使用 URLDecoder 和 URLEncoder 对中文字符进行编码和解码
原文: https://blog.csdn.net/justloveyou_/article/details/57156039
使用 URLDecoder 和 URLEncoder 对中文字符进行编码和解码
摘要:
URLDecoder 和 URLEncoder 用于完成普通字符串 和 application/x-www-form-urlencoded MIME 字符串之间的相互转换。在本文中,我们以使用URLDecoder解决GET请求中文乱码问题为场景说明 URLDecoder/URLEncoder 的用法,并给出了 application/x-www-form-urlencoded MIME 字符串的编码规则。
一. URLDecoder/URLEncoder 使用场景概述
URLDecoder 和 URLEncoder 用于完成普通字符串 和 application/x-www-form-urlencoded MIME 字符串之间的相互转换。在介绍 application/x-www-form-urlencoded MIME 字符串之前,我们先考虑如下场景,如下图所示:

我们知道,在我们向客户端发起请求时,浏览器会根据请求URL生成相应的请求报文发送给服务器。在这个过程中,如果我们在浏览器中的地址栏中所输入的URL包含中文字符时,浏览器首先会将这些中文字符进行编码然后再发送给服务器。实际上,浏览器会将它们转换为 application/x-www-form-urlencoded MIME 字符串,如下图所示:
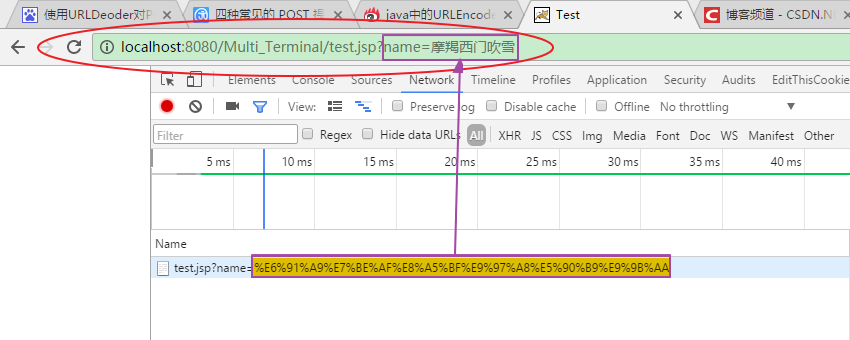
更确切的,当URL地址里包含非西欧字符的字符串时,浏览器都会将这些非西欧字符串转换成application/x-www-form-urlencoded MIME 字符串。在开发过程中,我们可能涉及将普通字符串和这种特殊字符串的相关转换,这就需要使用 URLDecoder 和 URLEncoder类进行实现,其中:
URLDecoder类包含一个decode(String s,String enc)静态方法,它可以将application/x-www-form-urlencoded MIME字符串转成普通字符串;
URLEncoder类包含一个encode(String s,String enc)静态方法,它可以将普通字符串转换成application/x-www-form-urlencoded MIME字符串。
下面程序示范了普通字符串转与 application/x-www-form-urlencoded MIME 字符串之间的转化。
public class URLDecoderTest {
public static void main(String[] args) throws Exception {
// 将application/x-www-form-urlencoded字符串转换成普通字符串
// 其中的字符串直接从上图所示窗口复制过来,chrome 默认用 UTF-8 字符集进行编码,所以也应该用对应的字符集解码
System.out.println("采用UTF-8字符集进行解码:");
String keyWord = URLDecoder.decode("%E5%A4%A9%E6%B4%A5%E5%A4%A7%E5%AD%A6+Rico", "UTF-8");
System.out.println(keyWord);
System.out.println("\n 采用GBK字符集进行解码:");
System.out.println(URLDecoder.decode("%E5%A4%A9%E6%B4%A5%E5%A4%A7%E5%AD%A6+Rico", "GBK"));
// 将普通字符串转换成application/x-www-form-urlencoded字符串
System.out.println("\n 采用utf-8字符集:");
String urlStr = URLEncoder.encode("天津大学", "utf-8");
System.out.println(urlStr);
System.out.println("\n 采用GBK字符集:");
String urlStr2 = URLEncoder.encode("天津大学", "GBK");
System.out.println(urlStr2);
}
}/* Output:
采用UTF-8字符集进行解码:
天津大学 Rico
采用GBK字符集进行解码:
澶╂触澶у Rico
采用utf-8字符集:
%E5%A4%A9%E6%B4%A5%E5%A4%A7%E5%AD%A6
采用GBK字符集:
%CC%EC%BD%F2%B4%F3%D1%A7
*///:~特别地,仅包含西欧字符的普通字符串和application/x-www-form-urlencoded MIME字符串无须转换,而包含中文字符的普通字符串则需要转换,转换的方法是每个中文字符占2个字节,每个字节可以转换成2个十六进制的数字,所以每个中文字符将转换成“%XX%XX”的形式。当然,采用不同的字符集时,每个中文字符对应的字节数并不完全相同,所以使用URLEncoder和URLDecoder进行转换时也需要指定字符集。特别地,字符串应以同样的字符集进行编码和解码,否则会产生意想不到的结果,如上述程序示例所示。
二. 解决GET请求中文乱码问题
URLDecoder的一个应用场景就是解决GET请求的中文乱码问题,如下述代码所示:
<%@page import="java.net.URLDecoder"%>
<%@ page language="java" import="java.util.*" pageEncoding="UTF-8"%>
<html>
<head>
<title>Test</title>
</head>
<body>
<%
String param1 = request.getQueryString();
String param2 = URLDecoder.decode(param1, "utf-8");
out.print(param2.split("=")[1] + "<br>");
%>
</body>
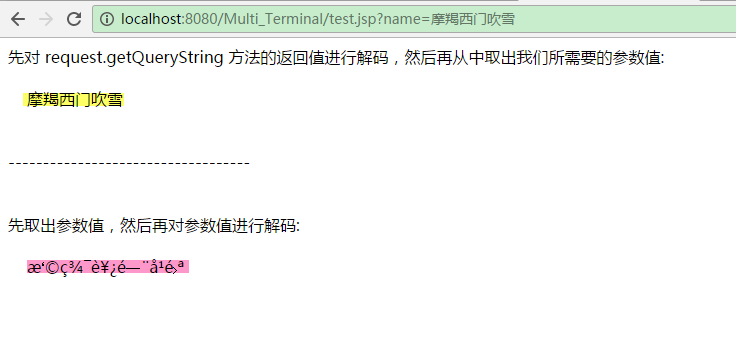
</html>特别需要注意的是,使用此方式对GET请求参数进行解码时,我们必须先对 request.getQueryString 方法的返回值(例如,“name=摩羯西门吹雪”)进行解码,然后再从中取出我们所需要的参数值。如果先取出参数值,然后再对参数值进行解码,则我们将得到乱码,如下图所示:
此外,对于包含中文字符的POST请求参数,我们只需在获取请求参数前通过以下代码语句进行转码即可:
request.setCharacterEncoding("utf-8");- 1
三. URLEncoder & URLDecoder
对 String 编码时,使用以下规则:
- 字母、数字和字符, “a” 到 “z”、”A” 到 “Z” 和 “0” 到 “9” 保持不变;
- 特殊字符 “.”、”-“、”*” 和 “_” 保持不变;
- 空格字符 ” ” 转换为一个加号 “+”。
除此之外,所有的其他字符都是不安全的。因此需要使用一些编码机制将它们转换为一个或多个字节,每个字节用一个包含 3 个字符的字符串 “%xy” 表示,其中 xy 为该字节的两位十六进制表示形式,推荐的编码机制是 UTF-8。例如,使用 UTF-8 编码机制,字符串 “The string ü@foo-bar” 将转换为 “The+string+%C3%BC%40foo-bar”,因为在 UTF-8 中,字符 ü 编码为两个字节,C3 (十六进制)和 BC (十六进制),字符 @ 编码为一个字节 40 (十六进制)。
关于 URLDecoder 类的使用,转换过程正好与 URLEncoder 类使用的过程相反,此不赘述。
关于JSP中文乱码更多的介绍,包括 页面乱码、参数乱码、表单乱码、源文件乱码 等知识,见我的另外两篇博客:《JSP中文乱码问题终极解决方案(上)》 和 《JSP中文乱码问题终极解决方案(下)》。
引用
使用 URLDecoder 和 URLEncoder 对中文字符进行编码和解码的更多相关文章
- PHP中文字符gbk编码与UTF-8编码的转换
通常PHP中上传文件,如果文件名称有中文字符,上传之后的名称是无法写入到本地的,因为上传来的编码格式一般是UTF-8的格式,这种格式是无法给文件命名并且存储到操作系统磁盘.在写入之前需要将其转换为gb ...
- [转载]Unicode中对中文字符的编码
以前写过一篇贴子是写中文在unicode中的编码范围 unicode中文范围,但写的不是很详细,今天再次研究了下unicode,并给出详细的unicode取值范围. 本次研究的unicode对象是un ...
- Java中的字节,字符与编码,解码
ASCII编码 ASCII码主要是为了表示英文字符而设计的,ASCII码一共规定了128个字符的编码(0x00-0x7F),只占用了一个字节的后面7位,最前面的1位统一规定为0. ISO-8859-1 ...
- [转]使用URLDecoder和URLEncoder对中文进行处理
一 URLEncoder HTML 格式编码的实用工具类.该类包含了将 String 转换为 application/x-www-form-urlencoded MIME 格式的静态方法.有关 HTM ...
- Java URLDecoder 和 URLEncoder 对中文进行编码和解码
URLDecoder类包含一个decode(String s,String enc)静态方法,它可以将application/x-www-form-urlencoded MIME字符串转成普通字符串: ...
- Java URLDecoder和URLEncoder对中文进行编码和解码
URLDecoder类包含一个decode(String s,String enc)静态方法,它可以将application/x-www-form-urlencoded MIME字符串转成普通字符串: ...
- 中文字符utf-8编码原则
UTF-8是一种变长字节编码方式.对于某一个字符的UTF-8编码,如果只有一个字节则其最高二进制位为0:如果是 多字节,其第一个字节从最高位开始,连续的二进制位值为1的个数决定了其编码的位数,其余各字 ...
- 对jsp中Url含中文字符的编码处理
有一段url="/app/index/index.jsp?userName='测试'":在传入到jsp页面后. 用 <% String userName=request.g ...
- Python中字符的编码与解码
1 文本和字节序列 我们都知道字符串,就是由一些字符组成的序列构成串,那么字符又是什么呢?计算机只能识别二进制的东西,那么计算机又为什么会显示我们的汉字,或者是某个字母呢? 由于最早发明使用计算机是美 ...
随机推荐
- plsql 连接数据库无法解析指定的连接标识符
之前用plsql连接的时候一直出问题,报无法解析指定的连接标识符,但是我加上ip地址就可以连接上. 我百度了很久,有说如下图选择oracle home的,有说清空admin目录下的所有文件, 但是都不 ...
- JavaScript Shell学习分享
目录 JavaScript Shell学习分享 简介 安装 使用原因 小结 JavaScript Shell学习分享 简介 JavaScript Shell是由Mozilla提供的综合JavaScri ...
- POJ2553 汇点个数(强连通分量
The Bottom of a Graph Time Limit: 3000MS Memory Limit: 65536K Total Submissions: 12070 Accepted: ...
- dns文件
1.dns简介 dns为域名解析系统,当本地浏览器输入域名访问网站时,如果本地host中没有配置域名与IP的对应关系,那么域名信息将会被发送到dns服务器上,由dns服务器将域名解析为IP(过程较为复 ...
- 【Python让生活更美好01】os与shutil模块的常用方法总结
Python作为一种解释型的高级语言,脚本语言,又被称作“胶水语言”,就是因为其灵活的语法和其依靠浩如烟海的第三方包实现的丰富多彩的功能,而os和shutil就是这样一种功能强大的模块,可以非常快捷地 ...
- 「题目代码」P1007~P1012(Java)
1007 C基础-计负均正 import java.util.*; import java.io.*; public class Main { public static void main(Stri ...
- CAS单点登录(一):单点登录与CAS理论介绍
一.什么是单点登录(SSO) 单点登录主要用于多系统集成,即在多个系统中,用户只需要到一个中央服务器登录一次即可访问这些系统中的任何一个,无须多次登录. 单点登录(Single Sign On),简称 ...
- tp5.0 模型查询数据的返回类型,分页
一开始用painate()这个函数的时候,发现有的查询方式不能使用这个函数,由此了解到了模型查询和普通查询返回类型的不同 1.原生查询方法 Db::query("select * from ...
- (原)UnrealObj篇 : 反射获取Struct类型
@Author: 白袍小道 转载请说明 案例一:蓝图传递任意Struct ,导出struct的相关属性 相关: 1.宏:DECLARE_FUNCTION: 此宏用于在自动生成的样板代码中声明t ...
- mysql数据备份和还原
MySQL是一个永久存储数据的数据库服务器.如果使用MySQLServer,那么需要创建数据库备份以便从崩溃中恢复.mysql提供了一个用于备份的实用程序mysqldump. 1.普通.sql文件中的 ...