ngs中reads mapping-pku的生信课程
4.NGS中的reads mapping
顾名思义,就是将测序的得到的DNA定位在基因组上。
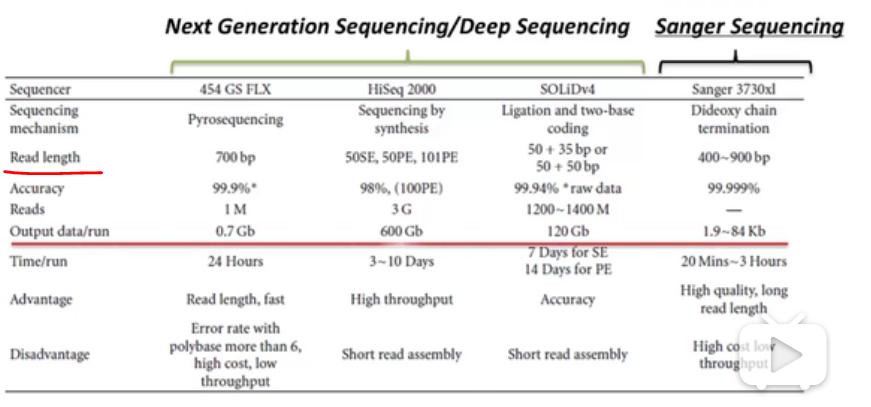
因为二代测序的得到的序列是较短的,reads mapping很好地解决了这个问题。

本质上reads mapping是一个双序列比对问题,但和之前讲的NW和SW的不一样,后者适用于两者长度相差不大的。
现在问题有几个特征:
1.reads和ref的长度有着跨数量级的差异,reads长度通常不超过100bp,而ref基因组通常在上百Mb。
2.数据量,NGS测序产生的数据量达到几百Gb,相当于几十个人的人类基因组。
3.数据质量。在双序列比对中通常假定序列本身不会出错,但是NGS所产生的reads质量参差不齐。
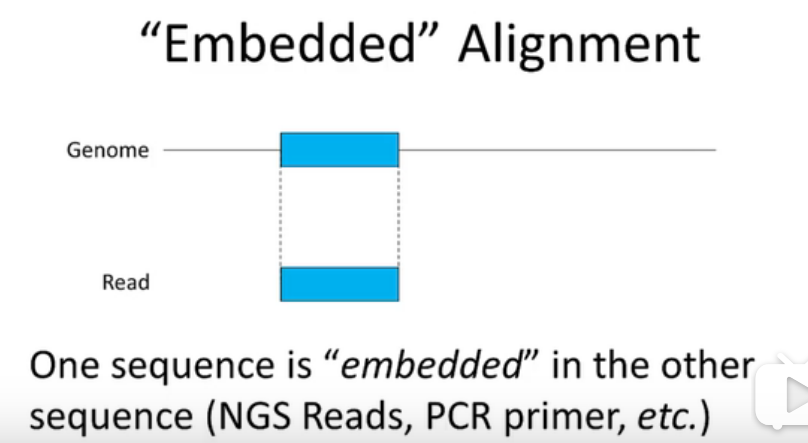
reads可以说是镶嵌到基因组序列中的,对于基因组来说是局部比对,对于reads来说是全局比对,是一个混合型的alignment。
首先对基因组建立索引,也就是index,

将每一个基因根据key映射到一个index,从而存储在不同的数据块中,尽量减少比对时间。
哈希可以来完成,以下例子:

先给ACGT分别确定一个值,那么将求和作为哈希函数,将基因组中分段,然后进行映射存储。这样有一个reads之后就可以以O(1)时间内寻找位置。
通常有一定的容错性。

数据压缩中的前缀树和后缀树被应用于reads mapping。 这里也提到了bowtie和BTW(Burruws Wheeler transform),提高了内存利用效率和比对速度。

在对短序列对比时,将所有的SQ都算出来,read中每个碱基都有一个测序质量,假定错配都是由测序错误引起的,从而计算出SQ。
在实际对read mapping的比对中,通常不使用序列比对分数,而使用mapping Quality(也就是最后一行的E),来筛选Read在Ref中的位置。
//这个415是如何得到的呢?是所有SQ的和。
当将reads正确映射到基因组之后,就可以来判断遗传变异。
根据遗传变异的尺寸,可以分为单个碱基水平的单核苷酸变异和多个:

//这个图说的简直十分清晰。
SNV是最常见的遗传变异分析方法:包括替换碱基,或者插入删除碱基。
SV:包括大规模删除插入、倒转、易位、拷贝数变异。

SNP calling是确定哪个基因位点存在变异,不涉及到对应位点的基因型。
Genotype calling是进一步确定变异位点的基因型是纯合的还是杂合的。
测序深度(sequencing depth):测序得到的碱基总量与基因组大小的比值。 它与基因组覆盖度是一个正相关的关系。测序错误率和假阳性结果会随测序深度的提高而下降。
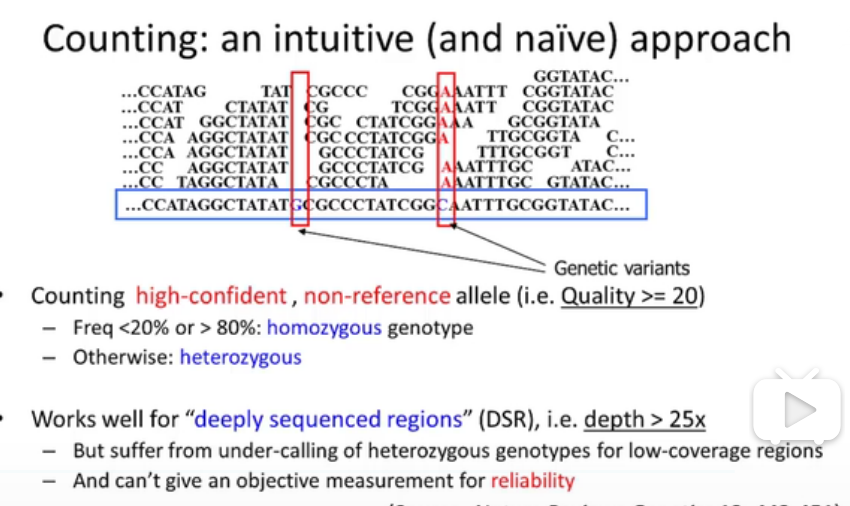
//这张图它在说什么,我完全听不懂啊。什么就是纯和了,怎么就杂合了?

这里给出了一个简单的概率模型。
一个生物体的基因型,有三种情况,那么假设在基因测序中测到的有k个A,有n-k个a。
如果是AA,那么概率就是n-k个a错误概率的乘积,杂合子由1-二者之和。
那么如果知道生物体中三种基因型出现了概率作为先验概率,那么可以推算出,后验概率。
//其实这里不太明白D是什么?
ngs中reads mapping-pku的生信课程的更多相关文章
- 生信基础知识【04】GO和pathway分析
非原创 参考资料: 一文掌握GO和pathway分析 - 生物信息学讨论版 -丁香园论坛http://www.dxy.cn/bbs/thread/34904124#34904124 GO富集 GO是G ...
- 生信-使用NCBI进行目的基因的引物设计
使用NCBI进行目的基因的引物设计 全文概述 利用生信工具进行目的基因的引物设计,使用了NCBI进行筛选与设计引物,使用 idtdna对筛选出的DNA进行检查.本文分享了如何筛选出高质量的基因引物,帮 ...
- knockoutjs中使用mapping插件绑定数据列表
使用KO绑定数据列表示例: 1.先申请V,T,T2三个辅助方法,方便调试.声明viewModel和加载数据时的映射条件mapping 2.先使用ko.mapping.fromJS()将原来的 ...
- elasticsearch中的mapping映射配置与查询典型案例
elasticsearch中的mapping映射配置与查询典型案例 elasticsearch中的mapping映射配置示例比如要搭建个中文新闻信息的搜索引擎,新闻有"标题".&q ...
- 生信工具汇总--OMICtools
各种生信工具: https://omictools.com/
- 生信软件的好帮手-bioconda--转载
http://mp.weixin.qq.com/s/nK1Kkf9lfZStoX25Y7SzHQ 这篇文章主要适用于Linux平台,当然MacOS也行,不过它有更好安装方法. 此外网上也会许多更好的关 ...
- 精心整理(含图版)|你要的全拿走!(R数据分析,可视化,生信实战)
本文首发于“生信补给站”公众号,https://mp.weixin.qq.com/s/ZEjaxDifNATeV8fO4krOIQ更多关于R语言,ggplot2绘图,生信分析的内容,敬请关注小号. 为 ...
- ElasticSearch 中的 Mapping
公号:码农充电站pro 主页:https://codeshellme.github.io 1,ES 中的 Mapping ES 中的 Mapping 相当于传统数据库中的表定义,它有以下作用: 定义索 ...
- 生信基础概念之unique reads VS multi-mapping reads
unique reads:在参考组上只有一个匹配点 multi-mapping reads:在参考组上有多个匹配点 下面是tophat的一个结果案例: Reads: Input : Mapped : ...
随机推荐
- js测试
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- apache ab测试
网站并发测试,网站服务使用的是apache2.4 因此使用ab来测试网站性能. windows使用cms 打开apache/bin 运行ab.exe (......../apache/bin/ab), ...
- 获取JQuery UI tabs中被选中的tabs的方法
JQuery标签事件处理实例 如果你正在使用JQuery tabs而且想从基本的功能扩展到自定义的功能,这是你最好知道如何处理JQuery的点击事件. 在这篇文章中: 1.回顾如何添加当tab被点击时 ...
- web.py 安装
安装 安装web.py, 请先下载: http://webpy.org/static/web.py-0.37.tar.gz 或者获取最新的开发版: https://github.com/webpy/w ...
- 总结几个关于 jQuery 用法
有关 jquery 用法 目录: $.trim() $.inArray() $.getJSON() 事件委托 on 遍历closest() ajaxSubmit() 拖拽排序 dragsort() 进 ...
- 【PM日记】处理事务的逻辑
首先你得时刻搞清楚在你的当下什么类型事情是最重要的,是与人交流,是推进项目,还是需要更加埋头学习知识. 每天你得有个list,可以是上一日遗留下来的部分未完成项,可以是idea收集箱中拿到的新任务,总 ...
- 把查询到结果合并放在一行 JOIN非union
select one.max,one.min,one.low sts,c.high ens,one.time from ( select a.max max,a.min min,b.low low,a ...
- 【BZOJ】3538: [Usaco2014 Open]Dueling GPS(spfa)
http://www.lydsy.com/JudgeOnline/problem.php?id=3538 题意不要理解错QAQ,是说当前边(u,v)且u到n的最短距离中包含这条边,那么这条边就不警告. ...
- js压缩 uglify
grunt-contrib-uglify uglify是一个文件压缩插件,项目地址:https://github.com/gruntjs/grunt-contrib-uglify 本文将以一个DEMO ...
- 蓝桥杯 第三届C/C++预赛真题(8) 密码发生器(水题)
在对银行账户等重要权限设置密码的时候,我们常常遇到这样的烦恼:如果为了好记用生日吧,容易被破解,不安全:如果设置不好记的密码,又担心自己也会忘记:如果写在纸上,担心纸张被别人发现或弄丢了... 这个程 ...