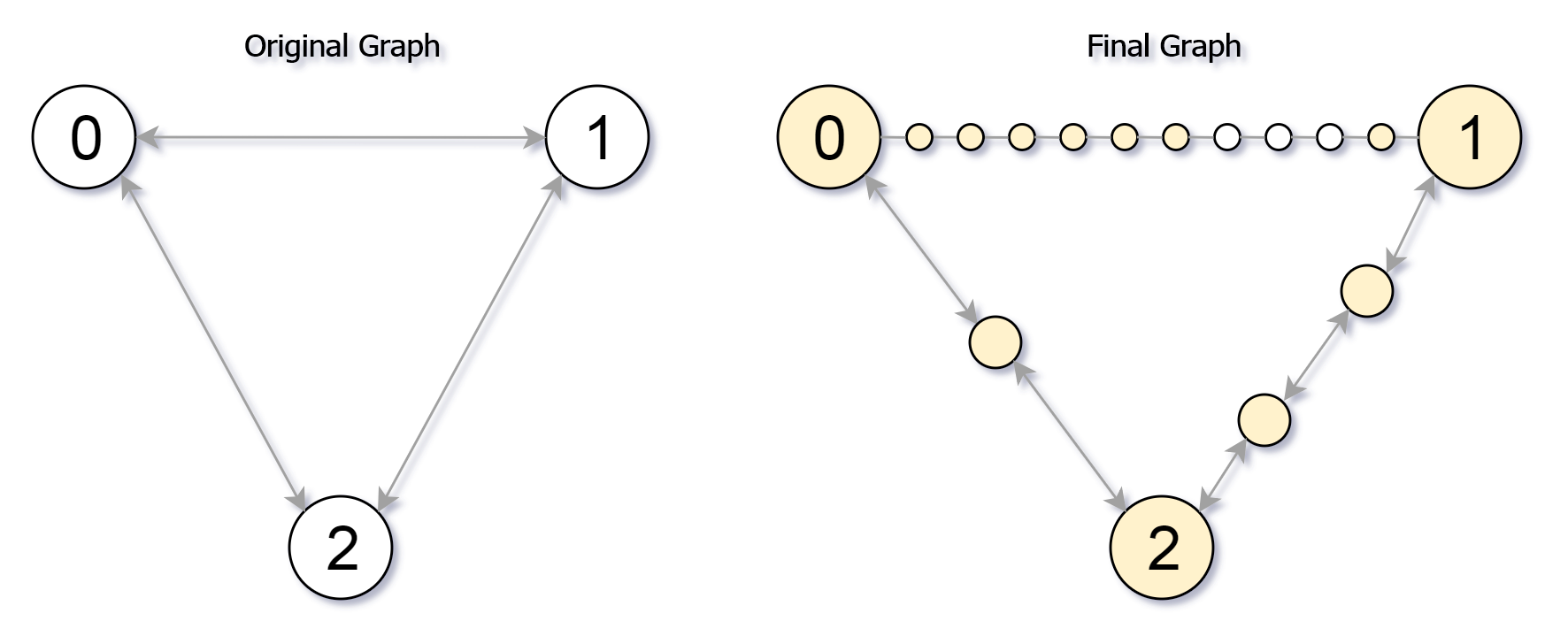
Input: `edges` = [[0,1,10],[0,2,1],[1,2,2]], M = 6, N = 3
Output: 13
Explanation:
The nodes that are reachable in the final graph after M = 6 moves are indicated below.
Example 2:
Input: `edges` = [[0,1,4],[1,2,6],[0,2,8],[1,3,1]], M = 10, N = 4
Output: 23
Note:
0 <= edges.length <= 100000 <= edges[i][0] < edges[i][1] < N- There does not exist any
i != jfor whichedges[i][0] == edges[j][0]andedges[i][1] == edges[j][1]. - The original graph has no parallel edges.
0 <= edges[i][2] <= 100000 <= M <= 10^91 <= N <= 3000- A reachable node is a node that can be travelled to using at most M moves starting from node 0.
这道题给了我们一个无向图,里面有N个结点,但是每两个结点中间可能有多个不同的结点,假设每到达下一个相邻的结点需要消耗一步,现在我们有M步可以走,问我们在M步内最多可以到达多少个不同的结点。这里虽然有N个有编号的大结点,中间还有若干个没有编号的小结点,但是最后在统计的时候不分大小结点,全都算不同的结点。为了更好的理解这道题,实际上可以把N个有编号的结点当作N个大城市,比如省会城市,每两个省会城市中间有多个小城市,假设我们每次坐飞机只能飞到相邻的下一个城市,现在我们最多能坐M次飞机,问从省会大城市0出发的话,最多能到达多少个城市。由于省会城市是大型中转站,所以只有在这里才能有多个选择去往不同的城市,而在两个省会城市中的每个小城市,只有前后两种选择,所以这道题实际上还是一种图的遍历,只不过不保证每次都能到有编号的结点,只有到达了有编号的结点,才可以继续遍历下去。当到达了有编号的结点时,还要计算此时的剩余步数,就是用前一个有编号结点的剩余步数,减去当前路径上的所有小结点的个数。假如当前的剩余步数不够到达下一个大结点时,此时我们要想办法标记出来我们走过了多少个小结点,不然下次我们通过另一条路径到达相同的下一个大结点时,再往回走就有可能重复统计小结点的个数。由于小结点并没有标号,没法直接标记,只能通过离最近的大结点的个数来标记,所以虽然这道题是一道无向图的题,但是我们需要将其当作有向图来处理,比如两个大结点A和B,中间有10个小结点,此时在A结点时只有6步能走,那么我们走了中间的6个结点,此时就要标记从B出发往A方向的话只有4个小结点能走了。
再进一步来分析,其实上对于每个结点来说(不论有没有编号),若我们能算出该结点离起始结点的最短距离,且该距离小于等于M的话,那这个结点就一定可以到达。这样来说,其实本质就是求单源点的最短距离,此时就要祭出神器迪杰斯特拉算法 Dijkstra Algorithm 了,LeetCode 中使用了该算法的题目还有 Network Delay Time 和 The Maze II。该算法的一般形式是用一个最小堆来保存到源点的最小距离,这里我们直接统计到源点的最小距离不是很方便,可以使用一个小 trick,即用一个最大堆来统计当前结点所剩的最大步数,因为剩的步数越多,说明距离源点距离越小。由于 Dijkstra 算法是以起点为中心,向外层层扩展,直到扩展到终点为止。根据这特性,用 BFS 来实现时再好不过了,首先来建立邻接链表,这里可以使用一个 NxN 的二维数组 graph,其中 graph[i][j] 表示从大结点i往大结点j方向会经过的小结点个数,建立邻接链表的时候对于每个 edge,要把两个方向都赋值,前面解释过了这里要当作有向图来做。然后使用一个最大堆,里面放剩余步数和结点编号组成的数对儿,把剩余步数放前面就可以默认按步数从大到小排序了,初始化时把 {M,0} 存入最大堆。还需要一个一维数组 visited 来记录某个结点是否访问过。在 while 循环中,首先取出堆顶元素数对儿,分别取出步数 move,和当前结点编号 cur,此时检查若该结点已经访问过了,直接跳过,否则就在 visited 数组中标记为 true。此时结果 res 自增1,因为当前大结点也是新遍历到的,需要累加个数。然后我们需要遍历所有跟 cur 相连的大结点,对于二维数组形式的邻接链表,我们只需要将i从0遍历到N,假如 graph[cur][i] 为 -1,表示结点 cur 和结点i不相连,直接跳过。否则相连的话,两个大结点中小结点的个数为 graph[cur][i],此时要跟当前 cur 结点时剩余步数 move 比较,假如 move 较大,说明可以到达结点i,将此时到达结点i的剩余步数 move-graph[cur][i]-1(最后的减1是到达结点i需要的额外步数)和i一起组成数对儿,加入最大堆中。由于之前的分析,结点 cur 往结点i走过的所有结点,从结点i就不能再往结点 cur 走了,否则就累加了重复结点,所以 graph[i][cur] 要减去 move 和 graph[cur][i] 中的较小值,同时结果 res 要累加该较小值即可,参见代码如下:
解法一:
class Solution {
public:
int reachableNodes(vector<vector<int>>& edges, int M, int N) {
int res = 0;
vector<vector<int>> graph(N, vector<int>(N, -1));
vector<bool> visited(N);
priority_queue<pair<int, int>> pq;
pq.push({M, 0});
for (auto &edge : edges) {
graph[edge[0]][edge[1]] = edge[2];
graph[edge[1]][edge[0]] = edge[2];
}
while (!pq.empty()) {
auto t= pq.top(); pq.pop();
int move = t.first, cur = t.second;
if (visited[cur]) continue;
visited[cur] = true;
++res;
for (int i = 0; i < N; ++i) {
if (graph[cur][i] == -1) continue;
if (move > graph[cur][i] && !visited[i]) {
pq.push({move - graph[cur][i] - 1, i});
}
graph[i][cur] -= min(move, graph[cur][i]);
res += min(move, graph[cur][i]);
}
}
return res;
}
};
我们也可以使用 HashMap 来建立邻接链表,最后的运行速度果然要比二维数组形式的邻接链表要快一些,其他的地方都不变,参见代码如下:
解法二:
class Solution {
public:
int reachableNodes(vector<vector<int>>& edges, int M, int N) {
int res = 0;
unordered_map<int, unordered_map<int, int>> graph;
vector<bool> visited(N);
priority_queue<pair<int, int>> pq;
pq.push({M, 0});
for (auto &edge : edges) {
graph[edge[0]][edge[1]] = edge[2];
graph[edge[1]][edge[0]] = edge[2];
}
while (!pq.empty()) {
auto t= pq.top(); pq.pop();
int move = t.first, cur = t.second;
if (visited[cur]) continue;
visited[cur] = true;
++res;
for (auto &a : graph[cur]) {
if (move > a.second && !visited[a.first]) {
pq.push({move - a.second - 1, a.first});
}
graph[a.first][cur] -= min(move, a.second);
res += min(move, a.second);
}
}
return res;
}
};
Github 同步地址:
https://github.com/grandyang/leetcode/issues/882
参考资料:
https://leetcode.com/problems/reachable-nodes-in-subdivided-graph/
[LeetCode All in One 题目讲解汇总(持续更新中...)](https://www.cnblogs.com/grandyang/p/4606334.html)
[LeetCode] 882. Reachable Nodes In Subdivided Graph 细分图中的可到达结点的更多相关文章
- [Swift]LeetCode882. 细分图中的可到达结点 | Reachable Nodes In Subdivided Graph
Starting with an undirected graph (the "original graph") with nodes from 0 to N-1, subdivi ...
- 882. Reachable Nodes In Subdivided Graph
题目链接 https://leetcode.com/contest/weekly-contest-96/problems/reachable-nodes-in-subdivided-graph/ 解题 ...
- [LeetCode] Second Minimum Node In a Binary Tree 二叉树中第二小的结点
Given a non-empty special binary tree consisting of nodes with the non-negative value, where each no ...
- LR网页细分图中的时间详解
Web Page Diagnostics: 1)DNS Resolution:浏览器访问一个网站的时候,一般用的是域名,需要dns服务器把这个域名解析为IP,这个过程就是域名解析时间,如果我们在局域网 ...
- LeetCode 24. Swap Nodes in Pairs(交换链表中每两个相邻节点)
题意:交换链表中每两个相邻节点,不能修改节点的val值. 分析:递归.如果以第三个结点为头结点的链表已经两两交换完毕(这一步递归实现---swapPairs(head -> next -> ...
- [LintCode] Swap Two Nodes in Linked List 交换链表中的两个结点
Given a linked list and two values v1 and v2. Swap the two nodes in the linked list with values v1 a ...
- hdu4587 Two Nodes 求图中删除两个结点剩余的连通分量的数量
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=4587 题目给了12000ms,对于tarjan这种O(|V|+|E|)复杂度的算法来说,暴力是能狗住的 ...
- Leetcode 25. Reverse Nodes in k-Group 以每组k个结点进行链表反转(链表)
Leetcode 25. Reverse Nodes in k-Group 以每组k个结点进行链表反转(链表) 题目描述 已知一个链表,每次对k个节点进行反转,最后返回反转后的链表 测试样例 Inpu ...
- [LeetCode] 25. Reverse Nodes in k-Group 每k个一组翻转链表
Given a linked list, reverse the nodes of a linked list k at a time and return its modified list. k ...
随机推荐
- 【Java面试题】short s1 = 1; s1 = s1 + 1;有错吗?short s1 = 1; s1 += 1;有错吗?
昨天去面试,虽然体验不是很好, 但是看到了这个面试题,当时感觉无从下手,所以在这里记录一下. 解决这道题之前,先复习一下Java的基本数据类型转换规则,以便后面对面试题的理解. java的基本数据类型 ...
- Disruptor系列(一)— disruptor介绍
本文翻译自Disruptor在github上的wiki文章Introduction,原文可以看这里. 一.前言 作为程序猿大多数都有对技术的执着,想在这个方面有所提升.对于优秀的事物保持积极学习的心态 ...
- [IDA] Oops! internal error 40343 occured.
问题描述: 解决方案: 安装 IDA 时,其路径下不要出现中文.
- Prometheus监控学习笔记之Prometheus如何热加载更新配置
0x00 概述 当 Prometheus 有配置文件修改,我们可以采用 Prometheus 提供的热更新方法实现在不停服务的情况下实现配置文件的重新加载. 0x01 热更新 热更新加载方法有两种: ...
- ASP.NET Core快速入门(第5章:认证与授权)--学习笔记
课程链接:http://video.jessetalk.cn/course/explore 良心课程,大家一起来学习哈! 任务31:课时介绍 1.Cookie-based认证与授权 2.Cookie- ...
- laravel Method Illuminate\Validation\Validator::validateReuqired does not exist.
Method Illuminate\Validation\Validator::validateReuqired does not exist. 此错误是由于我们在配置验证时,写错了关键字, publ ...
- Java编程基础——流程控制
Java编程基础——流程控制 摘要:本文主要介绍Java编程中的流程控制语句. 分类 流程控制指的是在程序运行的过程中控制程序运行走向的方式.主要分为以下三种: 顺序结构:从上到下依次执行每条语句操作 ...
- 智能家居-3.基于esp8266的语音控制系统(软件篇)
智能家居-1.基于esp8266的语音控制系统(开篇) 智能家居-2.基于esp8266的语音控制系统(硬件篇) 智能家居-3.基于esp8266的语音控制系统(软件篇) 赞赏支持 QQ:505645 ...
- ubuntu 18.04 修改Apache默认目录
ubuntu 18.04 修改Apache默认目录 安装是直接运行 sudu apt install apache2 安装之后要修改目录 vi /etc/apache2/sites-available ...
- 一文带你了解JavaScript函数式编程
摘要: 函数式编程入门. 作者:浪里行舟 Fundebug经授权转载,版权归原作者所有. 前言 函数式编程在前端已经成为了一个非常热门的话题.在最近几年里,我们看到非常多的应用程序代码库里大量使用着函 ...