从图(Graph)到图卷积(Graph Convolution):漫谈图神经网络模型 (三)
本文属于图神经网络的系列文章,文章目录如下:
- 从图(Graph)到图卷积(Graph Convolution):漫谈图神经网络模型 (一)
- 从图(Graph)到图卷积(Graph Convolution):漫谈图神经网络模型 (二)
- 从图(Graph)到图卷积(Graph Convolution):漫谈图神经网络模型 (三)
恭喜你看到了本系列的第三篇!前面两篇博客分别介绍了基于循环的图神经网络和基于卷积的图神经网络,那么在本篇中,我们则主要关注在得到了各个结点的表示后,如何生成整个图的表示。其实之前我们也举了一些例子,比如最朴素的方法,例如图上所有结点的表示取个均值,即可得到图的表示。那有没有更好的方法呢,它们各自的优点和缺点又是什么呢,本篇主要对上面这两个问题做一点探讨。篇幅不多,理论也不艰深,请读者放心地看。
图读出操作(ReadOut)
图读出操作,顾名思义,就是用来生成图表示的。它的别名有图粗化(翻译捉急,Graph Coarsening)/图池化(Graph Pooling)。对于这种操作而言,它的核心要义在于:操作本身要对结点顺序不敏感。
这是为什么呢?这就不得不提到图本身的一些性质了。我们都知道,在欧氏空间中,如果一张图片旋转了,那么形成的新图片就不再是原来那张图片了;但在非欧式空间的图上,如果一个图旋转一下,例如对它的结点重新编号,这样形成的图与原先的图其实是一个。这就是典型的图重构(Graph Isomorphism)问题。比如下面左右两个图,其实是等价的:
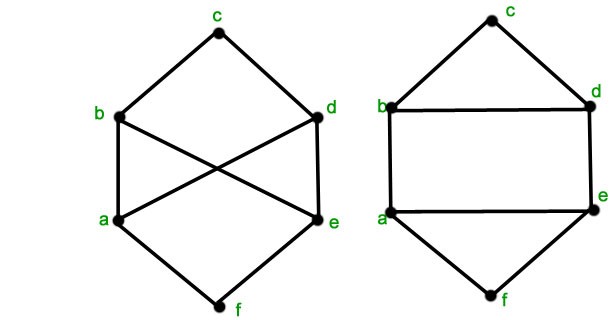
为了使得同构图的表示能够保持一致,图读出的操作就需要对结点顺序不敏感。在数学上,能表达这种操作的函数也被称为对称函数。
那么我们一般如何实现图读出操作呢?笔者接下来主要介绍两种方法:基于统计的方法 与 基于学习的方法。
基于统计的方法(Statistics Category)
基于统计的方法应该是最常见的,比如说我们在求各种抽象表示所使用的 平均(mean),求和(sum),取最大(max) 等操作。这些方法简单有效,又不会带来额外的模型参数。但同时我们必须承认,这些方法的信息损失太大。假设一个图里有 1000个结点,每个结点的表示是 100维;整张图本可表达 1000 * 100 的特征,这些简单的统计函数却直接将信息量直接压缩到了100维。尤其是,在这个过程中,每一维上数据的分布特性被完全抹除。
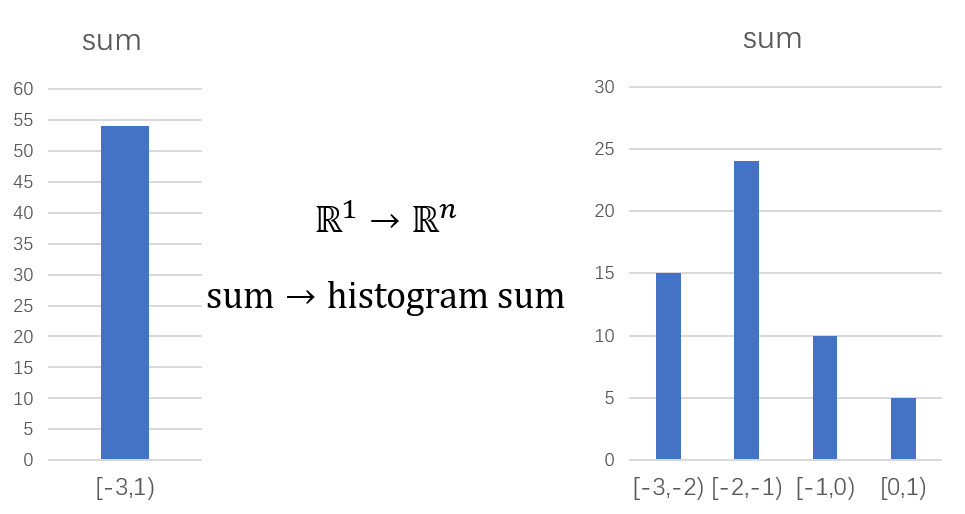
考虑到这一点,文献[1]的作者就提出要用类似直方图的方法来对每维数据分布进行建模。具体而言,请读者先通过下面的对比图来直观感受一下直方图是如何巧妙平衡数据信息的压缩与增强的。假设我们有100个介于[-3,1]的数字,如果我们直接将它们求和,如左图所示,我们完全看不出这100个数据的分布;而如果我们将[-3, 1]等分成4个区域,比如说就是[-3,-2),[-2,-1),[-1,0) 和 [0,1)。我们分开统计各个区域的和,可以发现一点原数据的分布特征,就如下右侧子图所示:
如果要实现上面这个直方图的做法,该如何做呢?其实也很简单,我们举个例子。给定3个数据点,它们的特征向量(2维)分别是[-2, 1], [-1, 2] 和 [-1, 1]。如果直接求和,全局的特征向量是 [-2+-1+-1, 1+2+1] 即 [-4,4]。如果采取上述直方图的方式,则可能会得到一个这样的全局特征向量[-2, -1 + -1, 1 + 1, 2](第1,2维代表从原先的第1维统计的直方图,对应的区域为[-2,1),[1,2),第3,4维的含义类似)。但在实践中,文献[1]没有直接利用这种方法,而是采用高斯函数来实现名为模糊直方图(Fuzzy Histogram)的操作。
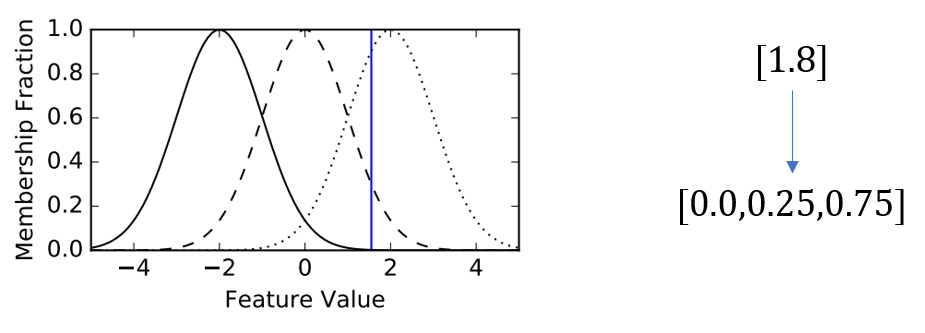
模糊直方图的原理也很简单:预先定义几个特征值区域的边界点为各个高斯分布的均值,并预设好方差。对任一特征值,根据其与各个高斯分布交点的纵坐标作为其落入该区域的数值,然后将所有数值归一化,就得到了该特征值分布在各个区间的比例。举个例子,图上的[1.8]与三个高斯分布的交点分别在0,0.3,0.9处,归一化一下,即可知该特征值最终应该用一个3维向量[0.0, 0.25, 0.75]来表示。
基于学习的方法(Learning Category)
基于统计的方法的一个坏处大概是它没办法参数化,间接地难以表示结点到图向量的这个“复杂”过程。基于学习的方法就是希望用神经网络来拟合这个过程。
采样加全连接(Sample And FC)
最简单又最直接的做法,大概就是取固定数量的结点,通过一个全连接层(Fully Connected Layer)得到图的表示。这里不论是随机采样也好,还是根据某些规则采样,都需要得到确定数量的结点,如果不够就做填充。公式也很简单直接(\(\textbf{H}^
从图(Graph)到图卷积(Graph Convolution):漫谈图神经网络模型 (三)的更多相关文章
- 从图(Graph)到图卷积(Graph Convolution):漫谈图神经网络模型 (二)
本文属于图神经网络的系列文章,文章目录如下: 从图(Graph)到图卷积(Graph Convolution):漫谈图神经网络模型 (一) 从图(Graph)到图卷积(Graph Convolutio ...
- 从图(Graph)到图卷积(Graph Convolution):漫谈图神经网络模型 (一)
本文属于图神经网络的系列文章,文章目录如下: 从图(Graph)到图卷积(Graph Convolution):漫谈图神经网络模型 (一) 从图(Graph)到图卷积(Graph Convolutio ...
- 【GCN】图卷积网络初探——基于图(Graph)的傅里叶变换和卷积
[GCN]图卷积网络初探——基于图(Graph)的傅里叶变换和卷积 2018年11月29日 11:50:38 夏至夏至520 阅读数 5980更多 分类专栏: # MachineLearning ...
- [LeetCode]Copy List with Random Pointer &Clone Graph 复杂链表的复制&图的复制
/** * Definition for singly-linked list with a random pointer. * struct RandomListNode { * int label ...
- Nebula Graph 技术总监陈恒:图数据库怎么和深度学习框架进行结合?
引子 Nebula Graph 的技术总监在 09.24 - 09.30 期间同开源中国·高手问答的小伙伴们以「图数据库的设计和实践」为切入点展开讨论,包括:「图数据库的存储设计」.「图数据库的计算设 ...
- python生成组织架构图(网络拓扑图、graph.editor拓扑图编辑器)
Graph.Editor是一款基于HTML5技术的拓补图编辑器,采用jquery插件的形式,是Qunee图形组件的扩展项目,旨在提供可供扩展的拓扑图编辑工具, 拓扑图展示.编辑.导出.保存等功能,此外 ...
- CF1082G:G. Petya and Graph(裸的最大闭合权图)
Petya has a simple graph (that is, a graph without loops or multiple edges) consisting of n n vertic ...
- 论文解读(GMT)《Accurate Learning of Graph Representations with Graph Multiset Pooling》
论文信息 论文标题:Accurate Learning of Graph Representations with Graph Multiset Pooling论文作者:Jinheon Baek, M ...
- 各种卷积类型Convolution
从最开始的卷积层,发展至今,卷积已不再是当初的卷积,而是一个研究方向.在反卷积这篇博客中,介绍了一些常见的卷积的关系,本篇博客就是要梳理这些有趣的卷积结构. 阅读本篇博客之前,建议将这篇博客结合在一起 ...
随机推荐
- 【01】Nginx:编译安装/动态添加模块
写在前面的话 说起 Nginx,别说运维,就是很多开发人员也很熟悉,毕竟如今已经 2019 年了,Apache 更多的要么成为了历史,要么成为了历史残留. 我们在提及 Nginx 的时候,一直在强调他 ...
- Zabbix设置自定义监控项之——监控tcp连接状态
目录 一.用户自定义参数 二.配置 监控 TCP 连接状态 在实际监控中,除了官方自带的一些监控项,我们很多时候有一些定制化监控,比如特定的服务.TCP 连接状态等等,这时候就需要自定义监控项.自定义 ...
- C# 使用Environment获取当前程序运行环境相关信息
Enviroment类和AppDomain类前者表示系统级的相关信息,后者表示应用程序级的相关信息. 我常用这两个类获取一些程序运行目录.操作系统位数等信息: string basedir = App ...
- jvm常用排错命令
jvm命令很多,有一篇博客整理的非常全 https://www.cnblogs.com/ityouknow/p/5714703.html.我只列举一些常用的排错用到的. jps -l -v ...
- Lucene BooleanQuery相关算法
BooleanQuery对两种不同查询场景执行不同的算法: 场景1: 所有的子句都必须满足,而且所有的子句里没有嵌套BooleanQuery. 例: a AND b AND c 上面语句表示要同时包含 ...
- curl sftp libcurl 功能使用
#include <curl/curl.h> #undef DISABLE_SSH_AGENT struct FtpFile { const char *filename; FILE *s ...
- VMware基本用法
###VMware tools 介绍 只有在VMware虚拟机中安装好了VMware Tools,才能实现主机与虚拟机之间的文件共享,同时可支持自由拖拽的功能,鼠标也可在虚拟机与主机之前自由移动(不用 ...
- LeetCode——Rank Scores
Write a SQL query to rank scores. If there is a tie between two scores, both should have the same ra ...
- XGBoost 完整推导过程
参考: 陈天奇-"XGBoost: A Scalable Tree Boosting System" Paper地址: <https://arxiv.org/abs/1603 ...
- 3-2-Pandas 索引
Pandas章节应用的数据可以在以下链接下载: https://files.cnblogs.com/files/AI-robort/Titanic_Data-master.zip In [4]: i ...