机器学习(4)Hoeffding Inequality--界定概率边界
问题
假设空间的样本复杂度(sample complexity):随着问题规模的增长导致所需训练样本的增长称为sample complexity。
实际情况中,最有可能限制学习器成功的因素是训练数据的有限性。
在使用学习器的过程中,我们希望得到与训练数据拟合程度高的假设(hypothesis)。(在前面文章中提到,这样的假设我们称之为g)。
这就要求训练错误率为0。而实际上,大部分情况下,我们找不到这样的hypothesis(通过学习机得到的hypothesis)在训练集上有错误率为0。
所以退而求其次,我们只能要求通过学习机得到的hypothesis在训练集上错误率越低越好,最好接近0。
问题描述:
令D为有限的训练集,Ein(h)(in-sample error)为假设h在训练集D上的训练错误率,Eout(h)(out-of-sample error)是定义在全部数据的错误率。
(由此可知Eout(h)是不可直接求出的,因为不太可能将学习完无限的数据)。令g代表假设集中训练错误率最小的假设。
Hoeffding Inequality

Hoeffding Inequality刻画的是某个事件的真实概率与m各不同的Bernoulli试验中观察到的频率之间的差异。由上述的Hoeffding Inequality可知,
对我们是不可能得到真实的Eout(h),但我们可以通过让假设h在有限的训练集D上的错误率Ein(h)代表Eout(h)。
什么意思呢?Hoeffding Inequality告诉我们:较好拟合训练数据的假设与该假设针对整个数据集的预测,这两者的误差率相差很大的情况发生的概率其实是很小的。
Bad Sample and Bad Data
坏的样本(Bad Sample):假设h在有限的训练集D上的错误率Ein(h)=0,而真实错误率Eout(h)=1/2的情况。
坏的数据(Bad Data):Ein和Eout差别很大的情况。(通常情况下是Eout很大,Ein很小。
下面就将包含Bad data的Data用在多个h上。
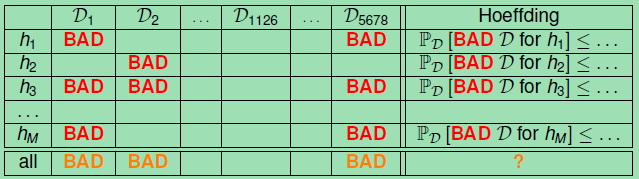
上图说明:
对于任一个假设hi,由Hoeffding可知其在所有的数据上(包括Bad Data)上出现不好的情况的总体概率是很小的。
Bound of Bad Data
由上面的表中可以得到下面的结论:

对于所有的M(假设的个数),N(数据集规模)和阈值,Hoeffding Inequality都是有效的
我们不必要知道Eout,可以通过Ein来代替Eout(这句话的意思是Ein(g)=Eout(g) is PAC).
感谢台大林老师的课。
参考:[原]【机器学习基础】理解为什么机器可以学习2——Hoeffding不等式
http://www.tuicool.com/articles/yyu2AnM
更多技术干货请关注:

机器学习(4)Hoeffding Inequality--界定概率边界的更多相关文章
- Hoeffding inequality
Hoeffding公式为 \epsilon]\leq{2e^{-2\epsilon^2N}}"> 如果把Training error和Test error分别看成和的话,Hoeffdi ...
- 机器学习笔记--Hoeffding霍夫丁不等式
Hoeffding霍夫丁不等式 在<>第八章"集成学习"部分, 考虑二分类问题\(y \in \{-1, +1\}\) 和真实函数\(f\), 假定基分类器的错误率为\ ...
- Andrew Ng机器学习公开课笔记 -- 学习理论
网易公开课,第9,10课 notes,http://cs229.stanford.edu/notes/cs229-notes4.pdf 这章要讨论的问题是,如何去评价和选择学习算法 Bias/va ...
- Machine Learning——吴恩达机器学习笔记(酷
[1] ML Introduction a. supervised learning & unsupervised learning 监督学习:从给定的训练数据集中学习出一个函数(模型参数), ...
- Coursera 机器学习基石 第4讲 学习的可行性
这一节讲述的是机器学习的核心.根本性问题——学习的可行性.学过机器学习的我们都知道,要衡量一个机器学习算法是否具有学习能力,看的不是这个模型在已有的训练数据集上的表现如何,而是这个模型在训练数据外的数 ...
- 【机器学习】Google机器学习工程的43条最佳实践
https://blog.csdn.net/ChenVast/article/details/81449509 本文档旨在帮助那些掌握机器学习基础知识的人从Google机器学习的最佳实践中获益.它提供 ...
- ML 01、机器学习概论
机器学习原理.实现与实践——机器学习概论 如果一个系统能够通过执行某个过程改进它的性能,这就是学习. ——— Herbert A. Simon 1. 机器学习是什么 计算机基于数据来构建概率统计模型并 ...
- NET平台机器学习组件-Infer.NET
NET平台机器学习组件-Infer.NET(三) Learner API—数据映射与序列化 阅读目录 关于本文档的说明 1.基本介绍 2.标准数据格式的映射 3.本地数据格式映射 4.评估数据格式映射 ...
- 机器学习 MLIA学习笔记(一)
监督学习(supervised learning):叫监督学习的原因是因为我们告诉了算法,我们想要预测什么.所谓监督,其实就是我们的意愿是否能直接作用于预测结果.典型代表:分类(classificat ...
随机推荐
- 用php+mysql+ajax实现淘宝客服或阿里旺旺聊天功能 之 前台页面
首先来看一下我已经实现的效果图: 消费者页面:(本篇随笔) (1)会显示店主的头像 (2)当前用户发送信息显示在右侧,接受的信息,显示在左侧 店主或客服页面:(下一篇随笔) (1)在左侧有一个列表 , ...
- JQuery源码阅读记录
新建html文件,在浏览器中打开文件,在控制台输入consoole.log(window);新建html文件,引入JQuery后在浏览器中打开,在控制台同样输入consoole.log(window) ...
- 编写自己的Nmap(NSE)脚本
编写自己的Nmap脚本 一.介绍 在上一篇文章Nmap脚本引擎原理中我们介绍了基本的NSE知识,这篇文章介绍如何基于Nmap框架编写简单的NSE脚本文件,下一篇文章,Nmap脚本文件分析(AMQP协议 ...
- BinarySearchTree-二叉搜索树
一.二叉搜索树的定义及性质 二叉查找树(Binary Search Tree),也称有序二叉树(ordered binary tree),排序二叉树(sorted binary tree),是指一棵空 ...
- form表单上传文件使用multipart请求处理
在开发Web应用程序时比较常见的功能之一,就是允许用户利用multipart请求将本地文件上传到服务器,而这正是Grails的坚固基石——spring MVC其中的一个优势.Spring通过对Serv ...
- ThreadLocal经典分页
package com.netease.live.admin.util; import com.netease.live.common.util.Constant; /** * * @author b ...
- 【LeetCode】66. Plus One
题目: Given a non-negative number represented as an array of digits, plus one to the number. The digit ...
- pdf文件之itextpdf插入html内容以及中文解决方案
简述 目前网上已经有很多种html文件直接转pdf的技术帖子,但是很少有直接将部分html作为段落插入到pdf中,而且也没有一个可以很好的解决中文显示的问题. 因此今天上午围绕这个问题进行了研究,把解 ...
- C语言之复杂链表的复制(图示详解)
什么是复杂链表? 复杂链表指的是一个链表有若干个结点,每个结点有一个数据域用于存放数据,还有两个指针域,其中一个指向下一个节点,还有一个随机指向当前复杂链表中的任意一个节点或者是一个空结点.今天我们要 ...
- JavaScript 定义 类
JavaScript 定义 类 一 构建类的原则 构造函数 等于 原型的constructor //构造函数 function Hero(name,skill){ this.name = name; ...