Apache Spark Streaming的优点
Apache Spark Streaming的优点:
(1)优势及特点
1)多范式数据分析管道:能和 Spark 生态系统其他组件融合,实现交互查询和机器学习等多范式组合处理。
2)扩展性:可以运行在 100 个节点以上的集群,延迟可以控制在秒级。
3)容错性:使用 Spark 的 Lineage 及内存维护两份数据进行备份达到容错。 RDD通过 Lineage 记录下之前的操作,如果某节点在运行时出现故障,则可以通过冗余备份
数据在其他节点重新计算得到。
对于 Spark Streaming 来说,其 RDD 的 Lineage 关系如图 3 所示,图中的每个长椭圆形表示一个 RDD,椭圆中的每个圆形代表一个 RDD 中的一个分区(Partition),图中的每一列的多个 RDD 表示一个 DStream(图中有 3 个 DStream), t=1 和 t=2 代表不同的分片下的不同 RDD DAG。图中的每一个 RDD 都是通 过 Lineage 相 连 接 形 成 了 DAG, 由 于 SparkStreaming 输入数据可以来自于磁盘,例如 HDFS(通常由三份副本)也可以来自于网络(Spark Streaming 会将网络输入数据的每一个数据流复制两份到其他的机器)都能通过冗余数据及 Lineage 的重算机制保证容错性。所以 RDD 中任意的 Partition 出错,都可以并行地在其他机器上将缺失的 Partition 重算出来。
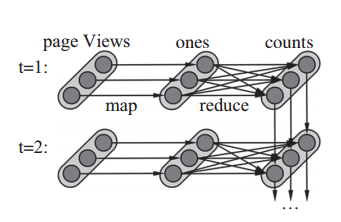
图 3 Spark Streaming 容错性
4)吞吐量大:将数据转换为 RDD,基于批处理的方式,提升数据处理吞吐量。图4 是 Berkeley 利用 WordCount 和 Grep 两个用例所做的测试。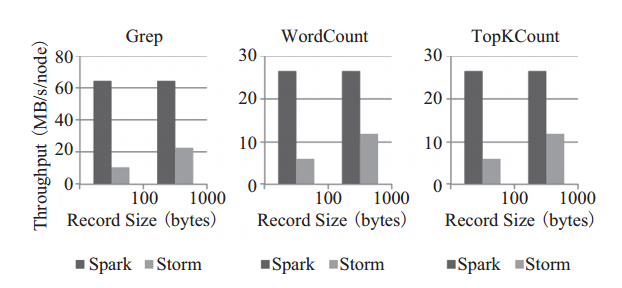
图4 Spark Streaming 与 Storm 吞吐量比较图
5)实时性: Spark Streaming 也是一个实时计算框架, Spark Streaming 能够满足除对实时性要求非常高(例如:高频实时交易)之外的所有流式准实时计算场景。目前Spark Streaming 最小的 Batch Size 的选取在 0.5 ~ 2s(对比: Storm 目前最小的延迟是100ms 左右)。
Apache Spark Streaming的优点的更多相关文章
- Offset Management For Apache Kafka With Apache Spark Streaming
An ingest pattern that we commonly see being adopted at Cloudera customers is Apache Spark Streaming ...
- Apache Spark Streaming的简介
Spark Streaming通过将流数据按指定时间片累积为RDD,然后将每个RDD进行批处理,进而实现大规模的流数据处理.其吞吐量能够超越现有主流流处理框架Storm,并提供丰富的API用于流数据计 ...
- Apache Spark Streaming的适用场景
使用场景: Spark Streaming 适合需要历史数据和实时数据结合进行分析的应用场景,对于实时性要求不是特别高的场景也能够胜任.
- Apache Kafka + Spark Streaming Integration
1.目标 为了构建实时应用程序,Apache Kafka - Spark Streaming Integration是最佳组合.因此,在本文中,我们将详细了解Kafka中Spark Streamin ...
- Apache Spark 2.2.0 中文文档 - Spark Streaming 编程指南 | ApacheCN
Spark Streaming 编程指南 概述 一个入门示例 基础概念 依赖 初始化 StreamingContext Discretized Streams (DStreams)(离散化流) Inp ...
- Real Time Credit Card Fraud Detection with Apache Spark and Event Streaming
https://mapr.com/blog/real-time-credit-card-fraud-detection-apache-spark-and-event-streaming/ Editor ...
- Apache Spark 2.2.0 中文文档 - Spark Streaming 编程指南
Spark Streaming 编程指南 概述 一个入门示例 基础概念 依赖 初始化 StreamingContext Discretized Streams (DStreams)(离散化流) Inp ...
- spark streaming 实时计算
spark streaming 开发实例 本文将分以下几部分 spark 开发环境配置 如何创建spark项目 编写streaming代码示例 如何调试 环境配置: spark 原生语言是scala, ...
- 【转】Spark Streaming和Kafka整合开发指南
基于Receivers的方法 这个方法使用了Receivers来接收数据.Receivers的实现使用到Kafka高层次的消费者API.对于所有的Receivers,接收到的数据将会保存在Spark ...
随机推荐
- 单交换机VLAN虚拟局域网划分
1.下载Cisco模拟器 Packet Tracer 是由Cisco公司发布的一个辅助学习工具,为学习CCNA课程的网络初学者去设计.配置.排除网络故障提供了网络模拟环境.学生可在软件的图形用户界面上 ...
- Android adb 常用技巧
1.在命令行管理模拟器设备(AVD) list:列出机器上所有已经安装的Android版本和AVD设备 list avd:列出机器上所有已经安装的AVD设备: list target:列出机器上所有已 ...
- hdu 1394 Minimum Inversion Number (裸树状数组 求逆序数 && 归并排序求逆序数)
题目链接 题意: 给一个n个数的序列a1, a2, ..., an ,这些数的范围是0-n-1, 可以把前面m个数移动到后面去,形成新序列:a1, a2, ..., an-1, an (where m ...
- Codeforces Round #243 (Div. 2) C. Sereja and Swaps(优先队列 暴力)
题目 题意:求任意连续序列的最大值,这个连续序列可以和其他的 值交换k次,求最大值 思路:暴力枚举所有的连续序列.没做对是因为 首先没有认真读题,没看清交换,然后,以为是dp或者贪心 用了一下贪心,各 ...
- 函数fsp_get_space_header
/**********************************************************************//** Gets a pointer to the sp ...
- HighCharts 饼图
@{ ViewBag.Title = "Index"; Layout = "~/Views/Shared/_Layout.cshtml"; } @section ...
- sqlserver 导入/导出Excel
--从Excel文件中,导入数据到SQL数据库中,很简单,直接用下面的语句: /*=========================================================== ...
- ios 编译openssl支持arm64(转)
最近在编译支付宝 快捷支付(无线) ios 端的时候发现demo不支持arm64.在网上找了下,看到客服说是openssl的库文件不支持arm64,于是自己编译了支持arm64的库文件,发现还是不行, ...
- noip2004提高组题解
这次有两道题以前已经做过了,所以分数什么的也没有意义了.发现这年的难度设置极不靠谱,前三题都比较简单,最后一题太难,不知道出题人怎么想的. 第一题:储蓄计划 模拟. 第二题:合并果子 贪心.每次选最小 ...
- 《C++ Primer 4th》读书笔记 第12章-类
原创文章,转载请注明出处:http://www.cnblogs.com/DayByDay/p/3936473.html