NLP文本匹配任务Text Matching 有监督训练:PointWise(单塔)、DSSM(双塔)、Sentence BERT(双塔)项目实践
NLP文本匹配任务Text Matching [有监督训练]:PointWise(单塔)、DSSM(双塔)、Sentence BERT(双塔)项目实践
0 背景介绍以及相关概念
本项目对3种常用的文本匹配的方法进行实现:PointWise(单塔)、DSSM(双塔)、Sentence BERT(双塔)。
文本匹配(Text Matching)是 NLP 下的一个分支,通常用于计算两个句子之间的相似程度,在推荐、推理等场景下都有着重要的作用。
举例来讲,今天我们有一堆评论数据,我们想要找到指定类别的评论数据,例如:
1. 为什么是开过的洗发水都流出来了,是用过的吗?是这样子包装的吗?
2. 喜欢折叠手机的我对这款手机情有独钟,简洁的外观设计非常符合当代年轻人的口味,给携带增添了一份愉悦。
3. 物流很快,但是到货时有的水果已经不新鲜了,坏掉了,不满意本次购物。
...
在这一堆评论中我们想找到跟「水果」相关的评论,那么第 3 条评论就应该被召回。这个问题可以被建模为文本分类对吧,通过训练一个文本分类模型也能达到同样的目的。
但,分类模型的主要问题是:分类标签是固定的。假如在训练的时候标签集合是「洗浴,电脑,水果」,今天再来一条「服饰」的评论,那么模型依旧只能在原有的标签集合里面进行推理,无论推到哪个都是错误的。因此,我们需要一个能够有一定自适应能力的模型,在加入一些新标签后不用重训模型也能很好的完成任务。
文本匹配目前比较常用的有两种结构:
单塔模型:准确率高,但计算速度慢。
双塔模型:计算速度快,准确率相对低一些。
下面我们对这两种方法分别进行介绍。
0.1 单塔模型
单塔模型顾名思义,是指在整个过程中只进行一次模型计算。这里的「塔」指的是进行「几次模型计算」,而不一定是「模型个数」,这个我们会放到双塔部分解释。在单塔模型下,我们需要把两句文本通过 [SEP] 进行拼接,将拼接好的数据喂给模型,通过 output 中的[CLS] token 做一个二分类任务。

单塔模型的 forward 部分长这样,完整源码在文末:
def __init__(self, encoder, dropout=None):
"""
init func.
Args:
encoder (transformers.AutoModel): backbone, 默认使用 ernie 3.0
dropout (float): dropout 比例
"""
super().__init__()
self.encoder = encoder
hidden_size = 768
self.dropout = nn.Dropout(dropout if dropout is not None else 0.1)
self.classifier = nn.Linear(768, 2)
def forward(self,
input_ids,
token_type_ids,
position_ids=None,
attention_mask=None) -> torch.tensor:
"""
Foward 函数,输入匹配好的pair对,返回二维向量(相似/不相似)。
Args:
input_ids (torch.LongTensor): (batch, seq_len)
token_type_ids (torch.LongTensor): (batch, seq_len)
position_ids (torch.LongTensor): (batch, seq_len)
attention_mask (torch.LongTensor): (batch, seq_len)
Returns:
torch.tensor: (batch, 2)
"""
pooled_embedding = self.encoder(
input_ids=input_ids,
token_type_ids=token_type_ids,
position_ids=position_ids,
attention_mask=attention_mask
)["pooler_output"] # (batch, hidden_size)
pooled_embedding = self.dropout(pooled_embedding) # (batch, hidden_size)
logits = self.classifier(pooled_embedding) # (batch, 2)
return logits
单塔模型的优势在于准确率较高,但缺点在于:计算慢。
- 为什么慢呢?
举例来讲,如果今天我们有三个类别「电脑、水果、洗浴」,那我们就需要将一句话跟每个类别都做一次拼接,并喂给模型去做推理:
水果[SEP]苹果不是很新鲜,不满意这次购物[SEP]
电脑[SEP]苹果不是很新鲜,不满意这次购物[SEP]
洗浴[SEP]苹果不是很新鲜,不满意这次购物[SEP]
那如果类别数目到达成百上千时,就需要拼接上千次,为了判断一个样本就需要过上次模型,而大模型的计算通常来讲是非常耗时的,这就导致了在类别数目很大的情况下,单塔模型的效率往往无法满足人们的需求。
0.2 双塔模型
单塔模型的劣势很明显,有多少类别就需要算多少次。但事实上,这些类别都是不会变的,唯一变的只有新的评论数据。所以我们能不能实现将这些不会变的「类别信息」「提前计算」存下来,只计算那些没有见过的「评论数据」呢?这就是双塔模型的思想。双塔模型的「双塔」含义就是:两次模型计算。即,类别特征计算一次,评论特征计算一次。
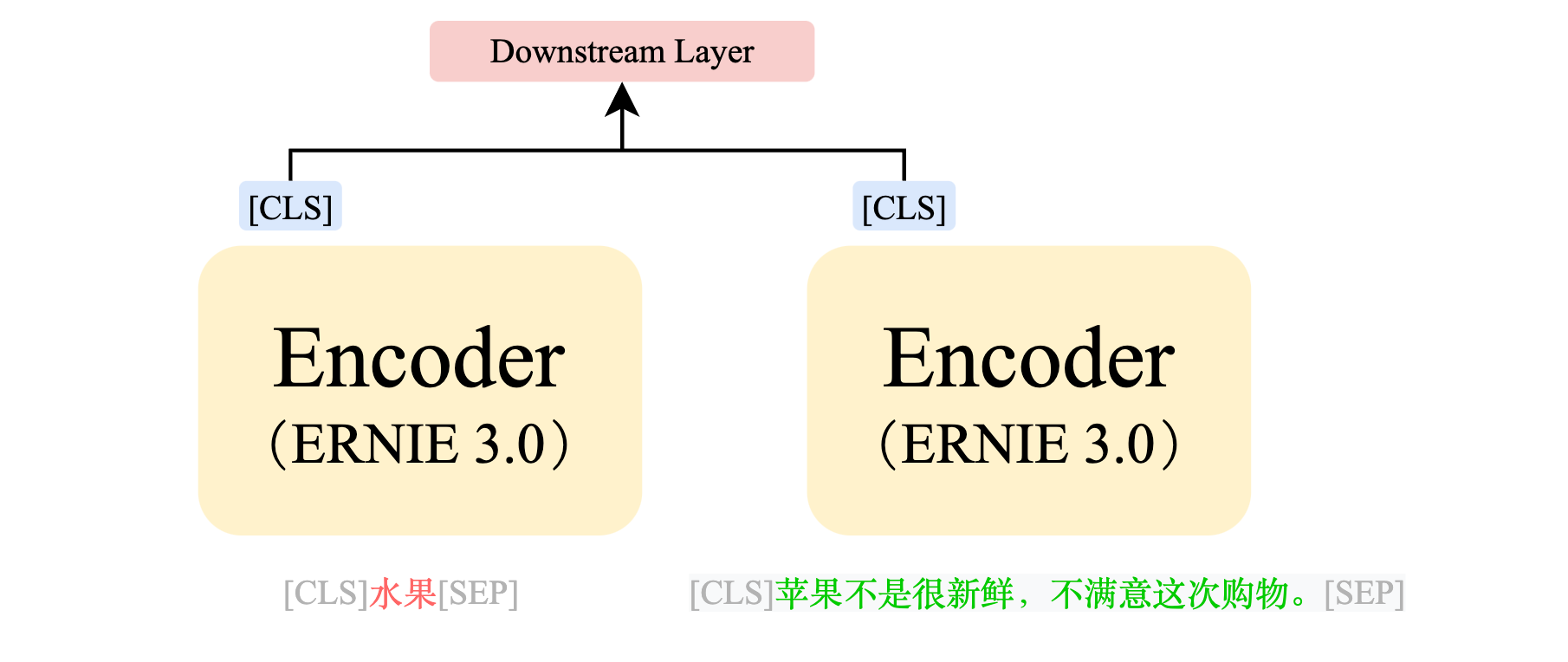
通过上图可以看到,「类别」和「评论」不再是拼接在一起喂给模型,而是单独喂给模型,并分别得到各自的 embedding 向量,再进行后续的计算。而上图中左右两个两个模型可以使用同一个模型(这种方式叫:同构模型),也可以用两个不同的模型(这种方式叫:异构模型)。因此「双塔」并不一定代表存在两个模型,而是代表需要需要进行两次模型计算。
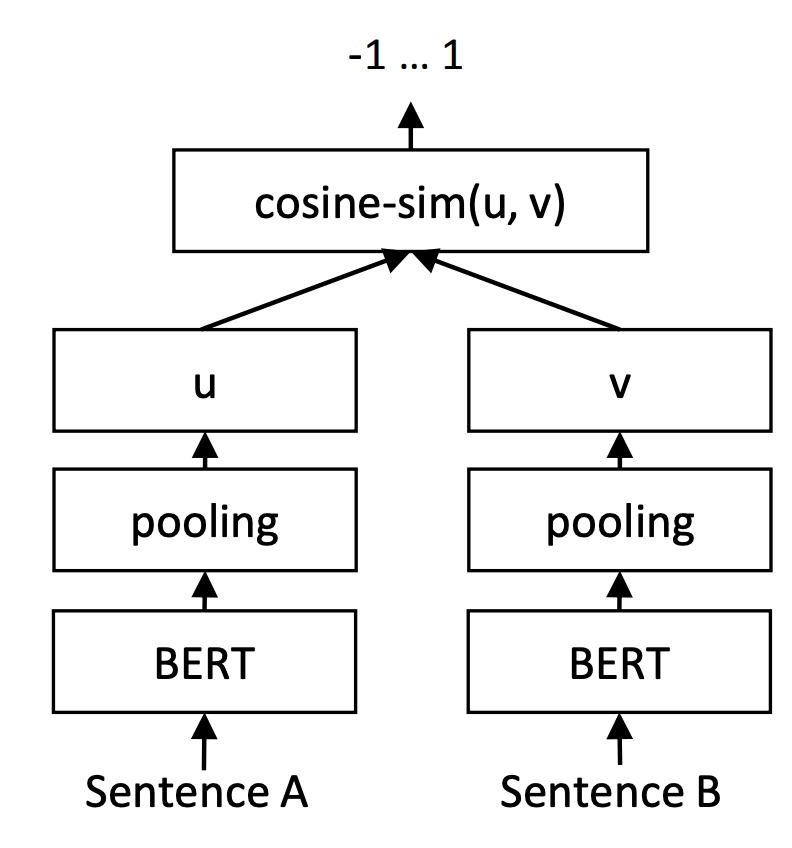
0.2.1 DSSM(Deep Structured Semantic Models,深度结构化语义模型)
Paper Reference: https://posenhuang.github.io/papers/cikm2013_DSSM_fullversion.pdf
DSSM 是一篇比较早期的 paper,我们主要借鉴其通过 embedding 之间的余弦相似度进行召回排序的思想。我们分别将「类别」和「评论」文本过一遍模型,并得到两段文本的 embedding。将匹配的 pair 之间的余弦相似度 label 置为 1,不匹配的 pair 之间余弦相似度 label 置为 0。
Note: 余弦相似度的取值范围是 [-1, 1],但为了方便我将 label 置为 0 并用 MSE 去训练,也能取得不错的效果。
训练数据集长这样,匹配 pair 标签为 1,不匹配为 0:
蒙牛 不错还好挺不错 0
蒙牛 我喜欢demom制造的蒙牛奶 1
衣服 裤子太差了,刚穿一次屁股就起毛了。 1
...
实现中有两个关键函数:获得句子的 embedding 函数(用于推理)、获得句子对的余弦相似度(用于训练):
def forward(
self,
input_ids: torch.tensor,
token_type_ids: torch.tensor,
attention_mask: torch.tensor
) -> torch.tensor:
"""
forward 函数,输入单句子,获得单句子的embedding。
Args:
input_ids (torch.LongTensor): (batch, seq_len)
token_type_ids (torch.LongTensor): (batch, seq_len)
attention_mask (torch.LongTensor): (batch, seq_len)
Returns:
torch.tensor: embedding -> (batch, hidden_size)
"""
embedding = self.encoder(
input_ids=input_ids,
token_type_ids=token_type_ids,
attention_mask=attention_mask
)["pooler_output"] # (batch, hidden_size)
return embedding
def get_similarity(
self,
query_input_ids: torch.tensor,
query_token_type_ids: torch.tensor,
query_attention_mask: torch.tensor,
doc_input_ids: torch.tensor,
doc_token_type_ids: torch.tensor,
doc_attention_mask: torch.tensor
) -> torch.tensor:
"""
输入query和doc的向量,返回query和doc两个向量的余弦相似度。
Args:
query_input_ids (torch.LongTensor): (batch, seq_len)
query_token_type_ids (torch.LongTensor): (batch, seq_len)
query_attention_mask (torch.LongTensor): (batch, seq_len)
doc_input_ids (torch.LongTensor): (batch, seq_len)
doc_token_type_ids (torch.LongTensor): (batch, seq_len)
doc_attention_mask (torch.LongTensor): (batch, seq_len)
Returns:
torch.tensor: (batch, 1)
"""
query_embedding = self.encoder(
input_ids=query_input_ids,
token_type_ids=query_token_type_ids,
attention_mask=query_attention_mask
)["pooler_output"] # (batch, hidden_size)
query_embedding = self.dropout(query_embedding)
doc_embedding = self.encoder(
input_ids=doc_input_ids,
token_type_ids=doc_token_type_ids,
attention_mask=doc_attention_mask
)["pooler_output"] # (batch, hidden_size)
doc_embedding = self.dropout(doc_embedding)
similarity = nn.functional.cosine_similarity(query_embedding, doc_embedding)
return similarity
0.2.2 Sentence Transformer
Paper Reference:https://arxiv.org/pdf/1908.10084.pdf
Sentence Transformer 也是一个双塔模型,只是在训练时不直接对两个句子的 embedding 算余弦相似度,而是将这两个 embedding 和 embedding 之间的差向量进行拼接,将这三个向量拼好后喂给一个判别层做二分类任务。
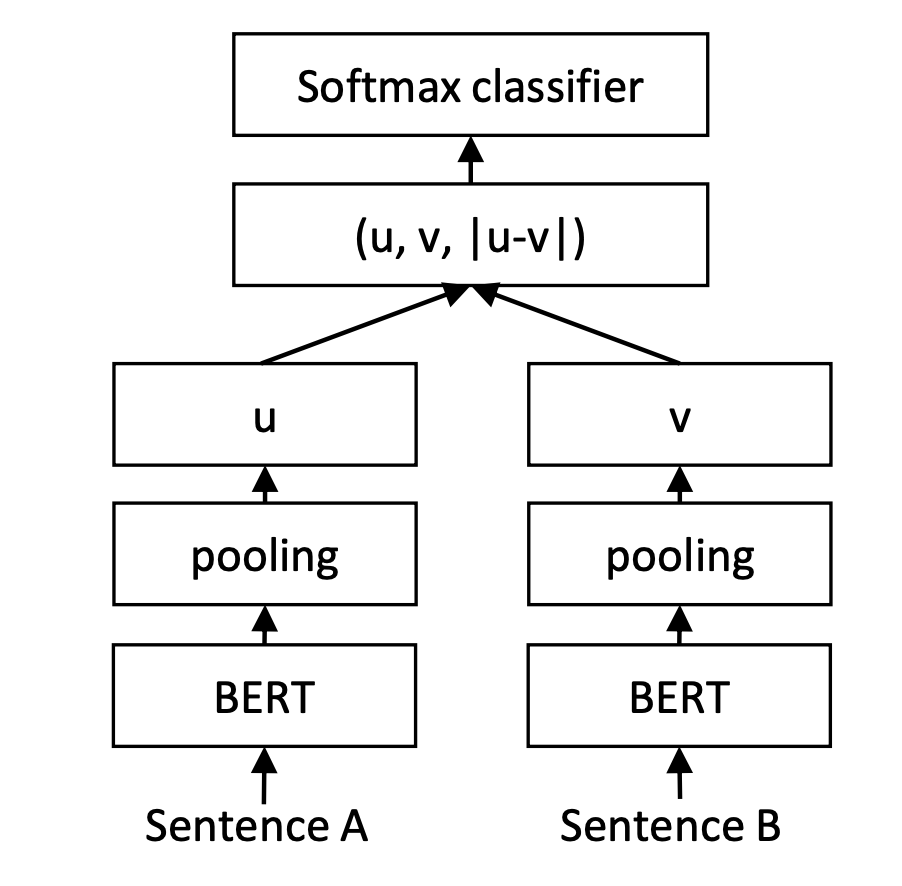
原 paper 中在 inference 的时候不再使用训练架构,而是采用了余弦相似度的方法做召回。但我在实现的时候在推理部分仍然沿用了训练的模型架构,原因是想抹除结构不一致的 gap,并且训练层也只是多了一层 Linear 层,在推理的时候也不至于消耗过多的时间。Sentence Transformer 在推理时需要同时传入「当前评论信息」以及事先计算好的「所有类别 embedding」,如下:
def forward(
self,
query_input_ids: torch.tensor,
query_token_type_ids: torch.tensor,
query_attention_mask: torch.tensor,
doc_embeddings: torch.tensor,
) -> torch.tensor:
"""
forward 函数,输入query句子和doc_embedding向量,将query句子过一遍模型得到
query embedding再和doc_embedding做二分类。
Args:
input_ids (torch.LongTensor): (batch, seq_len)
token_type_ids (torch.LongTensor): (batch, seq_len)
attention_mask (torch.LongTensor): (batch, seq_len)
doc_embedding (torch.LongTensor): 所有需要匹配的doc_embedding -> (batch, doc_embedding_numbers, hidden_size)
Returns:
torch.tensor: embedding_match_logits -> (batch, doc_embedding_numbers, 2)
"""
query_embedding = self.encoder(
input_ids=query_input_ids,
token_type_ids=query_token_type_ids,
attention_mask=query_attention_mask
)["last_hidden_state"] # (batch, seq_len, hidden_size)
query_attention_mask = torch.unsqueeze(query_attention_mask, dim=-1) # (batch, seq_len, 1)
query_embedding = query_embedding * query_attention_mask # (batch, seq_len, hidden_size)
query_sum_embedding = torch.sum(query_embedding, dim=1) # (batch, hidden_size)
query_sum_mask = torch.sum(query_attention_mask, dim=1) # (batch, 1)
query_mean = query_sum_embedding / query_sum_mask # (batch, hidden_size)
query_mean = query_mean.unsqueeze(dim=1).repeat(1, doc_embeddings.size()[1], 1) # (batch, doc_embedding_numbers, hidden_size)
sub = torch.abs(torch.subtract(query_mean, doc_embeddings)) # (batch, doc_embedding_numbers, hidden_size)
concat = torch.cat([query_mean, doc_embeddings, sub], dim=-1) # (batch, doc_embedding_numbers, hidden_size * 3)
logits = self.classifier(concat) # (batch, doc_embedding_numbers, 2)
return logits
1. 环境安装
本项目基于 pytorch + transformers 实现,运行前请安装相关依赖包:
pip install -r ../../requirements.txt
torch
transformers==4.22.1
datasets==2.4.0
evaluate==0.2.2
matplotlib==3.6.0
rich==12.5.1
scikit-learn==1.1.2
requests==2.28.1
2. 数据集准备
项目中提供了一部分示例数据,我们使用「商品评论」和「商品类别」来进行文本匹配任务,数据在 data/comment_classify 。
若想使用自定义数据训练,只需要仿照示例数据构建数据集即可:
衣服:指穿在身上遮体御寒并起美化作用的物品。 为什么是开过的洗发水都流出来了、是用过的吗?是这样子包装的吗? 0
衣服:指穿在身上遮体御寒并起美化作用的物品。 开始买回来大很多 后来换了回来又小了 号码区别太不正规 建议各位谨慎 1
...
每一行用 \t 分隔符分开,第一部分部分为商品类型(text1),中间部分为商品评论(text2),最后一部分为商品评论和商品类型是否一致(label)。
3. 有监督-模型训练
3.1 PointWise(单塔)
3.1.1 模型训练
修改训练脚本 train_pointwise.sh 里的对应参数, 开启模型训练:
python train_pointwise.py \
--model "nghuyong/ernie-3.0-base-zh" \ # backbone
--train_path "data/comment_classify/train.txt" \ # 训练集
--dev_path "data/comment_classify/dev.txt" \ #验证集
--save_dir "checkpoints/comment_classify" \ # 训练模型存放地址
--img_log_dir "logs/comment_classify" \ # loss曲线图保存位置
--img_log_name "ERNIE-PointWise" \ # loss曲线图保存文件夹
--batch_size 8 \
--max_seq_len 128 \
--valid_steps 50 \
--logging_steps 10 \
--num_train_epochs 10 \
--device "cuda:0"
正确开启训练后,终端会打印以下信息:
...
global step 10, epoch: 1, loss: 0.77517, speed: 3.43 step/s
global step 20, epoch: 1, loss: 0.67356, speed: 4.15 step/s
global step 30, epoch: 1, loss: 0.53567, speed: 4.15 step/s
global step 40, epoch: 1, loss: 0.47579, speed: 4.15 step/s
global step 50, epoch: 2, loss: 0.43162, speed: 4.41 step/s
Evaluation precision: 0.88571, recall: 0.87736, F1: 0.88152
best F1 performence has been updated: 0.00000 --> 0.88152
global step 60, epoch: 2, loss: 0.40301, speed: 4.08 step/s
global step 70, epoch: 2, loss: 0.37792, speed: 4.03 step/s
global step 80, epoch: 2, loss: 0.35343, speed: 4.04 step/s
global step 90, epoch: 2, loss: 0.33623, speed: 4.23 step/s
global step 100, epoch: 3, loss: 0.31319, speed: 4.01 step/s
Evaluation precision: 0.96970, recall: 0.90566, F1: 0.93659
best F1 performence has been updated: 0.88152 --> 0.93659
...
在 logs/comment_classify 文件下将会保存训练曲线图:
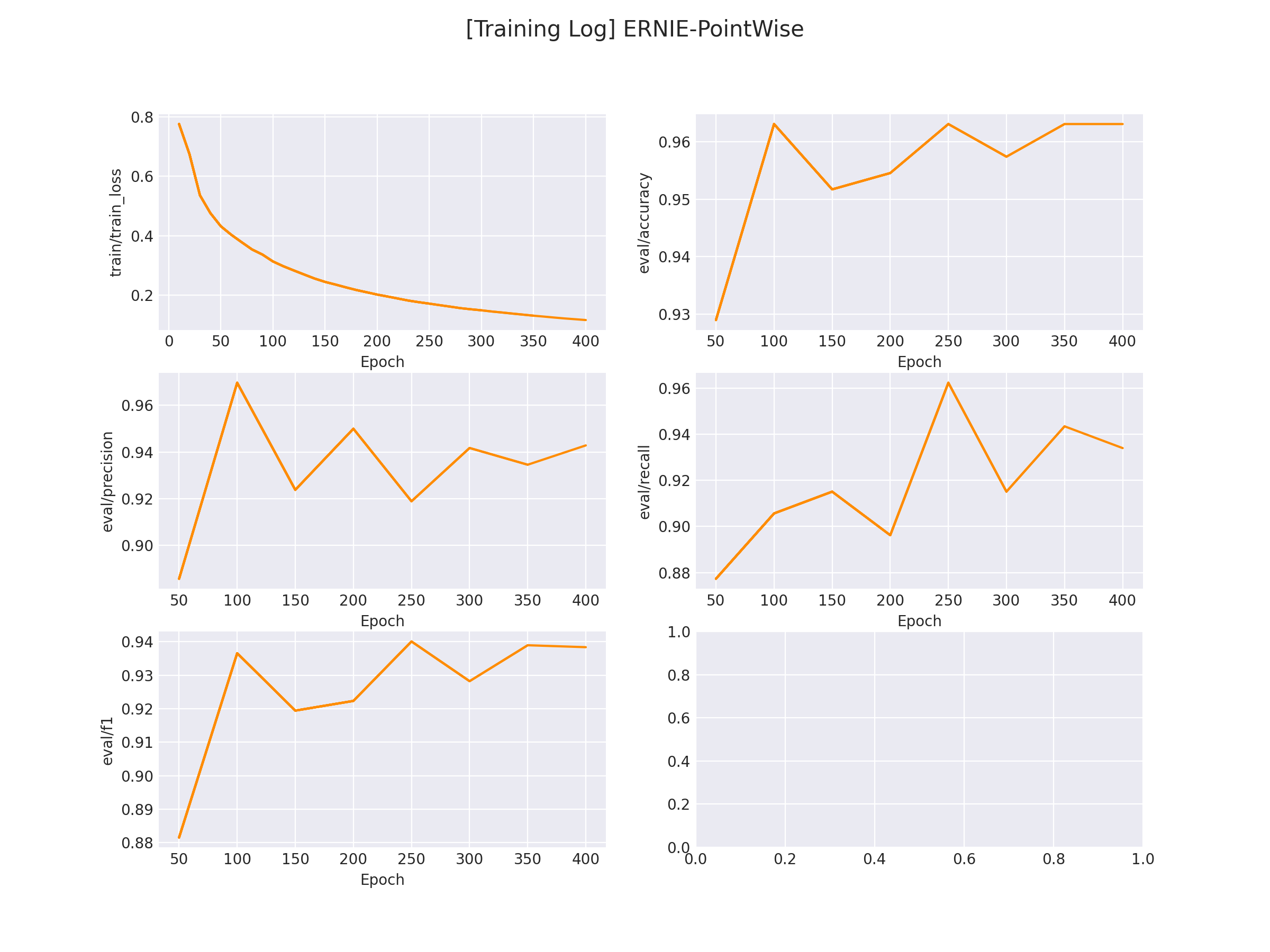
3.1.2 模型推理
完成模型训练后,运行 inference_pointwise.py 以加载训练好的模型并应用:
...
test_inference(
'手机:一种可以在较广范围内使用的便携式电话终端。', # 第一句话
'味道非常好,京东送货速度也非常快,特别满意。', # 第二句话
max_seq_len=128
)
...
运行推理程序:
python inference_pointwise.py
得到以下推理结果:
tensor([[ 1.8477, -2.0484]], device='cuda:0') # 两句话不相似(0)的概率更大
3.2 DSSM(双塔)
3.2.1 模型训练
修改训练脚本 train_dssm.sh 里的对应参数, 开启模型训练:
python train_dssm.py \
--model "nghuyong/ernie-3.0-base-zh" \
--train_path "data/comment_classify/train.txt" \
--dev_path "data/comment_classify/dev.txt" \
--save_dir "checkpoints/comment_classify/dssm" \
--img_log_dir "logs/comment_classify" \
--img_log_name "ERNIE-DSSM" \
--batch_size 8 \
--max_seq_len 256 \
--valid_steps 50 \
--logging_steps 10 \
--num_train_epochs 10 \
--device "cuda:0"
正确开启训练后,终端会打印以下信息:
...
global step 0, epoch: 1, loss: 0.62319, speed: 15.16 step/s
Evaluation precision: 0.29912, recall: 0.96226, F1: 0.45638
best F1 performence has been updated: 0.00000 --> 0.45638
global step 10, epoch: 1, loss: 0.40931, speed: 3.64 step/s
global step 20, epoch: 1, loss: 0.36969, speed: 3.69 step/s
global step 30, epoch: 1, loss: 0.33927, speed: 3.69 step/s
global step 40, epoch: 1, loss: 0.31732, speed: 3.70 step/s
global step 50, epoch: 1, loss: 0.30996, speed: 3.68 step/s
...
在 logs/comment_classify 文件下将会保存训练曲线图:
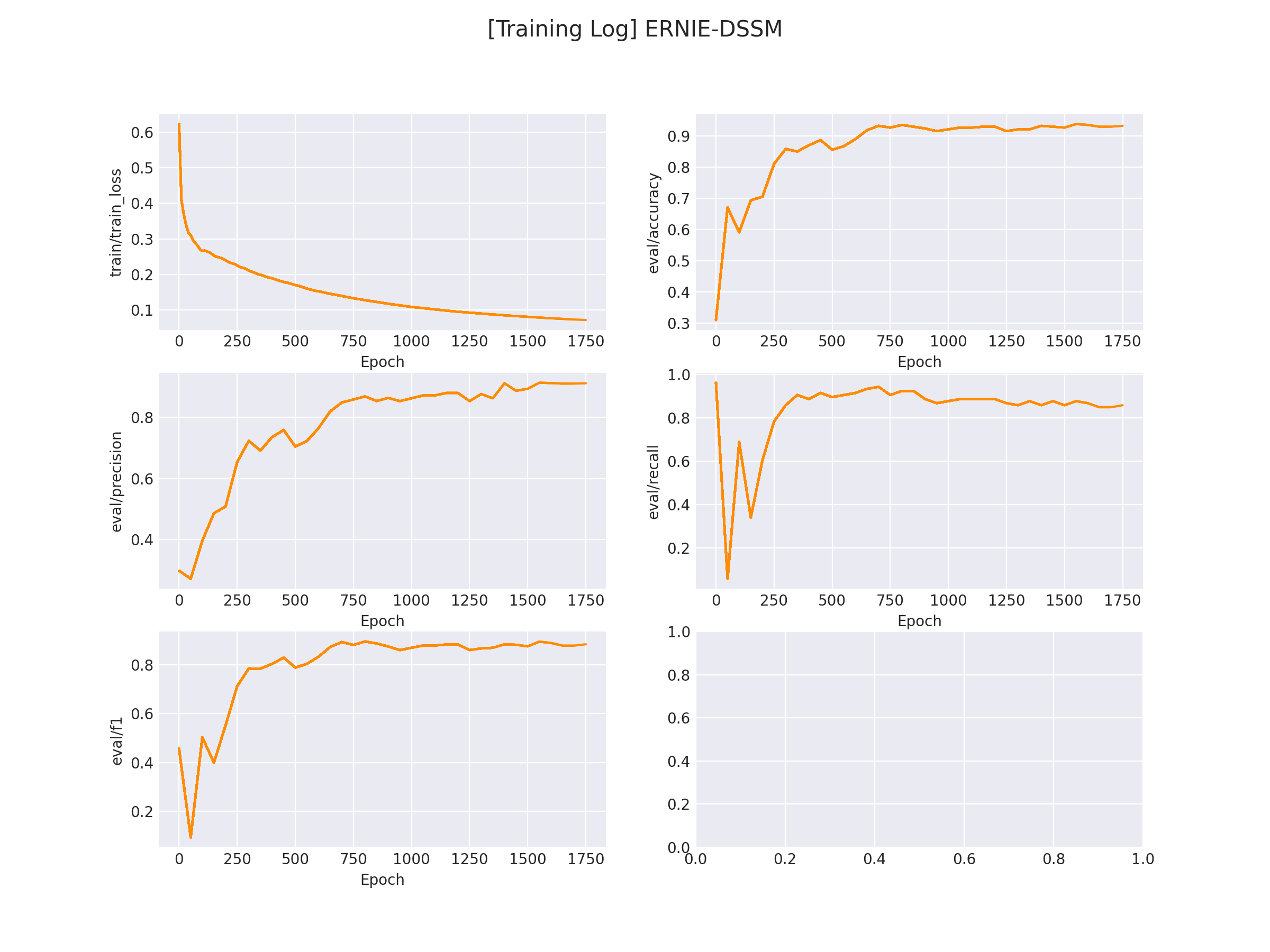
3.2.2 模型推理
和单塔模型不一样的是,双塔模型可以事先计算所有候选类别的Embedding,当新来一个句子时,只需计算新句子的Embedding,并通过余弦相似度找到最优解即可。
因此,在推理之前,我们需要提前计算所有类别的Embedding并保存。
类别Embedding计算
运行 get_embedding.py 文件以计算对应类别embedding并存放到本地:
...
text_file = 'data/comment_classify/types_desc.txt' # 候选文本存放地址
output_file = 'embeddings/comment_classify/dssm_type_embeddings.json' # embedding存放地址
device = 'cuda:0' # 指定GPU设备
model_type = 'dssm' # 使用DSSM还是Sentence Transformer
saved_model_path = './checkpoints/comment_classify/dssm/model_best/' # 训练模型存放地址
tokenizer = AutoTokenizer.from_pretrained(saved_model_path)
model = torch.load(os.path.join(saved_model_path, 'model.pt'))
model.to(device).eval()
...
其中,所有需要预先计算的内容都存放在 types_desc.txt 文件中。
文件用 \t 分隔,分别代表 类别id、类别名称、类别描述:
0 水果 指多汁且主要味觉为甜味和酸味,可食用的植物果实。
1 洗浴 洗浴用品。
2 平板 也叫便携式电脑,是一种小型、方便携带的个人电脑,以触摸屏作为基本的输入设备。
...
执行 python get_embeddings.py 命令后,会在代码中设置的embedding存放地址中找到对应的embedding文件:
{
"0": {"label": "水果", "text": "水果:指多汁且主要味觉为甜味和酸味,可食用的植物果实。", "embedding": [0.3363891839981079, -0.8757723569869995, -0.4140555262565613, 0.8288457989692688, -0.8255823850631714, 0.9906797409057617, -0.9985526204109192, 0.9907819032669067, -0.9326567649841309, -0.9372553825378418, 0.11966298520565033, -0.7452883720397949,...]},
"1": ...,
...
}
模型推理
完成预计算后,接下来就可以开始推理了。
我们构建一条新评论:这个破笔记本卡的不要不要的,差评。
运行 python inference_dssm.py,得到下面结果:
[
('平板', 0.9515482187271118),
('电脑', 0.8216977119445801),
('洗浴', 0.12220608443021774),
('衣服', 0.1199738010764122),
('手机', 0.07764233648777008),
('酒店', 0.044791921973228455),
('水果', -0.050112202763557434),
('电器', -0.07554933428764343),
('书籍', -0.08481660485267639),
('蒙牛', -0.16164332628250122)
]
函数将输出(类别,余弦相似度)的二元组,并按照相似度做倒排(相似度取值范围:[-1, 1])。
3.3 Sentence Transformer(双塔)
3.3.1 模型训练
修改训练脚本 train_sentence_transformer.sh 里的对应参数, 开启模型训练:
python train_sentence_transformer.py \
--model "nghuyong/ernie-3.0-base-zh" \
--train_path "data/comment_classify/train.txt" \
--dev_path "data/comment_classify/dev.txt" \
--save_dir "checkpoints/comment_classify/sentence_transformer" \
--img_log_dir "logs/comment_classify" \
--img_log_name "Sentence-Ernie" \
--batch_size 8 \
--max_seq_len 256 \
--valid_steps 50 \
--logging_steps 10 \
--num_train_epochs 10 \
--device "cuda:0"
正确开启训练后,终端会打印以下信息:
...
Evaluation precision: 0.81928, recall: 0.64151, F1: 0.71958
best F1 performence has been updated: 0.46120 --> 0.71958
global step 260, epoch: 2, loss: 0.58730, speed: 3.53 step/s
global step 270, epoch: 2, loss: 0.58171, speed: 3.55 step/s
global step 280, epoch: 2, loss: 0.57529, speed: 3.48 step/s
global step 290, epoch: 2, loss: 0.56687, speed: 3.55 step/s
global step 300, epoch: 2, loss: 0.56033, speed: 3.55 step/s
...
在 logs/comment_classify 文件下将会保存训练曲线图:
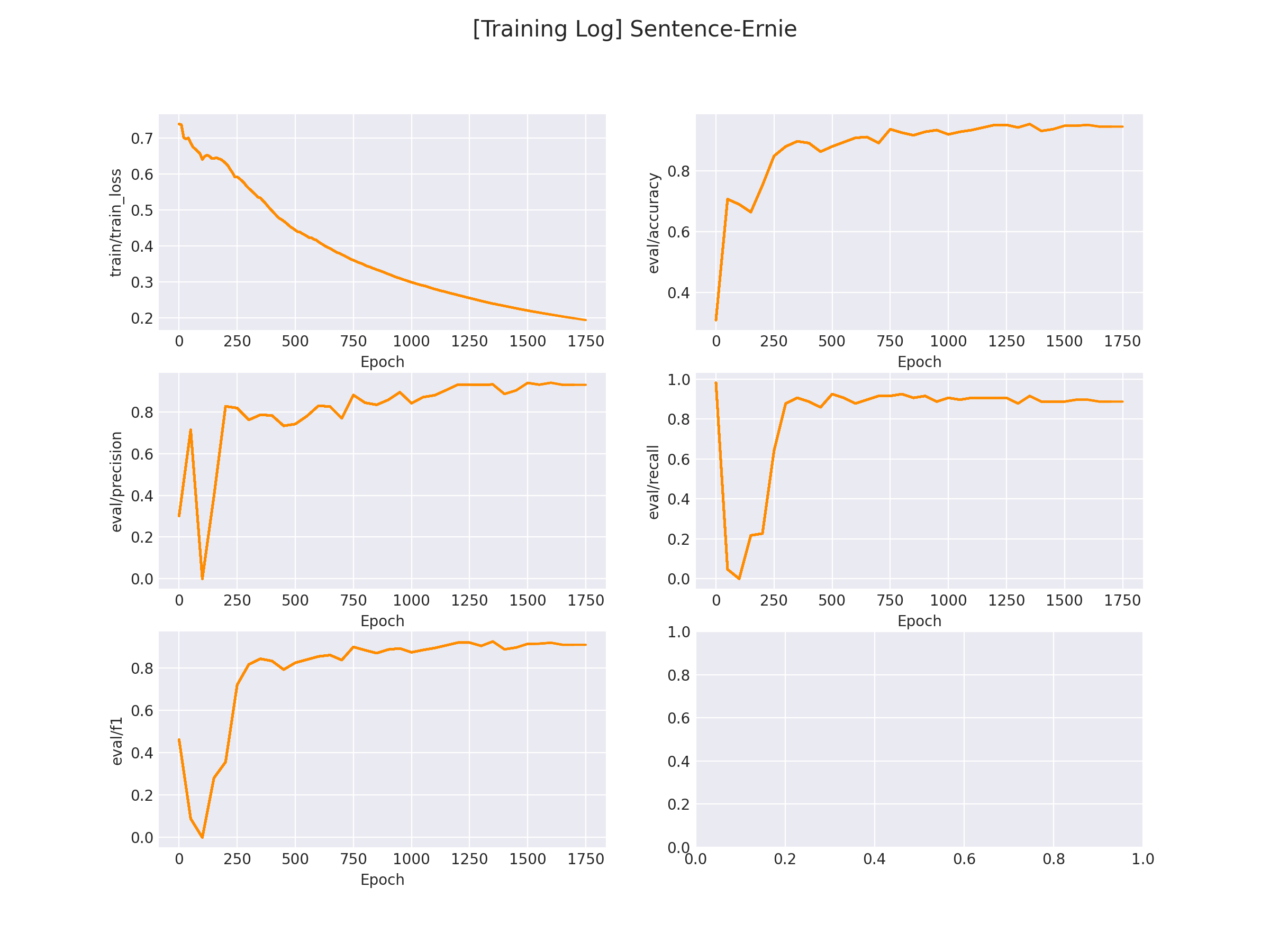
3.2.2 模型推理
Sentence Transformer 同样也是双塔模型,因此我们需要事先计算所有候选文本的embedding值。
类别Embedding计算
运行 get_embedding.py 文件以计算对应类别embedding并存放到本地:
...
text_file = 'data/comment_classify/types_desc.txt' # 候选文本存放地址
output_file = 'embeddings/comment_classify/sentence_transformer_type_embeddings.json' # embedding存放地址
device = 'cuda:0' # 指定GPU设备
model_type = 'sentence_transformer' # 使用DSSM还是Sentence Transformer
saved_model_path = './checkpoints/comment_classify/sentence_transformer/model_best/' # 训练模型存放地址
tokenizer = AutoTokenizer.from_pretrained(saved_model_path)
model = torch.load(os.path.join(saved_model_path, 'model.pt'))
model.to(device).eval()
...
其中,所有需要预先计算的内容都存放在 types_desc.txt 文件中。
文件用 \t 分隔,分别代表 类别id、类别名称、类别描述:
0 水果 指多汁且主要味觉为甜味和酸味,可食用的植物果实。
1 洗浴 洗浴用品。
2 平板 也叫便携式电脑,是一种小型、方便携带的个人电脑,以触摸屏作为基本的输入设备。
...
执行 python get_embeddings.py 命令后,会在代码中设置的embedding存放地址中找到对应的embedding文件:
{
"0": {"label": "水果", "text": "水果:指多汁且主要味觉为甜味和酸味,可食用的植物果实。", "embedding": [0.32447007298469543, -1.0908259153366089, -0.14340722560882568, 0.058471400290727615, -0.33798110485076904, -0.050156619399785995, 0.041511114686727524, 0.671889066696167, 0.2313404232263565, 1.3200652599334717, -1.10829496383667, 0.4710233509540558, -0.08577515184879303, -0.41730815172195435, -0.1956728845834732, 0.05548520386219025, ...]}
"1": ...,
...
}
模型推理
完成预计算后,接下来就可以开始推理了。
我们构建一条新评论:这个破笔记本卡的不要不要的,差评。
运行 python inference_sentence_transformer.py,函数会输出所有类别里「匹配通过」的类别及其匹配值,得到下面结果:
Used 0.5233056545257568s.
[
('平板', 1.136274814605713),
('电脑', 0.8851938247680664)
]
函数将输出(匹配通过的类别,匹配值)的二元组,并按照匹配值(越大则越匹配)做倒排。
参考链接:https://github.com/HarderThenHarder/transformers_tasks/blob/main/text_matching/supervised
更多优质内容请关注公号:汀丶人工智能;会提供一些相关的资源和优质文章,免费获取阅读。

NLP文本匹配任务Text Matching 有监督训练:PointWise(单塔)、DSSM(双塔)、Sentence BERT(双塔)项目实践的更多相关文章
- 跨模态语义关联对齐检索-图像文本匹配(Image-Text Matching)
论文介绍:Negative-Aware Attention Framework for Image-Text Matching (基于负感知注意力的图文匹配,CVPR2022) 代码主页:https: ...
- text matching(文本匹配) 相关资料总结
最近工作上需要做句子语义去重相关的工作,本质上这是属于NLP中text matching(文本匹配)相关的内容.因此我花了一些时间整理了一些关于这个方向的资料,整理如下(也许会持续更新): BiMPM ...
- 斯坦福NLP课程 | 第15讲 - NLP文本生成任务
作者:韩信子@ShowMeAI,路遥@ShowMeAI,奇异果@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www. ...
- fastText、TextCNN、TextRNN……这里有一套NLP文本分类深度学习方法库供你选择
https://mp.weixin.qq.com/s/_xILvfEMx3URcB-5C8vfTw 这个库的目的是探索用深度学习进行NLP文本分类的方法. 它具有文本分类的各种基准模型,还支持多标签分 ...
- NLP文本分类
引言 其实最近挺纠结的,有一点点焦虑,因为自己一直都期望往自然语言处理的方向发展,梦想成为一名NLP算法工程师,也正是我喜欢的事,而不是为了生存而工作.我觉得这也是我这辈子为数不多的剩下的可以自己去追 ...
- NLP文本分类方法汇总
模型: FastText TextCNN TextRNN RCNN 分层注意网络(Hierarchical Attention Network) 具有注意的seq2seq模型(seq2seq with ...
- [CSS]文本属性(Text)
CSS 文本属性(Text) 属性 描述 CSS color 设置文本的颜色. 1 direction 规定文本的方向 / 书写方向. 2 letter-spacing 设置字符间距. 1 lin ...
- NLP文本相似度
NLP文本相似度 相似度 相似度度量:计算个体间相似程度 相似度值越小,距离越大,相似度值越大,距离越小 最常用--余弦相似度: 一个向量空间中两个向量夹角的余弦值作为衡量两个个体之间差异的大小 余 ...
- NLP 文本预处理
1.不同类别文本量统计,类别不平衡差异 2.文本长度统计 3.文本处理,比如文本语料中简体与繁体共存,这会加大模型的学习难度.因此,他们对数据进行繁体转简体的处理. 同时,过滤掉了对分类没有任何作用的 ...
- [Alg] 文本匹配-单模匹配与多模匹配
实际场景: 网站的用户发了一些帖子S1, S2,...,网站就要审核一下这些帖子里有没有敏感词. 1. 如果网站想查一下帖子里有没有一个敏感词P,这个文本匹配要怎么做更快? 2. 如果网站想查一下帖子 ...
随机推荐
- 页面滚动,打包,appium工具
''' 移动到元素element对象的"底端",与当前窗口的"底部"对齐: 我们需要将页面下拉一个滑轮 ''' for y in range(3): js = ...
- PS组件相关BAPI
一.新增组件BAPI "-----------------------------------------@斌将军-------------------------------------- ...
- JSP常见错误以及解决方案
原作者为 RioTian@cnblogs, 本作品采用 CC 4.0 BY 进行许可,转载请注明出处. 本节我们分析一下常见的 JSP 错误信息,并给出解决方案.这些错误在实际开发中会经常遇到,所以有 ...
- OpenSCA技术原理之npm依赖解析
本文主要介绍基于npm包管理器的组件成分解析原理. npm 介绍 npm(全称Node Package Manager)是Node.js的预设软件包管理器. npm的依赖管理文件是package.js ...
- java获取部门树的方法实例
开发中如何获取一个树结构是非常常见的需求,本示例演示一下该功能如何实现. 1.数据准备(mysql) CREATE TABLE `dept` ( `dept_id` int NOT NULL AUTO ...
- vue学习笔记 十、状态管理基础结构
系列导航 vue学习笔记 一.环境搭建 vue学习笔记 二.环境搭建+项目创建 vue学习笔记 三.文件和目录结构 vue学习笔记 四.定义组件(组件基本结构) vue学习笔记 五.创建子组件实例 v ...
- 前端规范:eslint与prettier使用(干货)
https://blog.csdn.net/weixin_45077178/article/details/107226551 视频教程: https://xdclass.net/#/dplayer? ...
- vue-asome-swiper
- 基于 SpringBoot + Vue3.2 + Element Plus 的后台管理系统
简介 TANSCI 基于 SpringBoot + Vue3.2 + Element Plus 的后台管理系统. 包含基础模块:菜单管理.角色管理.组织管理.用户管理.字典管理.日志管理(操作日志.异 ...
- DFT Architecture
Design For Test 在实际生产过程中产生的physical defect是导致芯片功能出错的根本原因 如何根据结构产生测试向量呢?主要考虑physical defect physical ...