机器学习数学|偏度与峰度及其python实现
机器学习数学笔记|偏度与峰度及其python实现
觉得有用的话,欢迎一起讨论相互学习~




本博客为七月在线邹博老师机器学习数学课程学习笔记
为七月在线打call!!
课程传送门
矩
- 对于随机变量X,X的K阶原点矩为
\[E(X^{k})
\] - X的K阶中心矩为
\[E([X-E(X)]^{k})
\] - 期望实际上是随机变量X的1阶原点矩,方差实际上是随机变量X的2阶中心矩
- 变异系数(Coefficient of Variation):标准差与均值(期望)的比值称为变异系数,记为C.V
- 偏度Skewness(三阶)
- 峰度Kurtosis(四阶)
偏度与峰度

利用matplotlib模拟偏度和峰度
计算期望和方差
import matplotlib.pyplot as plt
import math
import numpy as np
def calc(data):
n=len(data) # 10000个数
niu=0.0 # niu表示平均值,即期望.
niu2=0.0 # niu2表示平方的平均值
niu3=0.0 # niu3表示三次方的平均值
for a in data:
niu += a
niu2 += a**2
niu3 += a**3
niu /= n
niu2 /= n
niu3 /= n
sigma = math.sqrt(niu2 - niu*niu)
return [niu,sigma,niu3]
\]
\]
\]
- sigma表示标准差公式为
\[\sigma=\sqrt{E(x^{2})-E(x)^{2}}
\]\[用python语言表示即为sigma = math.sqrt(niu2 - niu*niu)
\] - 返回值为[期望,标准差,\(E(x^{3})\)]
- PS:我们知道期望E(X)的计算公式为
\[E(X)=\sum_{i=1}^{n}p(i)x(i)-----(1)
\]这里我们X一个事件p(i)表示事件出现的概率,x(i)表示事件所给予事件的权值.
- 我们直接利用
\[E(x)=\bar{X_{i}}----(2)
\]表示期望应当明确
- (2)公式中\(X_{i}是利用numpy中的伪随机数生成的,其均值用于表示期望\)
- 此时(1)公式中对事件赋予的权值默认为1,即公式的本来面目为
\[E(x)=\bar{(X_{i}*1)}
\]
计算偏度和峰度
def calc_stat(data):
[niu, sigma, niu3]=calc(data)
n=len(data)
niu4=0.0 # niu4计算峰度计算公式的分子
for a in data:
a -= niu
niu4 += a**4
niu4 /= n
skew =(niu3 -3*niu*sigma**2-niu**3)/(sigma**3) # 偏度计算公式
kurt=niu4/(sigma**4) # 峰度计算公式:下方为方差的平方即为标准差的四次方
return [niu, sigma,skew,kurt]
利用matplotlib模拟图像
if __name__ == "__main__":
data = list(np.random.randn(10000)) # 满足高斯分布的10000个数
data2 = list(2*np.random.randn(10000)) # 将满足好高斯分布的10000个数乘以两倍,方差变成四倍
data3 =[x for x in data if x>-0.5] # 取data中>-0.5的值
data4 = list(np.random.uniform(0,4,10000)) # 取0~4的均匀分布
[niu, sigma, skew, kurt] = calc_stat(data)
[niu_2, sigma2, skew2, kurt2] = calc_stat(data2)
[niu_3, sigma3, skew3, kurt3] = calc_stat(data3)
[niu_4, sigma4, skew4, kurt4] = calc_stat(data4)
print (niu, sigma, skew, kurt)
print (niu2, sigma2, skew2, kurt2)
print (niu3, sigma3, skew3, kurt3)
print (niu4, sigma4, skew4, kurt4)
info = r'$\mu=%.2f,\ \sigma=%.2f,\ skew=%.2f,\ kurt=%.2f$' %(niu,sigma, skew, kurt) # 标注
info2 = r'$\mu=%.2f,\ \sigma=%.2f,\ skew=%.2f,\ kurt=%.2f$' %(niu_2,sigma2, skew2, kurt2)
info3 = r'$\mu=%.2f,\ \sigma=%.2f,\ skew=%.2f,\ kurt=%.2f$' %(niu_3,sigma3, skew3, kurt3)
plt.text(1,0.38,info,bbox=dict(facecolor='red',alpha=0.25))
plt.text(1,0.35,info2,bbox=dict(facecolor='green',alpha=0.25))
plt.text(1,0.32,info3,bbox=dict(facecolor='blue',alpha=0.25))
plt.hist(data,100,normed=True,facecolor='r',alpha=0.9)
plt.hist(data2,100,normed=True,facecolor='g',alpha=0.8)
plt.hist(data4,100,normed=True,facecolor='b',alpha=0.7)
plt.grid(True)
plt.show()
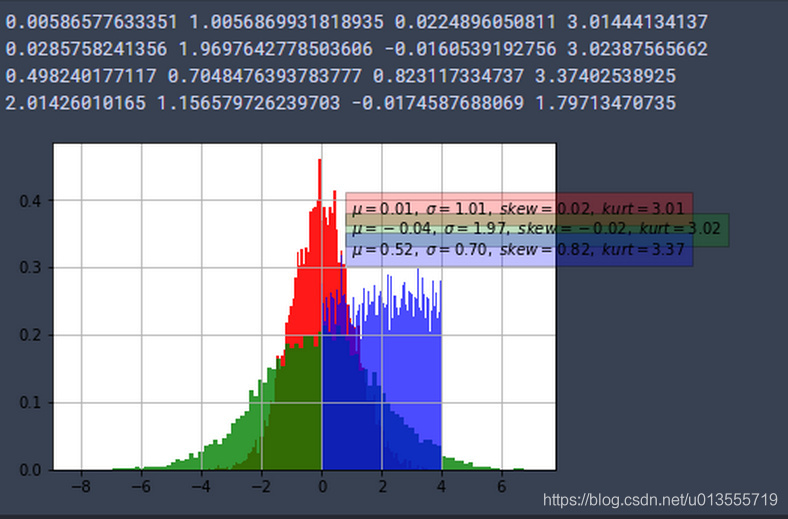
- 图形表示的是利用numpy随机数生成函数生成的随机数的统计分布,利用matplotlib.pyplot.hist绘制的直方图.即是出现数字的分布统计,并且是归一化到0~1区间后的结果.
- 即横轴表示数字,纵轴表示在1000个随机数中横轴对应的数出现的百分比.若不使用归一化横轴表示数字(normed=False),纵轴表示出现的次数.
- 若不使用归一化--纵轴表示出现次数,
- 关于matplotlib.pyplot.hist函数
n, bins, patches = plt.hist(arr, bins=10, normed=0, facecolor='black', edgecolor='black',alpha=1,histtype='b')
hist的参数非常多,但常用的就这六个,只有第一个是必须的,后面四个可选
arr: 需要计算直方图的一维数组
bins: 直方图的柱数,可选项,默认为10
normed: 是否将得到的直方图向量归一化。默认为0
facecolor: 直方图颜色
edgecolor: 直方图边框颜色
alpha: 透明度
histtype: 直方图类型,‘bar’, ‘barstacked’, ‘step’, ‘stepfilled’
返回值 :
n: 直方图向量,是否归一化由参数normed设定
bins: 返回各个bin的区间范围
patches: 返回每个bin里面包含的数据,是一个list
机器学习数学|偏度与峰度及其python实现的更多相关文章
- 机器学习经典算法详解及Python实现--基于SMO的SVM分类器
原文:http://blog.csdn.net/suipingsp/article/details/41645779 支持向量机基本上是最好的有监督学习算法,因其英文名为support vector ...
- 机器学习经典算法具体解释及Python实现--线性回归(Linear Regression)算法
(一)认识回归 回归是统计学中最有力的工具之中的一个. 机器学习监督学习算法分为分类算法和回归算法两种,事实上就是依据类别标签分布类型为离散型.连续性而定义的. 顾名思义.分类算法用于离散型分布预測, ...
- 机器学习数学|微积分梯度jensen不等式
机器学习中的数学 觉得有用的话,欢迎一起讨论相互学习~Follow Me 原创文章,如需转载请保留出处 本博客为七月在线邹博老师机器学习数学课程学习笔记 索引 微积分,梯度和Jensen不等式 Tay ...
- 机器学习数学|Taylor展开式与拟牛顿
机器学习中的数学 觉得有用的话,欢迎一起讨论相互学习~Follow Me 原创文章,如需转载请保留出处 本博客为七月在线邹博老师机器学习数学课程学习笔记 Taylor 展式与拟牛顿 索引 taylor ...
- 数据的偏度和峰度——df.skew()、df.kurt()
我们一般会拿偏度和峰度来看数据的分布形态,而且一般会跟正态分布做比较,我们把正态分布的偏度和峰度都看做零.如果我们在实操中,算到偏度峰度不为0,即表明变量存在左偏右偏,或者是高顶平顶这么一说. 一.偏 ...
- 投入机器学习的怀抱?先学Python吧
前两天写了篇文章,给想进程序员这个行当的同学们一点建议,没想到反响这么好,关注和阅读数都上了新高度,有点人生巅峰的感觉呀.今天趁热打铁,聊聊我最喜欢的编程语言——Python. 为什么要说Python ...
- 机器学习经典算法具体解释及Python实现--K近邻(KNN)算法
(一)KNN依旧是一种监督学习算法 KNN(K Nearest Neighbors,K近邻 )算法是机器学习全部算法中理论最简单.最好理解的.KNN是一种基于实例的学习,通过计算新数据与训练数据特征值 ...
- Spark机器学习MLlib系列1(for python)--数据类型,向量,分布式矩阵,API
Spark机器学习MLlib系列1(for python)--数据类型,向量,分布式矩阵,API 关键词:Local vector,Labeled point,Local matrix,Distrib ...
- 机器学习之决策树(ID3)算法与Python实现
机器学习之决策树(ID3)算法与Python实现 机器学习中,决策树是一个预测模型:他代表的是对象属性与对象值之间的一种映射关系.树中每个节点表示某个对象,而每个分叉路径则代表的某个可能的属性值,而每 ...
随机推荐
- DataGrid 得到DataGridRow 和DataGridColumn
/* ---------------------------------------------------------- 文件名称:DataGridPlus.cs 作者:秦建辉 MSN:splash ...
- 4.ElasticSearch的基本api操作
1. ElasticSearch的Index 1. 索引初始化 在创建索引之前 对索引进行初始化操作 指定shards数量和replicas数量 curl -XPUT 'http://192.168. ...
- win10 uwp 右击浮出窗在点击位置
本文主要让MenuFlyout出现在我们右击位置. 我们一般使用的MenuFlyout写在前台,写在Button里面,但是可能我们的MenuFlyout显示的位置和我们想要的不一样. 通过使用后台写S ...
- 前端工程化grunt
1.grunt是什么? grunt是基于nodejs的前端构建工具.grunt用于解决前端开发的工程问题. 2.安装nodejs Grunt和所有grunt插件都是基于nodejs来运行的. 安装了n ...
- HashMap工作原理 和 HashTable
原文链接: Javarevisited 翻译: ImportNew.com - 唐小娟 译文链接: http://www.importnew.com/7099.html 你用过HashMap吗 譬如H ...
- 新型勒索软件Magniber正瞄准韩国、亚太地区开展攻击
近期,有国外研究人员发现了一种新型的勒索软件,并将其命名为Magniber,值得注意的是,这款勒索软只针对韩国及亚太地区的用户开展攻击.该勒索软件是基于Magnitude exploit kit(简称 ...
- Git相关操作四
1.克隆远程仓库 git clone remote_location clone_name remote_location为仓库地址,clone_name为要克隆到本地的仓库名称. 2.显示对应克隆地 ...
- 跨域资源共享CORS实现
问题描述: 本地已经实现的restful接口,在地址栏输入url:loaclhost:8080/admins即可得到预期的json字符串,在网页上显示如下: [{"id":1,&q ...
- hdu 4117 -- GRE Words (AC自动机+线段树)
题目链接 problem Recently George is preparing for the Graduate Record Examinations (GRE for short). Obvi ...
- quartz 定时任务
面试问到了,回答的不是很全面,丢人呀.研究过,用过的东西. 2年多没用,回忆一下: Quartz任务调度框架和Spring集成使用:定时执行一些任务 核心:调度器.任务和触发器. 调度器负责调度各个任 ...