Machine Learning笔记整理 ------ (三)基本性能度量
1. 均方误差,错误率,精度
给定样例集 (Example set):
D = {(x1, y1), (x2, y2), (x3, y3), ......, (xm, ym)}
其中xi是对应属性的值,yi是xi的真实标记,评估模型性能,即将预测结果f(x)与真实标记y进行比较。
对于回归任务:均方误差 (Mean squared error)
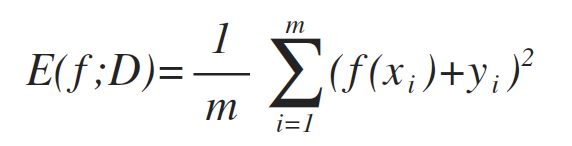
更一般的,对于数据分布D和概率密度函数p(·),均方误差可描述为:
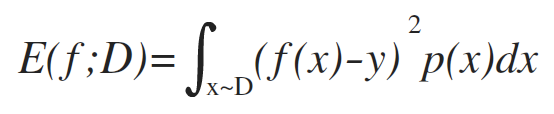
错误率 (Error rate):分类错误样本数占总样本数比例(其中,II(·)为指示函数,在·为真假时分别取1和0):

相应的精度 (accuracy) 可以定义为:
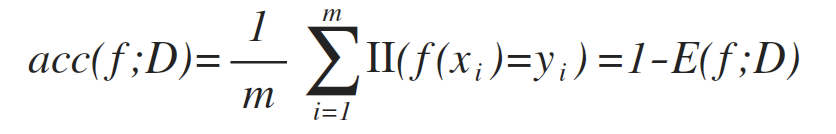
更一般的,对于数据分布D和概率密度函数p(·),错误率和精度可描述为:
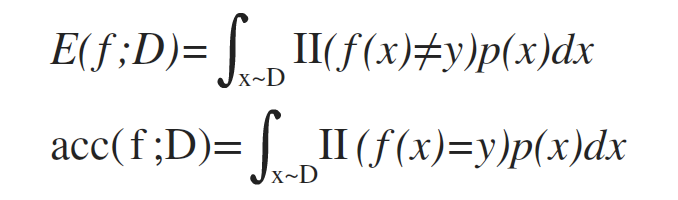
2. 混淆矩阵,查准率,查全率,Fβ度量
(1) 混淆矩阵 (Confusion matrix)
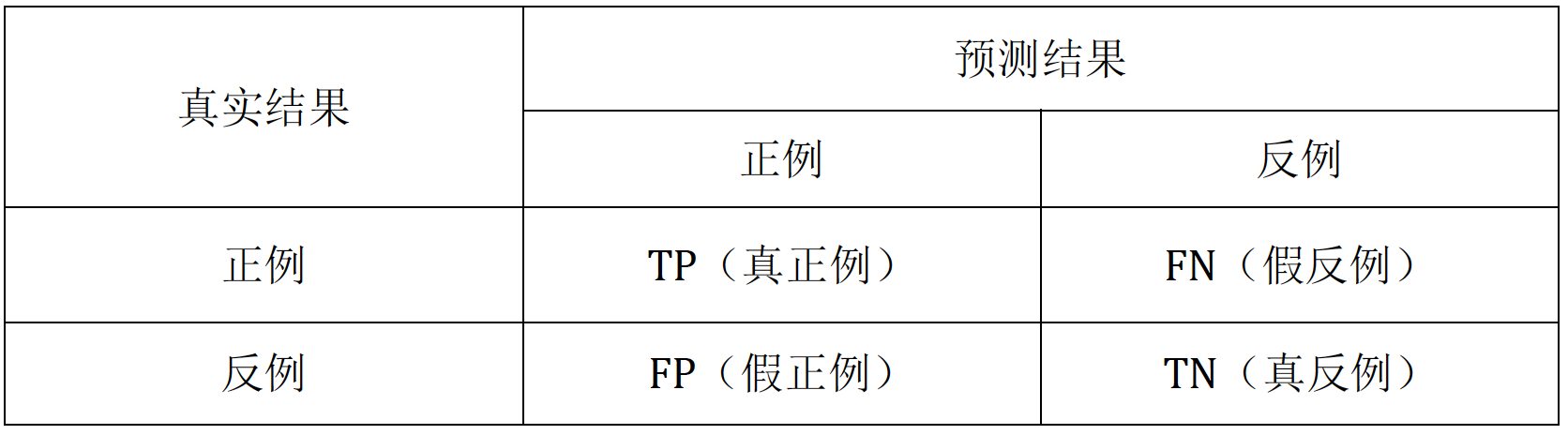
真正例TP(True positive):将正例预测为正例(正确)
假反例FN(False negative):将正例预测为反例(错误)
假正例FP(False positive):将反例预测为正例(错误)
真反例TN(True negative):将反例预测为反例(正确)
即:T和F表示预测的结果是否正确,P和N表示模型预测的结果为正或反,故只要是F那么前后一定不一致。
#!/usr/bin/env python3 from sklearn import metrics # titanic.y为实际标签集合,titanic_y_pred为模型预测的标签集合
confusion_matrix = metrics.confusion_matrix(titanic.y, titanic_y_pred) TP = confusion_matrix[1, 1]
TN = confusion_matrix[0, 0]
FP = confusion_matrix[0, 1]
FT = confusion_matrix[1, 0]
输出结果: (245, 455, 94, 97)
(2) 查准率 (Precision),查全率 (Recall)
查准率和查全率的定义如下:

一般而言,查准率P和查全率R是一对相互矛盾的性能度量指标,例如,如果想将某类别A全部选出来,只需要增加选取的数量,若样本总数为m,将m个样本全部选出来,即所有样本都被选中,自然包括了全部类别为A的样本,查全率R自然会很高,而查准率很差;相对应的,如果仅仅选取最有把握的样本,则会漏掉不少正确的样本,查准率会很高,查全率则会很低。
(3) P-R曲线 (P-R Curve),平衡点(Break-Even Point, BEP)
以查全率R为横轴、查准率P为纵轴,可以做P-R曲线与P-R图,即:
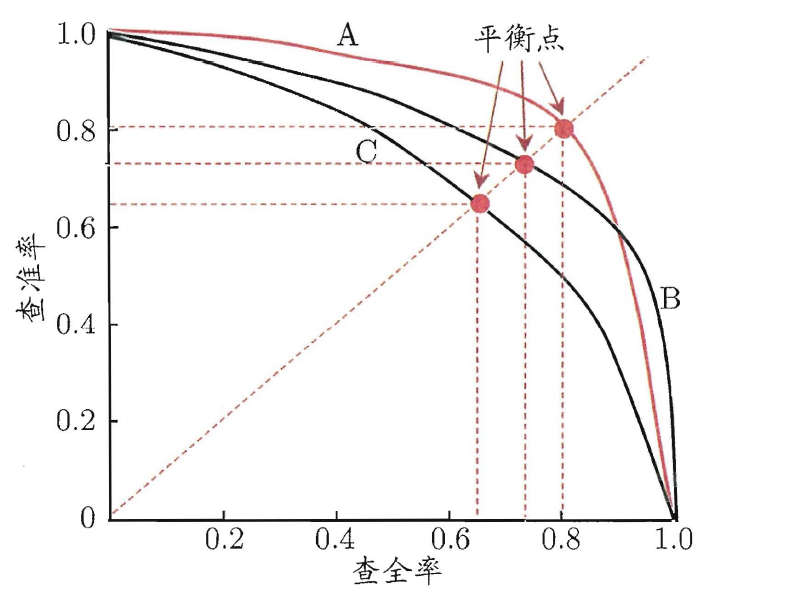
Area(A) > Area(C),则模型A的性能优于C
Area(B) > Area(C),则模型B的性能优于C
但如上图所示,A、B相交难以直接判断,故可以使用平衡点来进行判断,平衡点(Break-Even Point,BEP)的定义是:当 查准率P = 查全率R时,两者的取值,可作f(x)=x,找与AB曲线相交的交点即为平衡点,所以,上图中,模型A的性能优于模型B的性能。
(4) F1度量,Fβ度量,宏度量,微度量
F1度量是基于查准率和查全率的调和平均(harmonic mean)定义的,即:

故有F1度量的表示形式:

而F1度量的一般形式Fβ度量,则是基于查准率和查全率的加权调和平均定义的:

故有Fβ度量的表示形式:

总结:
- 当β = 1时,为F1度量
- 当β > 1时,查全率影响较大
- 当β < 1时,查准率影响较大
- 即当β > 0时,度量了查全率对查准率的相对重要性
综上所述,对于二分类任务,可以做多个混淆矩阵(多次训练、测试)/(多个训练集训练、测试),若为多分类任务,则可以以每两两类别的组合对应一个混淆矩阵,在n个二分类混淆矩阵上综合考察查准率P和查全率R。更直接的做法是使用宏查准率(marco-P)与宏查全率(marco-R)以及相应的宏F1度量(marco-F1):

同样,将个矩阵元素平均,可以得到TP、FP、TN和FN的平均值,再计算得出微查准率(micro-P)与微查全率(micro-R)以及对应的微F1度量(micro-F1):

3. ROC (Receiver Operating Characteristic),AUC(Area Under ROC Curve)
(1) ROC(Receiver Operating Characteristic) 受试工作者特征
ROC曲线的横轴为假正例率FPR(False Positive Rate),纵轴为真正例率(True Positive Rate),两者的定义如下:
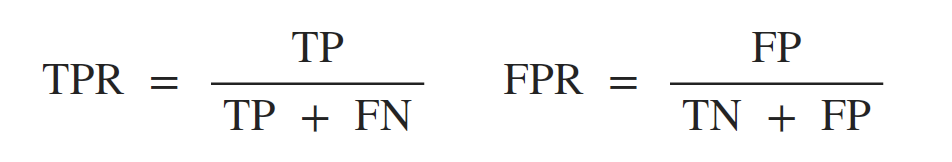
根据预测结果,对样例进行排序,按此顺序逐个把样本作为正例进行预测,每次计算出FP和TP并作图,即得到ROC曲线,下图中(a)对角虚线对应于“随机猜测”模型。另,ROC曲线仅适用于二分类模型(前提在于选定阈值)。
#!/usr/bin/env python3 import numpy as np
from sklearn.metrics import roc_curve y = np.array([1, 1, 2, 2])
scores = np.array([0.1, 0.4, 0.35, 0.8])
fpr, tpr, thresholds = roc_curve(y, scores, pos_label=2) fpr, tpr, thresholds
输出: array([ 0. , 0.5, 0.5, 1. ])
array([ 0.5, 0.5, 1. , 1. ])
array([ 0.8 , 0.4 , 0.35, 0.1 ])
(2) AUC(Area Under ROC Curve)ROC曲线下面积
AUC即ROC曲线下对应面积,可以使用如下方式计算:
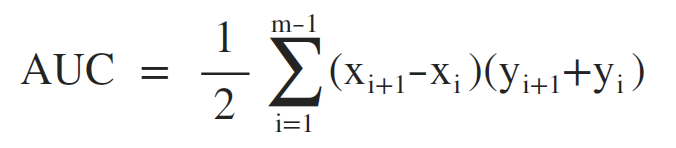
意义:从所有类别为1的样本中随机选取一个样本,再从所有类别为0的样本中随机选取一个样本,用模型进行预测,将1预测为1的概率为p1,将0预测为0的概率为p0,p1>p0的概率即为AUC的值。所以,AUC的值不会超过1,而且越接近1则表示模型的性能越好。
附:平均数、方差、标准差及置信区间的计算公式(之前写毕业论文时,导师要求对每个建模的结果求出对应95%情况下的置信区间)
平均数 (Mean)
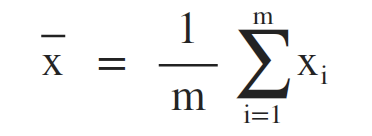
方差 (Variance)
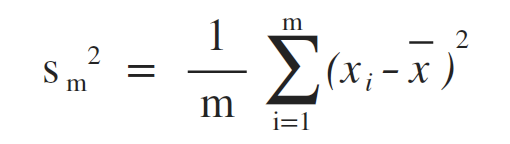
标准差 (Standard Variance)
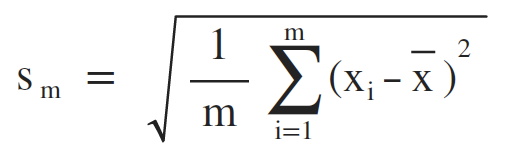
置信区间 (Confidence Interval)
置信区间的意义在于表征数据结果的可信程度,其区间的上下限为:
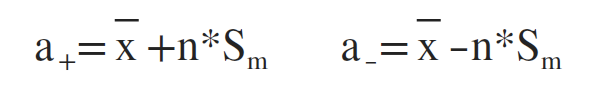
当90%,n = 1.645;当95%时,n=1.96;当99%时,n=2.576(其余对应值可查表)。
Machine Learning笔记整理 ------ (三)基本性能度量的更多相关文章
- Machine Learning笔记整理 ------ (一)基本概念
机器学习的定义:假设用P来评估计算机程序在某任务类T上的性能,若一个程序通过利用经验E,使其在T中任务获得了性能改善,我们则说关于任务类T和P,该程序对经验E进行了学习(Mitchell, 1997) ...
- Machine Learning笔记整理 ------ (五)决策树、随机森林
1. 决策树 一般的,一棵决策树包含一个根结点.若干内部结点和若干叶子结点,叶子节点对应决策结果,其他每个结点对应一个属性测试,每个结点包含的样本集合根据属性测试结果被划分到子结点中,而根结点包含样本 ...
- Machine Learning笔记整理 ------ (四)线性模型
1. 线性模型 基本形式:给定由d个属性描述的样本 x = (x1; x2; ......; xd),其中,xi是x在第i个属性上的取值,则有: f(x) = w1x1 + w2x2 + ...... ...
- Machine Learning笔记整理 ------ (二)训练集与测试集的划分
在实际应用中,一般会选择将数据集划分为训练集(training set).验证集(validation set)和测试集(testing set).其中,训练集用于训练模型,验证集用于调参.算法选择等 ...
- 第五周(web,machine learning笔记)
2019/11/2 1. 表现层状态转换(REST, representational state transfer.)一种万维网软件架构风格,目的是便于不同软件/程序在网络(例如互联网)中互相 ...
- Python学习笔记整理(三)Python中的动态类型简介
Python中只有一个赋值模型 一.缺少类型声明语句的情况 在Python中,类型是在运行过程中自动决定的,而不是通过代码声明.这意味着没有必要事声明变量.只要记住,这个概念实质上对变量,对象和它们之 ...
- machine learning 笔记 normal equation
theta=(Xt*X)^-1 Xt*y x is feature matrix y is expectation
- Struts2学习笔记整理(三)
Struts2的输入校验 之前对请求参数的输入校验一般分为两部分:1.客户端校验,也就是我们写js代码去对客户的误操作进行过滤 2.服务端校验, 这是整个应用组织非法数据的最后防线. Struts2 ...
- Flex 笔记整理 三
1. Panel, TitleWindow PopUpManager 透明 用一个类,这个类里引用一个组件, P如 Panel, TitleWindow等, 利用PopUpManager来弹出显示. ...
随机推荐
- SpringBoot自动装配的原理
1.SpringApplication.run(AppConfig.class,args);执行流程中有refreshContext(context);这句话. 2.refreshContext(co ...
- 将jquery.qqFace.js表情转换成微信的字符码
jquery.qqFace.js使用方法 引用 <script src="~/Content/qqFace/js/jquery.qqFace.js?v=3"></ ...
- jQuery 属性操作 - addClass() 和 removeClass() 方法
实例 向第一个 p 元素添加一个类: $("button").click(function(){ $("p:first").addClass("int ...
- HDU 5536--Chip Factory(暴力)
Chip Factory Time Limit: 18000/9000 MS (Java/Others) Memory Limit: 262144/262144 K (Java/Others)T ...
- 在控制台中操作MYSQL数据库步骤以及一些小问题
一直用Navicat来对MySQL数据库进行操作,今天突然想试试用DOS控制台来操作,特记录自己第一次使用经历,若有错误之处,还望大佬们指点. 首先打开控制台,win+R键,输入cmd,确定 输入my ...
- 正则验证input输入,要求只能输入正数,小数点后保留两位。
<input type="number" step="1" min="0" onkeyup="this.value= thi ...
- JSON与Delphi Object的互换
Delphi自从增强了RTTI后,语言的可灵活性多大增强,Delphi的dbExpress中提供了DBXJSON,和DBXJSONReflect两个单元,可提供JSON序列化 下面的例子是实现Delp ...
- 第七篇:gcc和arm-linux-gcc常用选项
目录 一.gcc和arm-linux-gcc的常用选项 二.从.c文件到可执行文件过程 一.gcc和arm-linux-gcc的常用选项 常用选型 -v 查看gcc编译器的版本,显示gcc执行时的详细 ...
- A1041
输入n个数,找出第一个只出现一次的数,输出它. 如果没有,输出none. 思路: 将输入的数值作为HashTable的数组下标即可. #include<cstdio> ], hashTab ...
- tensorflow简单实现卷积前向过程
卷积,说白了就是对应位置相乘再求和,卷积操作用广泛应用于图像识别,在自然语言处理中也开始应用,用作文本分类问题. 卷积操作最重要的部分就是卷积核或者说过滤器 1.常用过滤器尺寸为3*3或者5*5 2. ...