大数据学习之Hadoop环境搭建
一、Hadoop的优势
1)高可靠性:因为Hadoop假设计算元素和存储会出现故障,因为它维护多个工作数据副本,在出现故障时可以对失败的节点重新分布处理。
2)高扩展性:在集群间分配任务数据,可方便的扩展数以千计的节点。
3) 高效性:在MapReduce的思想下,Hadoop是并行工作的,以加快任务处理速度。
4)高容错性:自动保存多份副本数据,并且能够自动将失败的任务重新分配。
二、Hadoop组成
1)Hadoop HDFS:一个高可靠、高吞吐量的分布式文件系统。
2)Hadoop MapReduce:一个分布式的离线并行计算框架。
3)Hadoop YARN:作业调度与集群资源管理的框架。
4)Hadoop Common:支持其他模块的工具模块。
2.1 HDFS(Hadoop Distributed File System)架构概述
1)NameNode(nn):存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等。
2)DataNode(dn):在本地文件系统存储文件块数据,以及块数据的校验和。
3)Secondary NameNode(2nn):用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据的快照。
2.2 YARN架构概述
1)ResourceManager(rm):处理客户端请求、启动/监控ApplicationMaster、监控NodeManager、资源分配与调度;
2)NodeManager(nm):单个节点上的资源管理、处理来自ResourceManager的命令、处理来自ApplicationMaster的命令;
3)ApplicationMaster:数据切分、为应用程序申请资源,并分配给内部任务、任务监控与容错。
4)Container:对任务运行环境的抽象,封装了CPU、内存等多维资源以及环境变量、启动命令等任务运行相关的信息。
2.3 MapReduce架构概述
MapReduce将计算过程分为两个阶段:Map和Reduce
1)Map阶段并行处理输入数据
2)Reduce阶段对Map结果进行汇总
三、Hadoop环境搭建
1 虚拟机网络模式设置为NAT

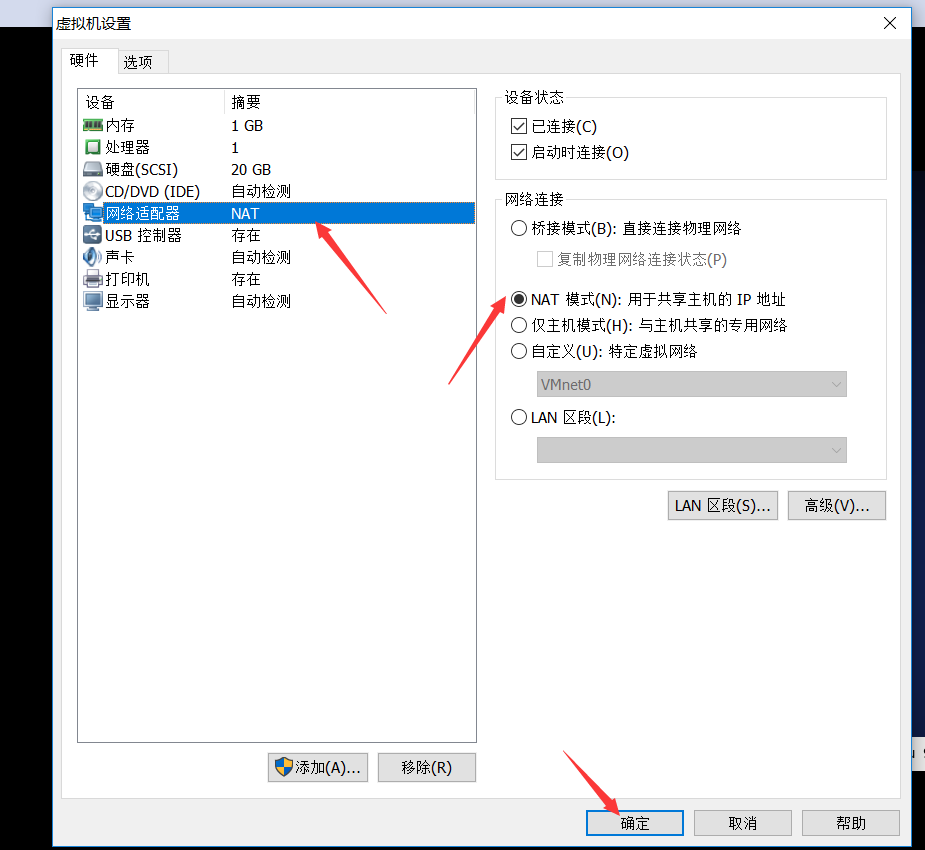
最后,重新启动系统。
2.修改为静态ip
1)使用命令 vim /etc/sysconfig/network-scripts/ifcfg-eth0
2)修改选项有五项:
IPADDR=192.168.110.61
GATEWAY=192.168.110.2
ONBOOT=yes
BOOTPROTO=static
DNS1=192.168.110.2
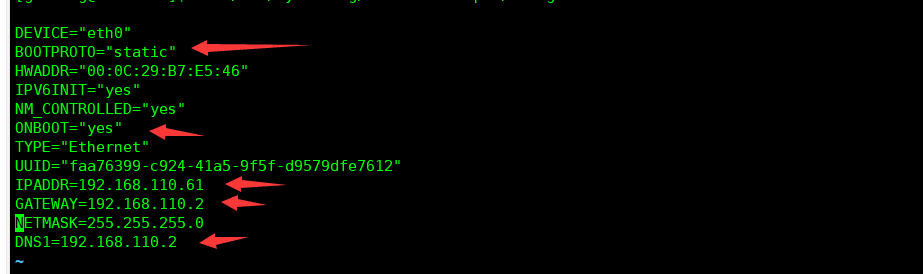
修改完成后保存退出(:wq )
3)执行service network restart
4)如果报错,reboot,重启虚拟机
3.修改主机名
1)修改linux的hosts文件
(1)进入Linux系统查看本机的主机名。通过hostname命令查看

(2)如果感觉此主机名不合适,我们可以进行修改。通过编辑/etc/sysconfig/network文件

(3)修改后保存退出
(4)编辑
vim /etc/hosts

(5)并重启设备,重启后,查看主机名,已经修改成功
4.关闭防火墙
1)查看防火墙开机启动状态
chkconfig iptables --list
2)关闭防火墙
chkconfig iptables off
5.安装jdk
1)卸载现有jdk
(1)查询安装jdk的版本:
java -version
(2)查询是否安装java软件:
rpm -qa|grep java
(3)如果安装的版本低于1.7,卸载该jdk:
rpm -e 软件包
2)用filezilla工具将jdk导入到usr目录下面的java文件夹下面
3)在linux系统下的usr目录中查看软件包是否导入成功(使用.gz包或者.rpm包,本处使用.rpm包)。

4).gz包使用命令 tar -zxf jdk***.gz 解压到当前目录; .rpm包使用命令 rpm -ivh jdk***.rpm 进行安装.
5)配置jdk环境变量
(1) 先获取jdk路径:使用命令pwd

(2)打开/etc/profile文件:
vi /etc/profile
在profie文件末尾添加jdk路径:
#set java environment
JAVA_HOME=/usr/java/jdk1.8.0_171-amd64
JRE_HOME=/usr/java/jdk1.8.0_171-amd64/jre
CLASS_PATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
export JAVA_HOME JRE_HOME CLASS_PATH PATH
(3)保存后退出:
:wq
(4)让修改后的文件生效:

6)重启(如果java –version可以用就不用重启):
7) 测试jdk安装成功

四、安装Hadoop
1)通过用filezilla工具将Hadoop导入/usr/local/src/中,官方下载地址:http://mirrors.shu.edu.cn/apache/hadoop/common/

2)解压安装文件 tar -zxf hadoop-2.7.6.tar.gz
3)配置hadoop中的hadoop-env.sh
(1)Linux系统中获取jdk的安装路径:

(2)进入 hadoop-2.7.6/etc/hadoop/中 ,修改hadoop-env.sh文件中JAVA_HOME 路径:
export JAVA_HOME=/opt/module/jdk1.7.0_79
4)将hadoop添加到环境变量
(1)获取hadoop安装路径:

(2)打开/etc/profile文件:
在profie文件末尾添加hadoop路径:
#HADOOP_HOME
export HADOOP_HOME=/usr/local/src/hadoop-2.7.6
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
(3)保存后退出:
:wq
(4)让修改后的文件生效:

(5)使用hadoop查看是否安装成功,如果hadoop命令不能使用则重启再查看。
大数据学习之Hadoop环境搭建的更多相关文章
- 大数据之路- Hadoop环境搭建(Linux)
前期部署 1.JDK 2.上传HADOOP安装包 2.1官网:http://hadoop.apache.org/ 2.2下载hadoop-2.6.1的这个tar.gz文件,官网: https://ar ...
- 大数据学习笔记——Hadoop编程实战之HDFS
HDFS基本API的应用(包含IDEA的基本设置) 在上一篇博客中,本人详细地整理了如何从0搭建一个HA模式下的分布式Hadoop平台,那么,在上一篇的基础上,我们终于可以进行编程实操了,同样,在编程 ...
- 《OD大数据实战》Hive环境搭建
一.搭建hadoop环境 <OD大数据实战>hadoop伪分布式环境搭建 二.Hive环境搭建 1. 准备安装文件 下载地址: http://archive.cloudera.com/cd ...
- 大数据学习之Hadoop快速入门
1.Hadoop生态概况 Hadoop是一个由Apache基金会所开发的分布式系统集成架构,用户可以在不了解分布式底层细节情况下,开发分布式程序,充分利用集群的威力来进行高速运算与存储,具有可靠.高效 ...
- 《OD大数据实战》Hue环境搭建
官网: http://archive.cloudera.com/cdh5/cdh/5/hue-3.7.0-cdh5.3.6/ 一.Hue环境搭建 1. 下载 http://archive.cloude ...
- 大数据学习笔记——Hadoop编程之SequenceFile
SequenceFile(Hadoop序列文件)基础知识与应用 上篇编程实战系列中本人介绍了基本的使用HDFS进行文件读写的方法,这一篇将承接上篇重点整理一下SequenceFile的相关知识及应用 ...
- 大数据学习笔记——Hadoop高可用完全分布式模式完整部署教程(包含zookeeper)
高可用模式下的Hadoop集群搭建 本篇博客将会在之前写过的Linux的完整部署的基础上进行,暂时不会涉及到伪分布式或者完全分布式模式搭建,由于HA模式涉及到的配置文件较多,维护起来也较为复杂,相信学 ...
- 《OD大数据实战》MongoDB环境搭建
一.MongonDB环境搭建 1. 下载 https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-3.0.6.tgz 2. 解压 tar -zxvf ...
- 《OD大数据实战》HBase环境搭建
一.环境搭建 1. 下载 hbase-0.98.6-cdh5.3.6.tar.gz 2. 解压 tar -zxvf hbase-0.98.6-cdh5.3.6.tar.gz -C /opt/modul ...
随机推荐
- SVNKit学习——wiki+简介(二)
这篇文章是参考SVNKit官网在wiki的文档,做了个人的理解~ 首先抛出一个疑问,Subversion是做什么的,SVNKit又是用来干什么的? 相信一般工作过的同学都用过或了解过svn,不了解的同 ...
- windows server 2003安装Oracle webtier 32位因环境变量原因报错
在服务中启动Oracle processer manager时报错:错误1053:服务没有及时响应启动或控制请求 原因是本系统还安装过BI和Oracle数据库等产品 解决方法:删除和本次安装无关的环境 ...
- ubuntu 18.4 鼠标右键菜单 添加文件
执行以下指令,在template文件夹中,增加一个空文件 touch ~/Templates/Empty\ Document
- Visual Studio中头文件stdafx.h的作用
在较新版的Visual Studio中,新生成的C++项目文件的的头文件夹下会默认有头文件stdafx.h,而源文件夹下则默认有源文件stdafx.cpp,手动将这些文件删除后,编译时系统还会报错.下 ...
- 弃坑pexpect,入坑paramiko
上文书说到,ssh库pexpect的使用,简直就是个“月亮公主”——满眼全是坑.勉强把程序写好了,跑起来的时候发现了一个新坑,让我不可抗拒的把它弃掉了——经常莫名其妙的连不上服务器!开线程连接14台服 ...
- BZOJ2160:拉拉队排练(Manacher)
Description 艾利斯顿商学院篮球队要参加一年一度的市篮球比赛了.拉拉队是篮球比赛的一个看点,好的拉拉队往往能帮助球队增加士气,赢得最终的比赛.所以作为拉拉队队长的楚雨荨同学知道,帮助篮球队训 ...
- php 日志扩展
今天发现一个比较好的php应用日志扩展,这里先mark一下,回头有空再详细介绍: http://neeke.github.io/SeasLog/
- TunSafe使用分享
体验还是很棒的,关于使用中遇到的一些问题在此分享下 官网打不开? 这个真的很不解,科学以后遇到的, 后来在手机上同样的环境测试可以打开 最后居然使用ie浏览器解决了,看来是国产浏览器在作怪 ie终于打 ...
- 【luogu P2919 [USACO08NOV]守护农场Guarding the Farm】 题解
题目链接:https://www.luogu.org/problemnew/show/P2919 1.搜索的时候分清楚全局变量和局部变量的区别 2.排序优化搜索 #include <cstdio ...
- TCP-IP Architecture and IP Packet
Why Internet working? To build a "network of networks" or internet. operating over multipl ...