十二 web爬虫讲解2—Scrapy框架爬虫—Scrapy模拟浏览器登录—获取Scrapy框架Cookies
模拟浏览器登录
start_requests()方法,可以返回一个请求给爬虫的起始网站,这个返回的请求相当于start_urls,start_requests()返回的请求会替代start_urls里的请求
Request()get请求,可以设置,url、cookie、回调函数
FormRequest.from_response()表单post提交,第一个必须参数,上一次响应cookie的response对象,其他参数,cookie、url、表单内容等
yield Request()可以将一个新的请求返回给爬虫执行
在发送请求时cookie的操作,
meta={'cookiejar':1}表示开启cookie记录,首次请求时写在Request()里
meta={'cookiejar':response.meta['cookiejar']}表示使用上一次response的cookie,写在FormRequest.from_response()里post授权
meta={'cookiejar':True}表示使用授权后的cookie访问需要登录查看的页面
获取Scrapy框架Cookies
请求Cookie
Cookie = response.request.headers.getlist('Cookie')
print(Cookie)
响应Cookie
Cookie2 = response.headers.getlist('Set-Cookie')
print(Cookie2)

# -*- coding: utf-8 -*-
import scrapy
from scrapy.http import Request,FormRequest class PachSpider(scrapy.Spider): #定义爬虫类,必须继承scrapy.Spider
name = 'pach' #设置爬虫名称
allowed_domains = ['edu.iqianyue.com'] #爬取域名
# start_urls = ['http://edu.iqianyue.com/index_user_login.html'] #爬取网址,只适于不需要登录的请求,因为没法设置cookie等信息 header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:54.0) Gecko/20100101 Firefox/54.0'} #设置浏览器用户代理 def start_requests(self): #用start_requests()方法,代替start_urls
"""第一次请求一下登录页面,设置开启cookie使其得到cookie,设置回调函数"""
return [Request('http://edu.iqianyue.com/index_user_login.html',meta={'cookiejar':1},callback=self.parse)] def parse(self, response): #parse回调函数 data = { #设置用户登录信息,对应抓包得到字段
'number':'adc8868',
'passwd':'279819',
'submit':''
} # 响应Cookie
Cookie1 = response.headers.getlist('Set-Cookie') #查看一下响应Cookie,也就是第一次访问注册页面时后台写入浏览器的Cookie
print(Cookie1) print('登录中')
"""第二次用表单post请求,携带Cookie、浏览器代理、用户登录信息,进行登录给Cookie授权"""
return [FormRequest.from_response(response,
url='http://edu.iqianyue.com/index_user_login', #真实post地址
meta={'cookiejar':response.meta['cookiejar']},
headers=self.header,
formdata=data,
callback=self.next,
)]
def next(self,response):
a = response.body.decode("utf-8") #登录后可以查看一下登录响应信息
# print(a)
"""登录后请求需要登录才能查看的页面,如个人中心,携带授权后的Cookie请求"""
yield Request('http://edu.iqianyue.com/index_user_index.html',meta={'cookiejar':True},callback=self.next2)
def next2(self,response):
# 请求Cookie
Cookie2 = response.request.headers.getlist('Cookie')
print(Cookie2) body = response.body # 获取网页内容字节类型
unicode_body = response.body_as_unicode() # 获取网站内容字符串类型 a = response.xpath('/html/head/title/text()').extract() #得到个人中心页面
print(a)
模拟浏览器登录2
第一步、
爬虫的第一次访问,一般用户登录时,第一次访问登录页面时,后台会自动写入一个Cookies到浏览器,所以我们的第一次主要是获取到响应Cookies
首先访问网站的登录页面,如果登录页面是一个独立的页面,我们的爬虫第一次应该从登录页面开始,如果登录页面不是独立的页面如 js 弹窗,那么我们的爬虫可以从首页开始
# -*- coding: utf-8 -*-
import scrapy
from scrapy.http import Request,FormRequest
import re class PachSpider(scrapy.Spider): #定义爬虫类,必须继承scrapy.Spider
name = 'pach' #设置爬虫名称
allowed_domains = ['dig.chouti.com'] #爬取域名
# start_urls = [''] #爬取网址,只适于不需要登录的请求,因为没法设置cookie等信息 header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:54.0) Gecko/20100101 Firefox/54.0'} #设置浏览器用户代理 def start_requests(self):
"""第一次请求一下登录页面,设置开启cookie使其得到cookie,设置回调函数"""
return [Request('http://dig.chouti.com/',meta={'cookiejar':1},callback=self.parse)] def parse(self, response):
# 响应Cookies
Cookie1 = response.headers.getlist('Set-Cookie') #查看一下响应Cookie,也就是第一次访问注册页面时后台写入浏览器的Cookie
print('后台首次写入的响应Cookies:',Cookie1) data = { # 设置用户登录信息,对应抓包得到字段
'phone': '8615284816568',
'password': '279819',
'oneMonth': '1'
} print('登录中....!')
"""第二次用表单post请求,携带Cookie、浏览器代理、用户登录信息,进行登录给Cookie授权"""
return [FormRequest.from_response(response,
url='http://dig.chouti.com/login', #真实post地址
meta={'cookiejar':response.meta['cookiejar']},
headers=self.header,
formdata=data,
callback=self.next,
)] def next(self,response):
# 请求Cookie
Cookie2 = response.request.headers.getlist('Cookie')
print('登录时携带请求的Cookies:',Cookie2) jieg = response.body.decode("utf-8") #登录后可以查看一下登录响应信息
print('登录响应结果:',jieg) print('正在请需要登录才可以访问的页面....!') """登录后请求需要登录才能查看的页面,如个人中心,携带授权后的Cookie请求"""
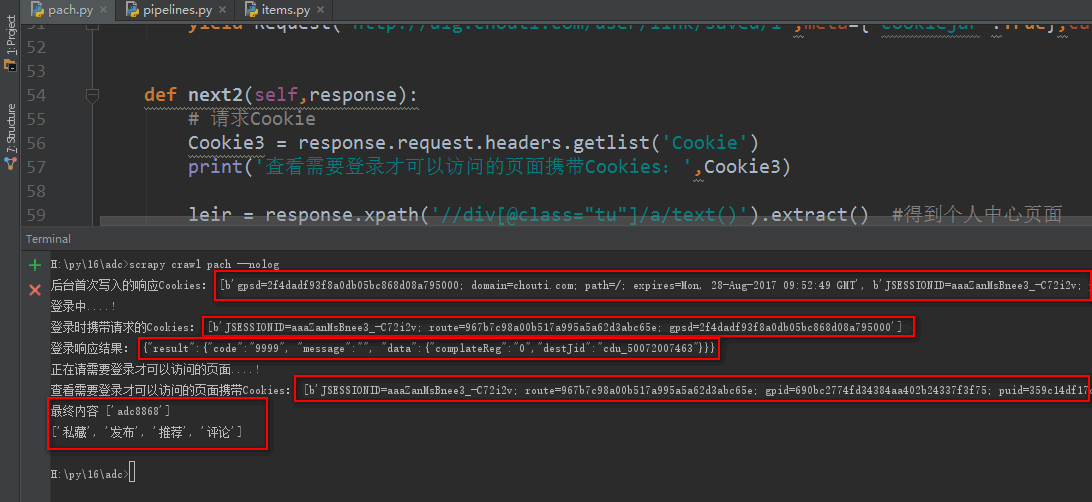
yield Request('http://dig.chouti.com/user/link/saved/1',meta={'cookiejar':True},callback=self.next2) def next2(self,response):
# 请求Cookie
Cookie3 = response.request.headers.getlist('Cookie')
print('查看需要登录才可以访问的页面携带Cookies:',Cookie3) leir = response.xpath('//div[@class="tu"]/a/text()').extract() #得到个人中心页面
print('最终内容',leir)
leir2 = response.xpath('//div[@class="set-tags"]/a/text()').extract() # 得到个人中心页面
print(leir2)
十二 web爬虫讲解2—Scrapy框架爬虫—Scrapy模拟浏览器登录—获取Scrapy框架Cookies的更多相关文章
- 第三百三十三节,web爬虫讲解2—Scrapy框架爬虫—Scrapy模拟浏览器登录—获取Scrapy框架Cookies
第三百三十三节,web爬虫讲解2—Scrapy框架爬虫—Scrapy模拟浏览器登录 模拟浏览器登录 start_requests()方法,可以返回一个请求给爬虫的起始网站,这个返回的请求相当于star ...
- 第三百二十九节,web爬虫讲解2—urllib库爬虫—ip代理—用户代理和ip代理结合应用
第三百二十九节,web爬虫讲解2—urllib库爬虫—ip代理 使用IP代理 ProxyHandler()格式化IP,第一个参数,请求目标可能是http或者https,对应设置build_opener ...
- 第三百二十八节,web爬虫讲解2—urllib库爬虫—状态吗—异常处理—浏览器伪装技术、设置用户代理
第三百二十八节,web爬虫讲解2—urllib库爬虫—状态吗—异常处理—浏览器伪装技术.设置用户代理 如果爬虫没有异常处理,那么爬行中一旦出现错误,程序将崩溃停止工作,有异常处理即使出现错误也能继续执 ...
- 第三百三十节,web爬虫讲解2—urllib库爬虫—实战爬取搜狗微信公众号—抓包软件安装Fiddler4讲解
第三百三十节,web爬虫讲解2—urllib库爬虫—实战爬取搜狗微信公众号—抓包软件安装Fiddler4讲解 封装模块 #!/usr/bin/env python # -*- coding: utf- ...
- 第三百二十七节,web爬虫讲解2—urllib库爬虫—基础使用—超时设置—自动模拟http请求
第三百二十七节,web爬虫讲解2—urllib库爬虫 利用python系统自带的urllib库写简单爬虫 urlopen()获取一个URL的html源码read()读出html源码内容decode(& ...
- ASP.NET MVC 4 (十二) Web API
Web API属于ASP.NET核心平台的一部分,它利用MVC框架的底层功能方便我们快速的开发部署WEB服务.我们可以在常规MVC应用通过添加API控制器来创建web api服务,普通MVC应用程序控 ...
- 七 web爬虫讲解2—urllib库爬虫—状态吗—异常处理—浏览器伪装技术、设置用户代理
如果爬虫没有异常处理,那么爬行中一旦出现错误,程序将崩溃停止工作,有异常处理即使出现错误也能继续执行下去 1.常见状态吗 301:重定向到新的URL,永久性302:重定向到临时URL,非永久性304: ...
- 六十二 Web开发 使用模板
Web框架把我们从WSGI中拯救出来了.现在,我们只需要不断地编写函数,带上URL,就可以继续Web App的开发了. 但是,Web App不仅仅是处理逻辑,展示给用户的页面也非常重要.在函数中返回一 ...
- 八 web爬虫讲解2—urllib库爬虫—ip代理—用户代理和ip代理结合应用
使用IP代理 ProxyHandler()格式化IP,第一个参数,请求目标可能是http或者https,对应设置build_opener()初始化IPinstall_opener()将代理IP设置成全 ...
随机推荐
- 接口测试工具 — jmeter(数据库操作)
1.导入jdbc jar包 2.配置MySQL连接 3.执行sql语句
- FastReports_4.14.1 _Cliff手动安装
首次编译frx15.dproj包的时候,会出错: [DCC Fatal Error] fs15.dpk(59): F1026 File not found: 'fs_ipascal.dcu'原因是因为 ...
- 转!java自定义注解
转自:http://blog.csdn.net/yixiaogang109/article/details/7328466 Java注解是附加在代码中的一些元信息,用于一些工具在编译.运行时进行解析 ...
- Scrapy框架-scrapy框架快速入门
1.安装和文档 安装:通过pip install scrapy即可安装. Scrapy官方文档:http://doc.scrapy.org/en/latest Scrapy中文文档:http://sc ...
- 编程算法 - 全然背包问题 代码(C)
全然背包问题 代码(C) 本文地址: http://blog.csdn.net/caroline_wendy 题目: 有n个重量和价值分别为w,v的物品, 从这些物品中挑选出总重量不超过W的物品, 求 ...
- java 多线程 day04 线程通信
package com.czbk.thread; /** * Created by chengtao on 17/12/3. * 需求: 子线程先运行10次,然后主线程运行 100次,依次运行50次 ...
- pandas(九)数据转换
移除重复数据 dataframe中常常会出现重复行,DataFrame对象的duplicated方法返回一个布尔型的Series对象,可以表示各行是否是重复行.还有一个drop_duplicates方 ...
- virtualenv使用
virtualenv安装不同版本的python 来自为知笔记(Wiz)
- ASP.NET4 与 VS2010 Web 开发页面服务改进
转:http://blog.163.com/kele_lipeng/blog/static/81345278201132754729336/ 作者:朱先忠 本文将接着上一篇 ASP.NET4与VS20 ...
- Oracle事务和锁机制
事务 1. 说明 一组SQL,一个逻辑工作单位,执行时整体修改或者整体回退. 2.事务相关概念 1)事务的提交和回滚:COMMIT/ROLLBACK 2)事务的开始和结束 开始事务:连接到数据库,执行 ...