大数据学习之Hadoop环境搭建
一、Hadoop的优势
1)高可靠性:因为Hadoop假设计算元素和存储会出现故障,因为它维护多个工作数据副本,在出现故障时可以对失败的节点重新分布处理。
2)高扩展性:在集群间分配任务数据,可方便的扩展数以千计的节点。
3) 高效性:在MapReduce的思想下,Hadoop是并行工作的,以加快任务处理速度。
4)高容错性:自动保存多份副本数据,并且能够自动将失败的任务重新分配。
二、Hadoop组成
1)Hadoop HDFS:一个高可靠、高吞吐量的分布式文件系统。
2)Hadoop MapReduce:一个分布式的离线并行计算框架。
3)Hadoop YARN:作业调度与集群资源管理的框架。
4)Hadoop Common:支持其他模块的工具模块。
2.1 HDFS(Hadoop Distributed File System)架构概述
1)NameNode(nn):存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等。
2)DataNode(dn):在本地文件系统存储文件块数据,以及块数据的校验和。
3)Secondary NameNode(2nn):用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据的快照。
2.2 YARN架构概述
1)ResourceManager(rm):处理客户端请求、启动/监控ApplicationMaster、监控NodeManager、资源分配与调度;
2)NodeManager(nm):单个节点上的资源管理、处理来自ResourceManager的命令、处理来自ApplicationMaster的命令;
3)ApplicationMaster:数据切分、为应用程序申请资源,并分配给内部任务、任务监控与容错。
4)Container:对任务运行环境的抽象,封装了CPU、内存等多维资源以及环境变量、启动命令等任务运行相关的信息。
2.3 MapReduce架构概述
MapReduce将计算过程分为两个阶段:Map和Reduce
1)Map阶段并行处理输入数据
2)Reduce阶段对Map结果进行汇总
三、Hadoop环境搭建
1 虚拟机网络模式设置为NAT

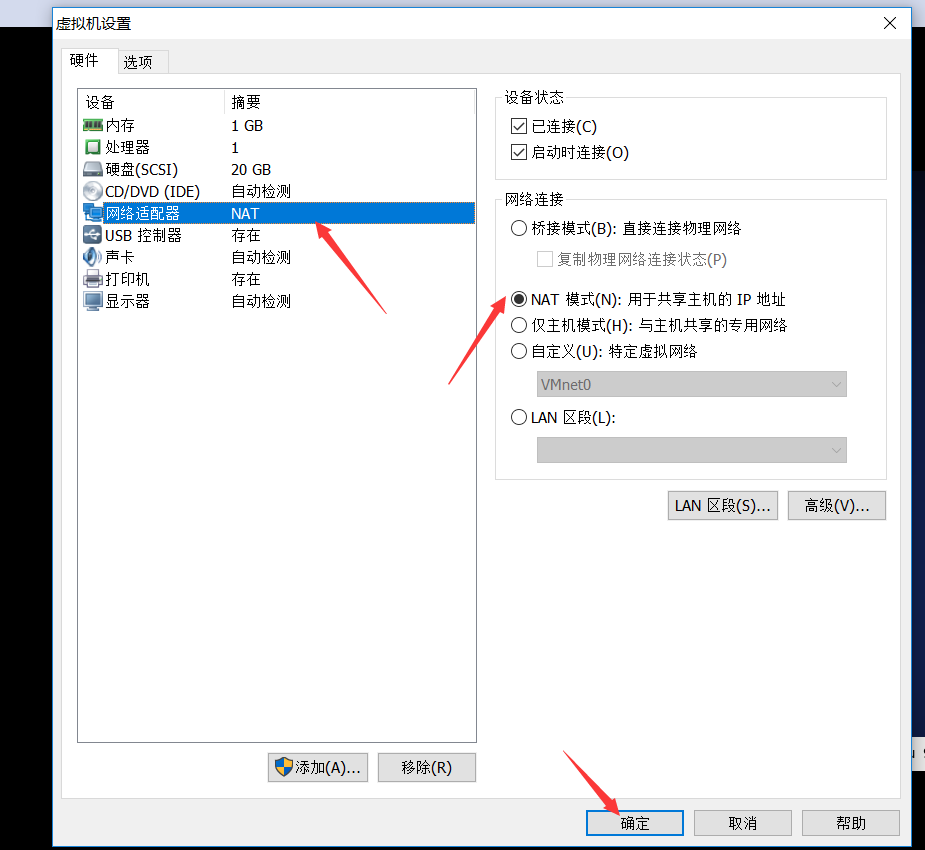
最后,重新启动系统。
2.修改为静态ip
1)使用命令 vim /etc/sysconfig/network-scripts/ifcfg-eth0
2)修改选项有五项:
IPADDR=192.168.110.61
GATEWAY=192.168.110.2
ONBOOT=yes
BOOTPROTO=static
DNS1=192.168.110.2
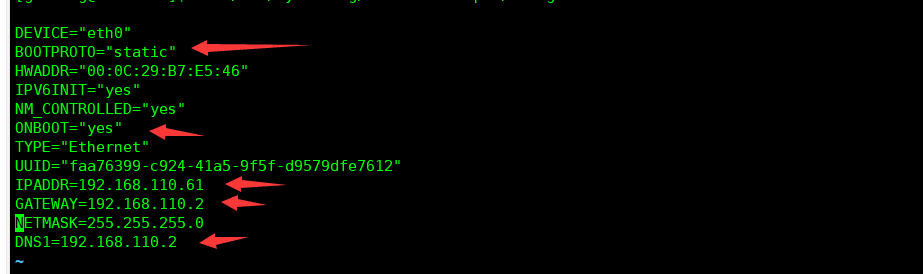
修改完成后保存退出(:wq )
3)执行service network restart
4)如果报错,reboot,重启虚拟机
3.修改主机名
1)修改linux的hosts文件
(1)进入Linux系统查看本机的主机名。通过hostname命令查看

(2)如果感觉此主机名不合适,我们可以进行修改。通过编辑/etc/sysconfig/network文件

(3)修改后保存退出
(4)编辑
vim /etc/hosts

(5)并重启设备,重启后,查看主机名,已经修改成功
4.关闭防火墙
1)查看防火墙开机启动状态
chkconfig iptables --list
2)关闭防火墙
chkconfig iptables off
5.安装jdk
1)卸载现有jdk
(1)查询安装jdk的版本:
java -version
(2)查询是否安装java软件:
rpm -qa|grep java
(3)如果安装的版本低于1.7,卸载该jdk:
rpm -e 软件包
2)用filezilla工具将jdk导入到usr目录下面的java文件夹下面
3)在linux系统下的usr目录中查看软件包是否导入成功(使用.gz包或者.rpm包,本处使用.rpm包)。

4).gz包使用命令 tar -zxf jdk***.gz 解压到当前目录; .rpm包使用命令 rpm -ivh jdk***.rpm 进行安装.
5)配置jdk环境变量
(1) 先获取jdk路径:使用命令pwd

(2)打开/etc/profile文件:
vi /etc/profile
在profie文件末尾添加jdk路径:
#set java environment
JAVA_HOME=/usr/java/jdk1.8.0_171-amd64
JRE_HOME=/usr/java/jdk1.8.0_171-amd64/jre
CLASS_PATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
export JAVA_HOME JRE_HOME CLASS_PATH PATH
(3)保存后退出:
:wq
(4)让修改后的文件生效:

6)重启(如果java –version可以用就不用重启):
7) 测试jdk安装成功

四、安装Hadoop
1)通过用filezilla工具将Hadoop导入/usr/local/src/中,官方下载地址:http://mirrors.shu.edu.cn/apache/hadoop/common/

2)解压安装文件 tar -zxf hadoop-2.7.6.tar.gz
3)配置hadoop中的hadoop-env.sh
(1)Linux系统中获取jdk的安装路径:

(2)进入 hadoop-2.7.6/etc/hadoop/中 ,修改hadoop-env.sh文件中JAVA_HOME 路径:
export JAVA_HOME=/opt/module/jdk1.7.0_79
4)将hadoop添加到环境变量
(1)获取hadoop安装路径:

(2)打开/etc/profile文件:
在profie文件末尾添加hadoop路径:
#HADOOP_HOME
export HADOOP_HOME=/usr/local/src/hadoop-2.7.6
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
(3)保存后退出:
:wq
(4)让修改后的文件生效:

(5)使用hadoop查看是否安装成功,如果hadoop命令不能使用则重启再查看。
大数据学习之Hadoop环境搭建的更多相关文章
- 大数据之路- Hadoop环境搭建(Linux)
前期部署 1.JDK 2.上传HADOOP安装包 2.1官网:http://hadoop.apache.org/ 2.2下载hadoop-2.6.1的这个tar.gz文件,官网: https://ar ...
- 大数据学习笔记——Hadoop编程实战之HDFS
HDFS基本API的应用(包含IDEA的基本设置) 在上一篇博客中,本人详细地整理了如何从0搭建一个HA模式下的分布式Hadoop平台,那么,在上一篇的基础上,我们终于可以进行编程实操了,同样,在编程 ...
- 《OD大数据实战》Hive环境搭建
一.搭建hadoop环境 <OD大数据实战>hadoop伪分布式环境搭建 二.Hive环境搭建 1. 准备安装文件 下载地址: http://archive.cloudera.com/cd ...
- 大数据学习之Hadoop快速入门
1.Hadoop生态概况 Hadoop是一个由Apache基金会所开发的分布式系统集成架构,用户可以在不了解分布式底层细节情况下,开发分布式程序,充分利用集群的威力来进行高速运算与存储,具有可靠.高效 ...
- 《OD大数据实战》Hue环境搭建
官网: http://archive.cloudera.com/cdh5/cdh/5/hue-3.7.0-cdh5.3.6/ 一.Hue环境搭建 1. 下载 http://archive.cloude ...
- 大数据学习笔记——Hadoop编程之SequenceFile
SequenceFile(Hadoop序列文件)基础知识与应用 上篇编程实战系列中本人介绍了基本的使用HDFS进行文件读写的方法,这一篇将承接上篇重点整理一下SequenceFile的相关知识及应用 ...
- 大数据学习笔记——Hadoop高可用完全分布式模式完整部署教程(包含zookeeper)
高可用模式下的Hadoop集群搭建 本篇博客将会在之前写过的Linux的完整部署的基础上进行,暂时不会涉及到伪分布式或者完全分布式模式搭建,由于HA模式涉及到的配置文件较多,维护起来也较为复杂,相信学 ...
- 《OD大数据实战》MongoDB环境搭建
一.MongonDB环境搭建 1. 下载 https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-3.0.6.tgz 2. 解压 tar -zxvf ...
- 《OD大数据实战》HBase环境搭建
一.环境搭建 1. 下载 hbase-0.98.6-cdh5.3.6.tar.gz 2. 解压 tar -zxvf hbase-0.98.6-cdh5.3.6.tar.gz -C /opt/modul ...
随机推荐
- web images
ps切图时,我们保存时会要求选择文件格式. 一般来说,如果图像的色彩丰富,没有透明度的要求,则选择为jpeg格式: 如果图像色彩不丰富,我们就选择为png-8的格式,注意:ps中要选择无杂边,无仿色 ...
- MVC中重定向几种方法
//1.Response.Redirect using System; using System.Collections.Generic; using System.Linq; using Syste ...
- Python初学者第一天 Python安装及第一个Python程序
Python基础: 1day: 1.Python基础: A.编程语言介绍: a. 计算机只能理解0和1.编程即写一段按照一定规则写代码,让计算机帮你干活: b.机器语言:最底层的语言, ...
- 图的存储结构(邻接矩阵与邻接表)及其C++实现
一.图的定义 图是由顶点的有穷非空集合和顶点之间边的集合组成,通常表示为: G=(V,E) 其中:G表示一个图,V是图G中顶点的集合,E是图G中顶点之间边的集合. 注: 在线性表中,元素个数可以为零, ...
- OID OAM WLS等Oracle 中间件日志位置汇总
WLS的log:/tip/IMP/bea/user_projects/domains/IDMDomain/servers/AdminServer/logsOID的log:/tip/IMP/bea/us ...
- Chosen三级联动
上一篇介绍了 Chosen 的使用,这篇介绍联动.看代码: var addressResolve = function (options) { //检测用户传进来的参数是否合法 if (!isVal ...
- jmeter报告优化---展示详细信息
参考文档:https://www.cnblogs.com/puresoul/p/5049433.html 楼上博主写的还是很详细,在报告优化这块,但是在操作中也走了一些弯路,我改动了两个点才成功,根据 ...
- (二)给Centos配置网络以及使用xshell远程连接Centos
好吧,我对网络协议以及ip配置知识的匮乏,让我在这里折腾了将近一天才搞定.可以说基本上网上遇到的问题我都遇到了.在这里,记下正确的步骤来给Centos配置网络.希望以后少走弯路. 首先我要说明的是,我 ...
- 一切皆文件-文件是对IO的最简抽象
引用<Linux Kernel Development>原书里面的一句话 in Unix, everything is a file.This simplifies the manipul ...
- [USACO5.2]Snail Trails
嘟嘟嘟 一道很水的爆搜题,然后我调了近40分钟…… 错误:输入数据最好用cin,因为数字可能不止一位,所以用scanf后,单纯的c[0]为字母,c[1]数字………………………… #include< ...